Смещение против дисперсии в машинном обучении
В этой статье мы узнаем, что такое смещение и дисперсия для модели машинного обучения и каким должно быть их оптимальное состояние.
Есть разные способы оценить модель машинного обучения. Мы можем использовать MSE (среднеквадратичную ошибку) для регрессии; Точность, отзыв и ROC (приемник характеристик) для задачи классификации наряду с абсолютной ошибкой. Точно так же смещение и дисперсия помогают нам в настройке параметров и выборе модели, лучше подходящей для нескольких построенных.
Смещение - это один из типов ошибок, который возникает из-за неправильных предположений о данных, таких как предположение, что данные являются линейными, когда на самом деле данные следуют за сложной функцией. С другой стороны, появляется высокая чувствительность к вариациям обучающих данных. Это тоже один из типов ошибок, поскольку мы хотим сделать нашу модель устойчивой к шуму.
Прежде чем перейти к математическим определениям, нам нужно знать о случайных величинах и функциях. Скажем, f (x) - это функция, за которой следуют наши данные. Мы построим несколько моделей, которые можно обозначить как 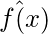 . Каждая точка этой функции представляет собой случайную величину, имеющую количество значений, равное количеству моделей. Чтобы правильно аппроксимировать истинную функцию f (x), мы берем математическое ожидание
. Каждая точка этой функции представляет собой случайную величину, имеющую количество значений, равное количеству моделей. Чтобы правильно аппроксимировать истинную функцию f (x), мы берем математическое ожидание 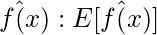 .
.
Предвзятость :Разница:
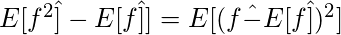
Давайте посмотрим, насколько важны оба этих термина.
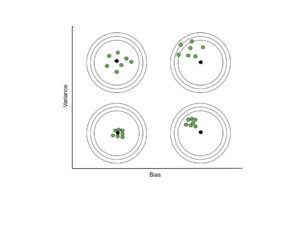
Иллюстрация смещения и дисперсии
Эти изображения говорят сами за себя. Тем не менее, мы поговорим о том, что следует отметить. Когда смещение велико, фокус группы прогнозируемой функции находится далеко от истинной функции. Тогда как при большой дисперсии функции из группы прогнозируемых сильно отличаются друг от друга.
Возьмем пример в контексте машинного обучения. Данные, взятые здесь, следуют квадратичной функции функций (x) для прогнозирования целевого столбца (y_noisy). В реальной жизни данные содержат зашумленную информацию вместо правильных значений. Поэтому мы добавили 0 средних значений, 1 дисперсию гауссовского шума к значениям квадратичной функции.
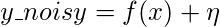
| Икс | у | y_noisy |
|---|---|---|
| -5 | 25 | 2.67595670e + 01 |
| -4,5 | 20,25 | 2.11632561e + 01 |
| -4 | 16 | 1.46802434e + 01 |
| -3,5 | 12,25 | 1.31647290e + 01 |
| -3 | 9 | 1.05460668e + 01 |
| -2,5 | 6,25 | 5.95794282e + 00 |
| -2 | 4 | 3,25487498e + 00 |
| -1,5 | 2,25 | 1.97478968e + 00 |
| -1 | 1 | 1.73960283e + 00 |
| -0,5 | 0,25 | -1.13112086e-02 |
| 0 | 0 | 1.64552536e + 00 |
| 0,5 | 0,25 | -9.60938656e-01 |
| 1 | 1 | 4.46816845e-01 |
| 1.5 | 2,25 | 4.01016081e + 00 |
| 2 | 4 | 1.54342469e + 00 |
| 2,5 | 6,25 | 7.27654456e + 00 |
| 3 | 9 | 9.37684917e + 00 |
| 3.5 | 12,25 | 1.32076198e + 01 |
| 4 | 16 | 1.79133242e + 01 |
| 4.5 | 20,25 | 2.08601281e + 01 |
Визуализация данных
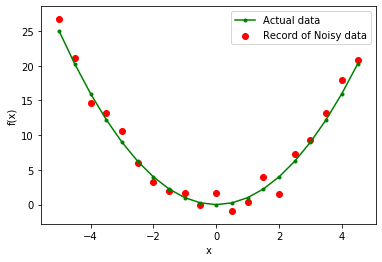
Теперь, когда у нас есть проблема регрессии, давайте попробуем подобрать несколько полиномиальных моделей разного порядка. Представленные здесь результаты относятся к степени: 1, 2, 10.
