Введение в Explainable AI (XAI) с использованием LIME
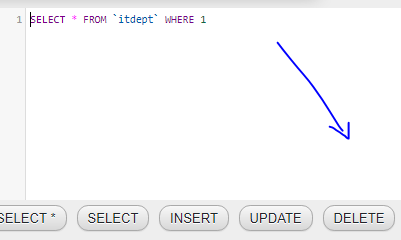
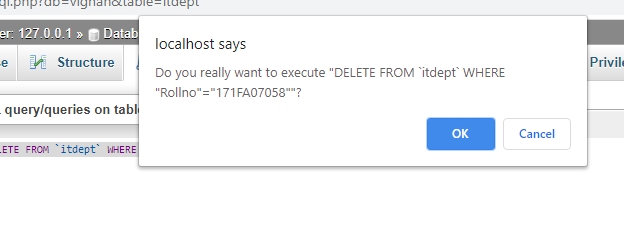
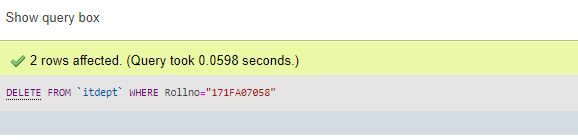
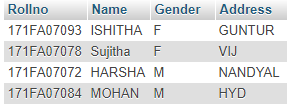
Мотивация объяснимого ИИ
Обширная область искусственного интеллекта (ИИ) за последние годы пережила огромный рост. С появлением новых и более сложных моделей каждый год модели искусственного интеллекта начали превосходить человеческий интеллект со скоростью, которую никто не мог предсказать. Но по мере того, как мы получаем более точные и точные результаты, становится все труднее объяснить причины сложных математических решений, которые принимают эти модели. Эта математическая абстракция также не помогает пользователям сохранять доверие к решениям конкретной модели.
e.g., Say a Deep Learning model takes in an image and predicts with 70% accuracy that a patient has lung cancer. Though the model might have given the correct diagnosis, a doctor can’t really advise a patient confidently as he/she doesn’t know the reasoning behind the said model’s diagnosis.
Вот где появляется Объясняемый ИИ (или более известный как XAI)! Объяснимый ИИ в совокупности относится к методам или методам, которые помогают объяснить процесс принятия решений данной моделью ИИ. Эта недавно открытая ветвь искусственного интеллекта продемонстрировала огромный потенциал, с каждым годом появляются все новые и более сложные методы. Некоторые из самых известных методик XAI включают SHAP (добавочные объяснения Шепли), DeepSHAP, DeepLIFT, CXplain и LIME. В этой статье подробно рассматривается извести.
Представляем LIME (или местные интерпретируемые независимые от модели объяснения)
Прелесть LIME в ее доступности и простоте. Основная идея LIME, хотя и исчерпывающая, действительно интуитивно понятна и проста! Давайте углубимся и посмотрим, что представляет собой само название:
- Модельный агностицизм относится к свойству LIME, с помощью которого он может давать объяснения любой данной модели контролируемого обучения, рассматривая ее как «черный ящик» отдельно. Это означает, что LIME может работать практически с любой моделью, которая существует в дикой природе!
- Локальные объяснения означают, что LIME дает объяснения, которые являются локально достоверными в пределах или поблизости от объясняемого наблюдения / образца.
Хотя LIME в своем текущем состоянии ограничивается контролируемыми моделями машинного обучения и глубокого обучения, это один из самых популярных и используемых методов XAI. Благодаря богатому API с открытым исходным кодом, доступному в R и Python, LIME может похвастаться огромной пользовательской базой с почти 8 000 звезд и 2 000 форков в своем репозитории Github.
Как работает LIME?
Вообще говоря, при наличии модели прогнозирования и тестового образца LIME выполняет следующие шаги:
- Выборка и получение суррогатного набора данных: LIME предоставляет локально достоверные объяснения в окрестностях объясняемого экземпляра. По умолчанию он производит 5000 выборок (см. Переменную num_samples ) вектора признаков в соответствии с нормальным распределением. Затем он получает целевую переменную для этих 5000 выборок, используя модель прогнозирования, решения которой пытается объяснить.
