Установка и настройка Hadoop в псевдо-распределенном режиме в Windows 10
Чтобы выполнить настройку и установку Hadoop в псевдораспределенном режиме в Windows 10, выполните следующие действия, указанные ниже. Обсудим по порядку.
Шаг 1: Загрузите двоичный пакет:
Загрузите последнюю версию двоичного файла со следующего сайта следующим образом.
http://hadoop.apache.org/releases.html
Для справки вы можете проверить сохранение файла в папке следующим образом.
C:BigData
Шаг 2. Распакуйте двоичный пакет.
Откройте Git Bash и смените каталог (cd) на папку, в которой вы сохраняете двоичный пакет, а затем разархивируйте его следующим образом.
$ cd C: BigData MINGW64: C: BigData $ tar -xvzf hadoop-3.1.2.tar.gz
В моей ситуации двойная часть Hadoop извлекается в C: BigData hadoop-3.1.2.
Затем перейдите в этот репозиторий GitHub и загрузите органайзер розеток в качестве скорости, как показано ниже. Сконцентрируйте компресс и скопируйте все документы, находящиеся под конвертом приемника, в C: BigData hadoop-3.1.2 bin. Замените и текущие записи.
Шаг 3: Создайте папки для datanode и namenode:
- Перейдите к C: /BigData/hadoop-3.1.2 и сделайте "информация" органайзера. Внутри «информационного» конверта сделайте два органайзера «datanode» и «namenode». Ваши документы на HDFS будут находиться под конвертом датанода.

- Установить переменные среды Hadoop
- Hadoop требует, чтобы были установлены следующие переменные среды.
HADOOP_HOME = "C: BigData hadoop-3.1.2" HADOOP_BIN = "C: BigData hadoop-3.1.2 bin" JAVA_HOME = <Корень вашей установки JDK> »
- Чтобы установить эти переменные, перейдите в «Мой компьютер» или «Этот компьютер».
Щелкните правой кнопкой мыши -> Свойства -> Расширенные настройки системы -> Переменные среды.
- Нажмите «Создать», чтобы создать новую переменную среды.
- Если у вас нет представленной JAVA 1.8, вам нужно сначала загрузить и представить ее. Если теперь установлена переменная климата JAVA_HOME, проверьте, есть ли в пути пробелы (например, C: Program Files Java …). Пробелы в пути JAVA_HOME приведут вас к проблемам. Есть трюк, чтобы обойти это. Замените 'Program Files' на 'Progra ~ 1' в переменной value. Гарантируйте, что вариант Java - 1.8, а JAVA_HOME выделяет JDK 1.8.
Шаг 4. Создание краткого имени домашнего пути Java
- Установить переменные среды Hadoop
- Изменить переменную среды PATH
- Нажмите New и добавьте% JAVA_HOME%,% HADOOP_HOME%,% HADOOP_BIN%,% HADOOP_HOME% / sin в свой PATH один за другим.