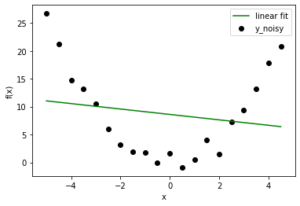
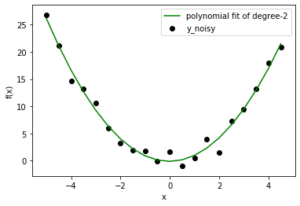
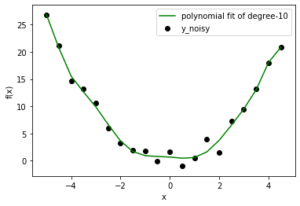
В этом случае мы уже знаем, что правильная модель - это степень-2. Но как только вы расширите свое видение от игрушечной проблемы, вы столкнетесь с ситуациями, когда вы заранее не знаете распределение данных. Итак, если вы выберете модель с более низкой степенью, вы можете неправильно согласовать поведение данных (пусть данные будут далеки от линейного соответствия). Если вы выберете более высокую степень, возможно, вы подбираете шум вместо данных. Модель с более низкой степенью в любом случае даст вам высокую ошибку, но модель с более высокой степенью по-прежнему неверна с низкой ошибкой. Так что нам делать? Мы можем либо использовать метод визуализации, либо поискать лучшие настройки с помощью Bias и Variance. (Специалисты по обработке данных используют только часть данных для обучения модели, а затем используют оставшуюся часть для проверки обобщенного поведения.)
Теперь, если мы построим ансамбль моделей для вычисления смещения и дисперсии для каждой полиномиальной модели:

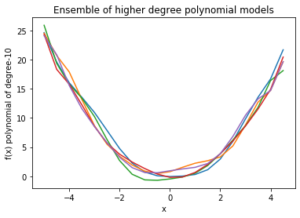
Как мы видим, в линейной модели все линии очень близки друг к другу, но далеки от реальных данных. С другой стороны, полиномиальные кривые более высокой степени внимательно следуют за данными, но имеют большие различия между ними. Следовательно, смещение велико в линейном режиме, а дисперсия - в полиноме более высокой степени. Этот факт отражается и в расчетных количествах.
Линейная модель: - Смещение: 6.3981120643436356 Отклонение: 0,09606406047494431 Модель полинома высшей степени: - Смещение: 0,31310660249287225 Отклонение: 0,565414017195101
После выполнения этой задачи мы можем сделать вывод, что простая модель имеет тенденцию к высокому смещению, в то время как сложная модель имеет высокую дисперсию. По этим характеристикам мы можем определить недостаточную или избыточную посадку.
Снова переходим к математической части: как смещение и дисперсия связаны с эмпирической ошибкой (MSE, которая не является истинной ошибкой из-за добавленного шума в данных) между целевым значением и прогнозируемым значением.
Теперь посчитаем еще одну величину:
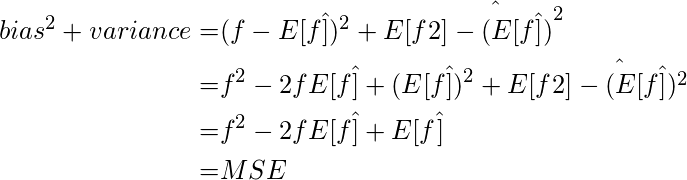
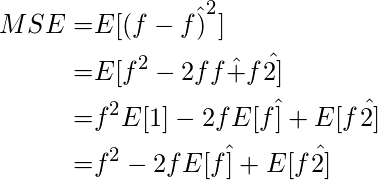
Теперь мы подошли к завершающей фазе. Важно помнить, что предвзятость и дисперсия имеют компромисс, и чтобы свести к минимуму ошибку, нам нужно уменьшить и то, и другое. Это означает, что мы хотим, чтобы прогноз нашей модели был близок к данным (низкое смещение) и чтобы прогнозируемые точки не сильно менялись по отношению к изменяющемуся шуму (низкая дисперсия).