Как Facebook и Netflix используют регрессионное тестирование для улучшения качества релизов

Регрессионное тестирование проверяет, не привели ли выпуск или обновление приложения к новым ошибкам, которых раньше не было. Это очень важно для обеспечения превосходного качества обслуживания клиентов. По мере того, как DevOps стремится увеличить частоту выпусков, увеличивается вероятность появления новых проблем в системе. Решение состоит не в том, чтобы выпускать реже, а в том, чтобы улучшить качество регрессионного тестирования вместе с увеличением частоты выпуска.
Ведущие веб-компании мира осознают это и вкладывают значительные средства в повышение качества своих процессов регрессионного тестирования. В этом посте мы рассмотрим два таких примера — Facebook и Netflix. Каждый из них использует совершенно разные подходы к регрессионному тестированию, но оба эффективно сокращают количество ошибок и достаточно щедры, чтобы поделиться своим подходом и знаниями с более широким сообществом разработчиков.
Facebook: Регрессионное тестирование перед релизом
Известно, что Facebook является пионером в области непрерывного развертывания и уже достиг 60 000 выпусков в день только для своего приложения для Android еще в 2017 году. К настоящему времени это число, несомненно, увеличилось. Проблема непрерывного выпуска релизов в бешеном темпе состоит в том, чтобы гарантировать, что что-то не сломается из-за релизов. С этой целью Facebook тщательно продумывает регрессионное тестирование. Они предоставляют разработчикам инструменты, позволяющие лучше оценивать влияние кода, который они пишут, до того, как он будет запущен в производство.
Двумя такими инструментами являются Health Compass и Incident Tracker. Health Compass позволяет разработчикам указывать конфигурацию для своих развертываний и дублировать эту конфигурацию во всех необходимых инструментах. Это улучшает согласованность тестовых данных и моделирует более точные сценарии использования в реальных условиях.
Большим преимуществом этого является то, что все инструменты внутреннего тестирования говорят на одном языке. Все они используют одни и те же метаданные для описания ошибок. Это вносит ясность в регрессионное тестирование. В то время как Health Compass обеспечивает согласованность данных, Incident Tracker позволяет разработчикам анализировать данные и выявлять проблемы.
Инцидент-трекер предоставляет представление всех ошибок в виде временных рядов и даже устраняет дубликаты ошибок в разных инструментах. Это дает разработчикам четкое представление о том, какие изменения привели к каким ошибкам. Это ключ к улучшению качества кода перед релизом.
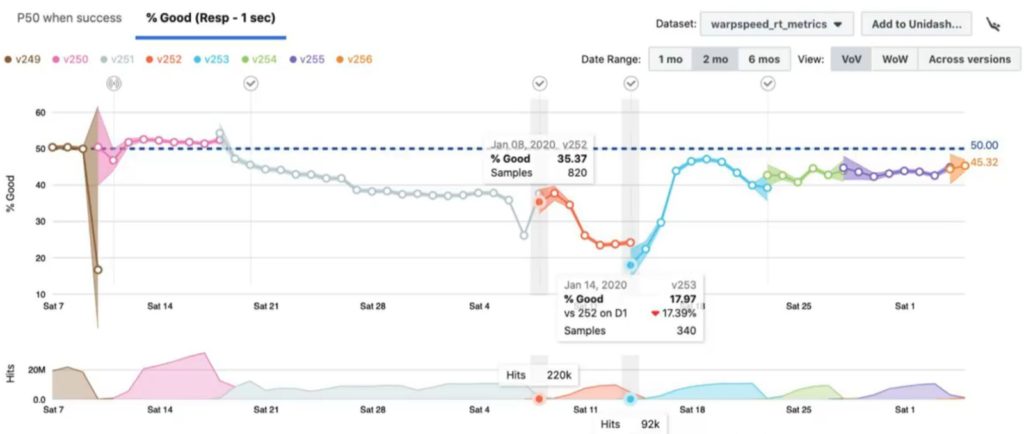
Инцидент-трекер показывает два особенно полезных представления этих данных — версия за версией (VoV) и неделя за неделей (WoW). Как видно из изображения выше, визуализация играет важную роль в оценке влияния производительности. Инцидент-трекер хорошо использует диаграмму временных рядов для отображения данных о производительности с течением времени, дополненную цветовой кодировкой и информационными подсказками. Это помогает ускорить процесс анализа ошибок регрессии и позволяет разработчикам быстрее добраться до сути проблемы.