- Выбор функций из суррогатного набора данных: после получения суррогатного набора данных каждая строка взвешивается в зависимости от того, насколько они близки к исходной выборке / наблюдению. Затем он использует технику выбора объектов, такую как лассо, для получения наиболее важных функций.
LIME также использует модель регрессии хребта для образцов, используя только полученные характеристики. Полученный прогноз теоретически должен быть аналогичен по величине прогнозу, полученному с помощью исходной модели прогнозирования. Это сделано для того, чтобы подчеркнуть актуальность и важность полученных характеристик.
В этой статье мы не будем углубляться в технические и математические детали, лежащие в основе внутреннего устройства LIME. Тем не менее, вы можете просмотреть базовое исследование, если оно вам интересно. Теперь перейдем к более интересной части - коду!
Установка LIME
Переходя к части установки, мы можем использовать pip или conda для установки LIME в Python.
pip install лайм
или же
conda install -c conda-forge lime
Прежде чем продолжить, вот несколько ключевых указателей, которые помогут лучше понять весь рабочий процесс, связанный с LIME.
Описание набора данных:
LIME в своем текущем состоянии может давать объяснения только для следующих типов наборов данных:
- Табличные наборы данных (lime.lime_tabular.LimeTabularExplainer): например: регрессия, наборы данных классификации
- Наборы данных, связанных с изображениями (lime.lime_image.LimeImageExplainer)
- Наборы данных, связанные с текстом (lime.lime_text.LimeTextExplainer)
Поскольку это вводная статья, мы сохраним простоту и продолжим работу с табличным набором данных. В частности, для нашего анализа мы будем использовать набор данных Boston House Pricing. Мы будем использовать утилиту Scikit-Learn для загрузки набора данных.
Используемая модель прогнозирования:
Поскольку LIME по своей природе не зависит от модели, он может справиться практически с любой моделью. Чтобы подчеркнуть этот факт, мы будем использовать регрессию Extra-tree с помощью утилиты Scitkit-learn в качестве нашей модели прогнозирования, решения которой мы пытаемся исследовать.
Краткое введение в LimeTabularExplainer
Как объяснено выше, мы будем использовать табличный набор данных для нашего анализа. Для работы с такими наборами данных API LIME предлагает LimeTabularExplainer.
Syntax: lime.lime_tabular.LimeTabularExplainer(training_data, mode, feature_names, verbose)
Parameters:
- training_data – 2d array consisting of the training dataset
- mode – Depends on the problem; “classification” or “regression”
- feature_names – list of titles corresponding to the columns in the training dataset. If not mentioned, it uses the cloumn indices.
- verbose – if true, print local prediction values from the regression model trained on the samples using only the obtained features
После создания экземпляра мы будем использовать метод из определенного объекта объяснения для объяснения данного тестового образца.
Syntax: explain_instance(data_row, predict_fn, num_features=10, num_samples=5000)
Parameters:
- data_row – 1d array containing values corresponding to the test sample being explained
- predict_fn – Prediction function used by the prediction model
- num_features – maximum number of features present in explanation
- num_samples – size of the neighborhood to learn the linear model
Для краткости и краткости в двух приведенных выше синтаксисах упомянуты только некоторые аргументы. Остальные аргументы, большинство из которых по умолчанию имеют некоторые разумно оптимизированные значения, могут быть проверены заинтересованным читателем в официальной документации LIME.
