Google Cloud Platform — использование Config Sync для управления Kubernetes
В этой статье мы рассмотрим, как мы можем управлять Kubernetes с помощью Config Sync. Для этого давайте создадим постановку задачи и решим ее.
Постановка задачи:
У Рави новая роль — администратор платформы, и ему поручено следить за тем, чтобы вся инфраструктура, созданная всеми командами его компании, соответствовала требованиям управления. Давайте посмотрим, как Config Sync облегчает его жизнь. Команда Рави использует Kubernetes для разработки.
Решение:
Одним из многих преимуществ Kubernetes является его декларативный рабочий процесс. Вы можете указать, сколько экземпляров приложения вы хотите запустить, и будьте уверены, что Kubernetes обеспечит вам это состояние. Кубернетес

Но иногда состояние работающих кластеров может не соответствовать тому, что написано на бумаге, когда к работающему кластеру применяются непроверенные изменения. Может быть трудно понять, что на самом деле происходит в вашем кластере. Когда это происходит, возвращение вашего кластера в последнее известное хорошее состояние, когда что-то пойдет не так, становится проблематичным. Вот почему Рави предлагает использовать Config Sync для рабочего процесса git ops. Config Sync позволяет операторам кластеров управлять кластерами Kubernetes с помощью файлов, называемых конфигурациями, которые хранятся в репозиториях git.
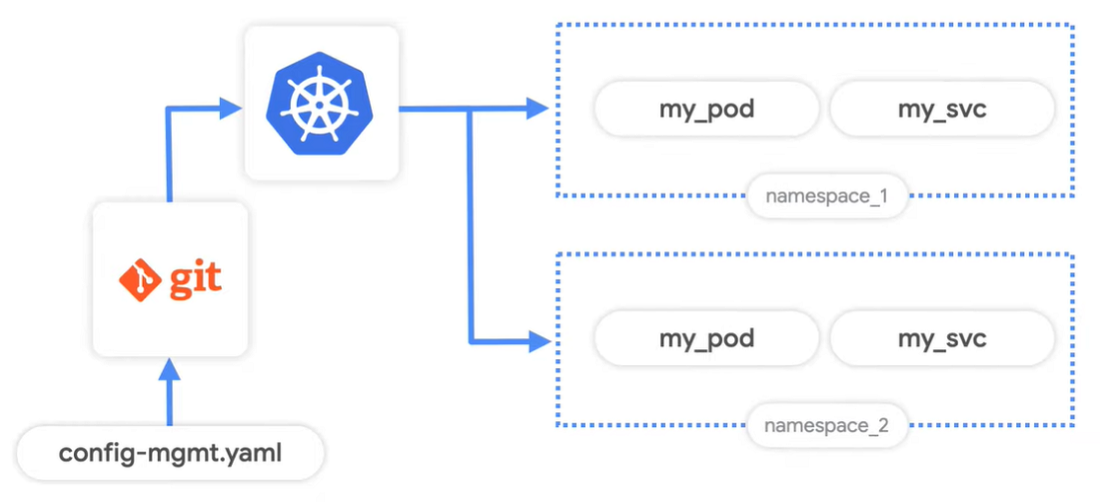
Config Sync следит за обновлениями этих файлов и автоматически применяет изменения ко всем соответствующим кластерам. Заблокировав прямой доступ к Kubernetes API, он может потребовать, чтобы все изменения конфигурации кластера распространялись с помощью Config Sync. Следующая команда используется для того же:
$ kubectl delete pod my_pod --ns namespace_1
Таким образом, все изменения проверяются перед отправкой. Декларативные инструменты, такие как Config Sync, означают, что git станет источником правды и точно отразит то, что происходит в вашем действующем кластере. Для администратора платформы, такого как Рави, это победа. И по мере того, как вся система становится проще в управлении, отладке и мониторинге.
Давайте посмотрим на пример того, как можно использовать Config Sync для синхронизации репозитория. В этом примере мы создали кластер, сделали себя администратором кластера и установили обычную команду и оператор Config Sync в кластер, с которым мы работаем.
Первый шаг — настроить репозиторий git, в котором хранятся конфигурации, из которых будет синхронизироваться наш кластер. Мы создадим файл конфигурации с именем config-management-yaml , который будет применяться ко всем нашим кластерам. Этот файл сообщает Kubernetes, с какими кластерами работать. И он предоставляет информацию о репозитории git, включая ветку и папку для синхронизации. При необходимости мы можем настроить учетные данные для доступа к частному репозиторию. Это будет выглядеть примерно так:
$ cat config-management.yaml
apiVersion: configmanagement.gke.io/v1
kind: ConfigManagement
metadata:
name: config-management
spec:
clusterName: my_cluster
git:
syncRepo: https://github.com/GoogleCloud Platform/csp-config-management/ syncBranch: 1.0.0
secretType: none
policyDir: "geeksforgeeks.org"Как только это будет применено, вы увидите, что оператор Config Sync фактически создает модули в пространстве имен Config Management. Это службы, которые запускаются, чтобы убедиться, что желаемое состояние кластера совпадает с его фактическим состоянием.
С Config Sync вы можете сочетать подход git ops с git для хранения и управления версиями. И ваши изменения будут автоматически синхронизированы с кластером, чтобы обеспечить согласованный процесс проверки. При таком подходе все изменения конфигурации следуют последовательному процессу проверки, который проверяется и утверждается перед применением, точно так же, как код. Это значительно упрощает для Рави обеспечение того, чтобы все команды последовательно следовали этому процессу, чтобы его можно было масштабировать по всей компании.