Эти инструменты могут работать практически в режиме реального времени, получая оперативные данные и делая их доступными для анализа разработчиками. Все это помогает разработчикам Facebook выявлять и исправлять ошибки на ранних этапах разработки. Это соответствует концепции сдвига влево, которая занимает центральное место в DevOps.
Однако Facebook не хочет останавливаться на достигнутом. Скорее, они ищут способы провести тестирование дальше слева и отловить ошибки прямо в самой среде IDE. Этот тип «пробного» тестирования также характерен для GitOps. Такие инструменты тестирования, как Sauce Headless, позволяют проводить такие тесты.
Netflix: регрессионное тестирование после релиза
Netflix использует журналы с устройств в режиме реального времени, чтобы оценить, не сломались ли новые развертывания и не повлияло ли это на работу пользователей. Эти журналы становятся доступными для анализа в режиме реального времени, как только они собираются с пользовательского устройства.
Netflix использует канареечный подход к развертыванию, чтобы выпускать новую версию только для определенного подмножества пользователей. При наличии ошибок выпуск может быть прерван или отменен. Если выпуск не содержит ошибок, он открывается для всех пользователей.

Данные передаются в системы Netflix со скоростью 2 миллиона событий в секунду. Netflix использует метаданные в виде тегов для классификации журналов. Это помогает им анализировать данные с определенного типа устройства или определенного региона. Они проверяют наличие аномалий в данных и выявляют тенденции.
Для анализа данных Netflix использует Apache Druid. Druid — это аналитическая система в реальном времени, ориентированная на скорость и масштаб анализа. Он делает это, организуя данные, которые необходимо проанализировать, по временным отрезкам. Данные журнала отправляются в Druid в виде потока данных в реальном времени с использованием Kafka.
Netflix очень серьезно относится к управлению данными для этого процесса. Например, у них есть порог, после которого лишние данные архивируются. Они намеренно отфильтровывают старые данные, чтобы всегда работать только с самыми свежими данными в реальном времени. Они агрегируют данные, чтобы упростить выполнение запросов. Все это позволяет разработчикам анализировать данные и получать результаты за десятки миллисекунд.
Netflix также рассматривал возможность принятия Druid внутри организации. Поскольку большинство разработчиков были незнакомы с Druid и больше знакомы с Atlas, базой данных временных рядов, созданной Netflix, они создали инструмент, который переводил запросы Atlas в запросы Druid. Это гарантировало бы, что все разработчики Netflix смогут сразу использовать Druid без необходимости проходить обучение. Решение столь же успешно, как и скорость его принятия, и умные организации, такие как Netflix, делают все возможное, чтобы все были на борту.
Разные подходы, одна цель
Хотя Facebook и Netflix используют разные подходы к регрессионному тестированию, обе преследуют одну и ту же цель — выпуск более качественных релизов. Оба заботятся о клиентском опыте, который они обеспечивают. Оба управляются данными и уделяют пристальное внимание тому, как они собирают, анализируют и используют доступные им данные. Они изо всех сил стараются собирать данные независимо от того, насколько сложным становится процесс. Они тщательно очищают и систематизируют данные, чтобы сделать их пригодными для использования. Они также думают о внедрении этих решений внутри организации. Они делают это, используя визуализацию данных, создавая небольшие хаки, чтобы инструмент работал привычным для разработчиков способом. Все это обусловлено неустанным стремлением отслеживать и измерять каждый шаг процесса разработки.
Хотя в этом посте подходы этих организаций разделены на две части: до и после релиза, на самом деле обе организации заботятся о том, что было до, и что будет после. Точно так же каждая организация, которая заботится о клиентском опыте, должна быть одержима всем конвейером, от IDE до производства. Чтобы полностью погрузиться в регрессионное тестирование, организациям нужно как сдвигаться влево, так и сдвигаться вправо. Тестирование необходимо проводить на каждом этапе. Мониторинг и получение обратной связи должны быть встроены в процесс разработки. Это не должно быть предоставлено ручным тестерам контроля качества или специалистам по эксплуатации, а должно быть автоматизировано и систематизировано с помощью инструментов. Эти организации либо использовали легкодоступные инструменты с открытым исходным кодом, либо создавали собственные проприетарные инструменты. Вы даже можете использовать инструмент поставщика и выполнить работу, но основные идеи, лежащие в основе процесса, останутся прежними.
Любая организация может увидеть улучшения, взяв лучшее из обоих миров, которые эти организации продемонстрировали здесь, и применив полученные знания в своем собственном конвейере разработки. Внедрите регрессионное тестирование в процесс разработки и наблюдайте, как клиентский опыт достигает новых высот.