Рабочий процесс
- Предварительная обработка данных
- Обучение регрессора Extra-tree на наборе данных
- Получение пояснений к заданному образцу испытаний
Анализ
1. Извлечение данных из утилиты Scikit-learn
Python
# Importing the necessary librariesimport numpy as npimport matplotlib.pyplot as pltimport pandas as pd# Loading the dataset using sklearnfrom sklearn.datasets import load_bostondata = load_boston()# Displaying relevant information about the dataprint (data[ 'DESCR' ][ 200 : 1420 ]) |
Выход:
Вывод приведенного выше кода для ноутбука Jupyter
2. Извлечение матрицы признаков X и целевой переменной y и выполнение разделения на обучающий тест.
Python
# Separating data into feature variable X and target variable y respectivelyfrom sklearn.model_selection import train_test_splitX = data[ 'data' ]y = data[ 'target' ]# Extracting the names of the features from datafeatures = data[ 'feature_names' ]# Splitting X & y into training and testing setX_train, X_test, y_train, y_test = train_test_split( X, y, train_size = 0.90 , random_state = 50 )# Creating a dataframe of the data, for a visual checkdf = pd.concat([pd.DataFrame(X), pd.DataFrame(y)], axis = 1 )df.columns = np.concatenate((features, np.array([ 'label' ])))print ( "Shape of data =" , df.shape)# Printing the top 5 rows of the dataframedf.head() |
Выход:
Вывод приведенного выше кода для ноутбука Jupyter
3. Создание экземпляра модели прогнозирования и ее обучение на (X_train, y_train)
Python
# Instantiating the prediction model - an extra-trees regressorfrom sklearn.ensemble import ExtraTreesRegressorreg = ExtraTreesRegressor(random_state = 50 )# Fitting the predictino model onto the training setreg.fit(X_train, y_train)# Checking the model's performance on the test setprint ( 'R2 score for the model on test set =' , reg.score(X_test, y_test)) |
Выход:
Вывод приведенного выше кода для ноутбука Jupyter
4. Создание экземпляра объекта объяснения
Python
# Importing the module for LimeTabularExplainerimport lime.lime_tabular# Instantiating the explainer object by passing in the training set, and the extracted featuresexplainer_lime = lime.lime_tabular.LimeTabularExplainer(X_train, feature_names = features, verbose = True , mode = 'regression' ) |
5. Получение объяснений по телефону () метод EXPLAIN_INSTANCE
- Предположим, мы хотим изучить рассуждения модели прогнозирования, лежащие в основе прогноза, который она дала для i-го тестового вектора .
- Более того, предположим, мы хотим визуализировать основные k функций, которые привели к этому рассуждению .
В этой статье мы объяснили две комбинации i и k :
5.1 Объяснение решений для i = 10, k = 5
We’re basically asking LIME to explain the decisions behind the predictions for the 10th test vector by displaying the top 5 features which contributed towards the said model’s prediction.
Python
# Index corresponding to the test vectori = 10# Number denoting the top featuresk = 5# Calling the explain_instance method by passing in the:# 1) ith test vector# 2) prediction function used by our prediction model('reg' in this case)# 3) the top features which we want to see, denoted by kexp_lime = explainer_lime.explain_instance( X_test[i], reg.predict, num_features = k)# Finally visualizing the explanationsexp_lime.show_in_notebook() |
Выход:
Вывод приведенного выше кода для ноутбука Jupyter
Интерпретация вывода
LIME выводит много информации! Давайте шаг за шагом интерпретируем то, что он пытается передать
- Во-первых, мы видим три значения чуть выше визуализаций:
- Справа: это обозначает прогноз, данный нашей моделью прогнозирования (в данном случае регрессором дополнительных деревьев) для данного тестового вектора.
- Prediction_local: обозначает значение, выводимое линейной моделью, обученной на возмущенных выборках (полученная путем выборки вокруг тестового вектора в соответствии с нормальным распределением) и с использованием только верхних k функций, выведенных LIME.
- Перехват: Перехват - это постоянная часть прогноза, заданного прогнозом приведенной выше линейной модели для данного тестового вектора.
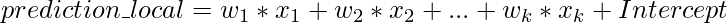
- Переходя к визуализациям, мы можем увидеть синий и оранжевый цвета , изображающие негативные и позитивные ассоциации соответственно.
- Чтобы интерпретировать приведенные выше результаты, мы можем заключить, что относительно более низкая стоимость дома (изображенная полосой слева), изображенная данным вектором, может быть связана со следующими социально-экономическими причинами:
- высокое значение LSTAT, указывающее на более низкий статус общества с точки зрения образования и безработицы
- высокое значение PTRATIO, указывающее на высокое значение количества учеников на одного учителя
- высокое значение DIS указывает на большое значение удаленности от центров занятости.
- низкое значение RM, указывающее на меньшее количество комнаты в доме
- Мы также можем видеть, что низкое значение NOX указывает на то, что низкая концентрация оксида азота в воздухе немного повысила ценность дома.
- Чтобы интерпретировать приведенные выше результаты, мы можем заключить, что относительно более низкая стоимость дома (изображенная полосой слева), изображенная данным вектором, может быть связана со следующими социально-экономическими причинами:
We can see how easy it has become to correlate the decisions taken by a relatively complex prediction model(an extra-trees regressor) in an interpreatable and meaningful way. Let’s try this exercise on one more test vector!
5.2 Объяснение решений для i = 47, k = 5
Here again we’re asking LIME to explain the decisions behind the predictions for the 47th test vector by displaying the top 5 features which contributed towards the said model’s prediction
Python
# Index corresponding to the test vectori = 47# Number denoting the top featuresk = 5# Calling the explain_instance method by passing in the:# 1) ith test vector# 2) prediction function used by our prediction model('reg' in this case)# 3) the top features which we want to see, denoted by kexp_lime = explainer_lime.explain_instance( X_test[i], reg.predict, num_features = k)# Finally visualizing the explanationsexp_lime.show_in_notebook() |
Выход:
Вывод приведенного выше кода для ноутбука Jupyter
Интерпретация вывода:
- Из визуализаций мы можем сделать вывод, что относительно более высокая стоимость дома (обозначенная полосой слева), изображенная данным вектором, может быть связана со следующими социально-экономическими причинами:
- Низкое значение LSTAT, указывающее на высокий статус общества с точки зрения образования и возможности трудоустройства.
- Высокое значение RM указывает на большое количество комнат в доме.
- Низкое значение НАЛОГА, указывающее на низкую ставку налога на недвижимость.
- Низкое значение AGE, которое отражает новизну заведения.
- Мы также можем видеть, что средняя стоимость INDUS , которая указывает на то, что небольшое количество не розничных магазинов рядом с обществом , немного снизила стоимость дома.
Резюме:
Эта статья представляет собой краткое введение в Explainable AI (XAI) с использованием LIME в Python. Очевидно, насколько полезным LIME может дать нам глубокую интуицию, лежащую в основе процесса принятия решений данной модели «черного ящика», в то же время предоставляя твердое представление о внутреннем наборе данных. Это делает LIME полезным ресурсом как для исследователей ИИ, так и для специалистов по данным!
Рекомендации:
- https://lime-ml.readthedocs.io/en/latest/
- https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.ExtraTreesRegressor.html
- https://scikit-learn.org/0.16/modules/generated/sklearn.datasets.load_boston.html#sklearn.datasets.load_boston
- Марко Тулио Рибейро, Самир Сингх и Карлос Гестрин. «Почему я должен тебе доверять?»: Объясняя предсказания любого классификатора. В материалах 22-й Международной конференции ACM SIGKDD по открытию знаний и интеллектуальному анализу данных, стр. 1135–1144. Ассоциация вычислительной техники, 2016.
Внимание компьютерщик! Укрепите свои основы с помощью базового курса программирования Python и изучите основы.
Для начала подготовьтесь к собеседованию. Расширьте свои концепции структур данных с помощью курса Python DS. А чтобы начать свое путешествие по машинному обучению, присоединяйтесь к курсу Машинное обучение - базовый уровень.