- Теперь мы установили переменные среды, нам нужно их проверить. Откройте новую командную строку Windows и запустите команду echo для каждой переменной, чтобы убедиться, что им присвоены желаемые значения.
эхо% HADOOP_HOME% эхо% HADOOP_BIN% эхо% ПУТЬ%
- Если факторы еще не установлены, на этом этапе это, вероятно, может быть связано с тем, что вы пробуете их на старом собрании. Убедитесь, что вы открыли еще один бриф по заказу, чтобы проверить их.
Шаг 5. Настройте Hadoop
После настройки переменных среды нам нужно настроить Hadoop, отредактировав следующие файлы конфигурации.
hadoop-env.cmd core-site.xml hdfs-site.xml mapred-site.xml пряжа-site.xml hadoop-env.cmd
Сначала давайте настроим файл среды Hadoop. Откройте C: BigData hadoop-3.1.2 etc hadoop hadoop-env.cmd и добавьте содержимое внизу внизу
установить HADOOP_PREFIX =% HADOOP_HOME% установить HADOOP_CONF_DIR =% HADOOP_PREFIX% etc hadoop установить YARN_CONF_DIR =% HADOOP_CONF_DIR% установить PATH =% PATH%;% HADOOP_PREFIX% bin
Шаг 6. Отредактируйте hdfs-site.xml
После редактирования core-site.xml вам необходимо установить коэффициент репликации и расположение namenode и datanodes. Откройте C: BigData hadoop-3.1.2 etc hadoop hdfs-site.xml и ниже содержимое в тегах <configuration> </configuration>.
<конфигурация>
<собственность>
<name> dfs.replication </name>
<value> 1 </value>
</property>
<собственность>
<имя> dfs.namenode.name.dir </name>
<значение> C: BigData hadoop-3.2.1 data namenode </value>
</property>
<собственность>
<name> dfs.datanode.data.dir </name>
<значение> C: BigData hadoop-3.1.2 data datanode </value>
</property>
</configuration>Шаг 7. Отредактируйте core-site.xml
Теперь настройте параметры Hadoop Core. Откройте C: BigData hadoop-3.1.2 etc hadoop core-site.xml и ниже содержимое в тегах <configuration> </configuration>.
<конфигурация> <собственность> <name> fs.default.name </name> <value> hdfs: //0.0.0.0: 19000 </value> </property> </configuration>
Шаг 8: конфигурации ПРЯЖИ
Отредактируйте файл yarn-site.xml
Убедитесь, что следующие записи существуют, как указано ниже.
<конфигурация> <свойство> <name> yarn.nodemanager.aux-services </name> <value> mapreduce_shuffle </value> </property> <собственность> <name> yarn.nodemanager.aux-services.mapreduce.shuffle.class </name> <value> org.apache.hadoop.mapred.ShuffleHandler </value> </property> </configuration>
Шаг 9. Отредактируйте mapred-site.xml
Наконец, как насчет того, чтобы расположить свойства для системы Map-Reduce. Откройте C: BigData hadoop-3.1.2 etc hadoop mapred-site.xml и под содержимым внутри ярлыков <configuration> </configuration>. Если вы не видите mapred-site.xml, откройте запись mapred-site.xml.template и переименуйте ее в mapred-site.xml.
<конфигурация>
<собственность>
<name> mapreduce.job.user.name </name> <value>% USERNAME% </value>
</property>
<собственность>
<name> mapreduce.framework.name </name>
<value> пряжа </value>
</property>
<собственность>
<name> yarn.apps.stagingDir </name> <value> / user /% USERNAME% / staging </value>
</property>
<собственность>
<name> mapreduce.jobtracker.address </name>
<value> местный </value>
</property>
</configuration>Проверьте, присутствует ли файл C: BigData hadoop-3.1.2 etc hadoop slaves, если он еще не создан, добавьте в него localhost и сохраните.
Шаг 10: Формат имени узла:
Чтобы организовать узел имени, откройте другую командную строку Windows и выполните приведенный ниже порядок. Это может дать вам несколько увещеваний, не обращайте на них внимания.
- hadoop namenode -format
Форматирование узла имени Hadoop
Шаг 11: Запустите Hadoop:
Откройте еще одно краткое описание команд Windows, запустите его от имени администратора, чтобы сохранять стратегическое расстояние от ошибок авторизации. При открытии выполнить начальный заказ all.cmd. Поскольку мы добавили% HADOOP_HOME% sbin в переменную PATH, вы можете запустить этот заказ из любого конверта. Если вы этого не сделали, перейдите в органайзер% HADOOP_HOME% sbin и запустите заказ.

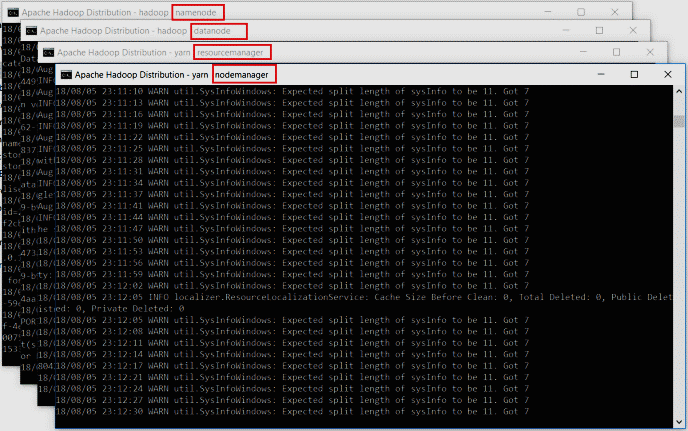
Вы можете проверить приведенный ниже снимок экрана для справки. Откроются 4 новых окна и терминалы cmd для 4 процессов демона, как показано ниже.
- Namenode
- датанод
- менеджер узлов
- менеджер ресурсов
Не закрывайте эти окна, сворачивайте их. Закрытие окон завершит работу демонов. Вы можете запустить их в фоновом режиме, если не хотите видеть эти окна.
Шаг 12: веб-интерфейс Hadoop
В заключение, как насчет того, чтобы увидеть, как обстоят дела у демонов Hadoop? Также вы можете использовать веб-интерфейс для широкого круга авторитетных и наблюдательных целей. Откройте вашу программу и начните.
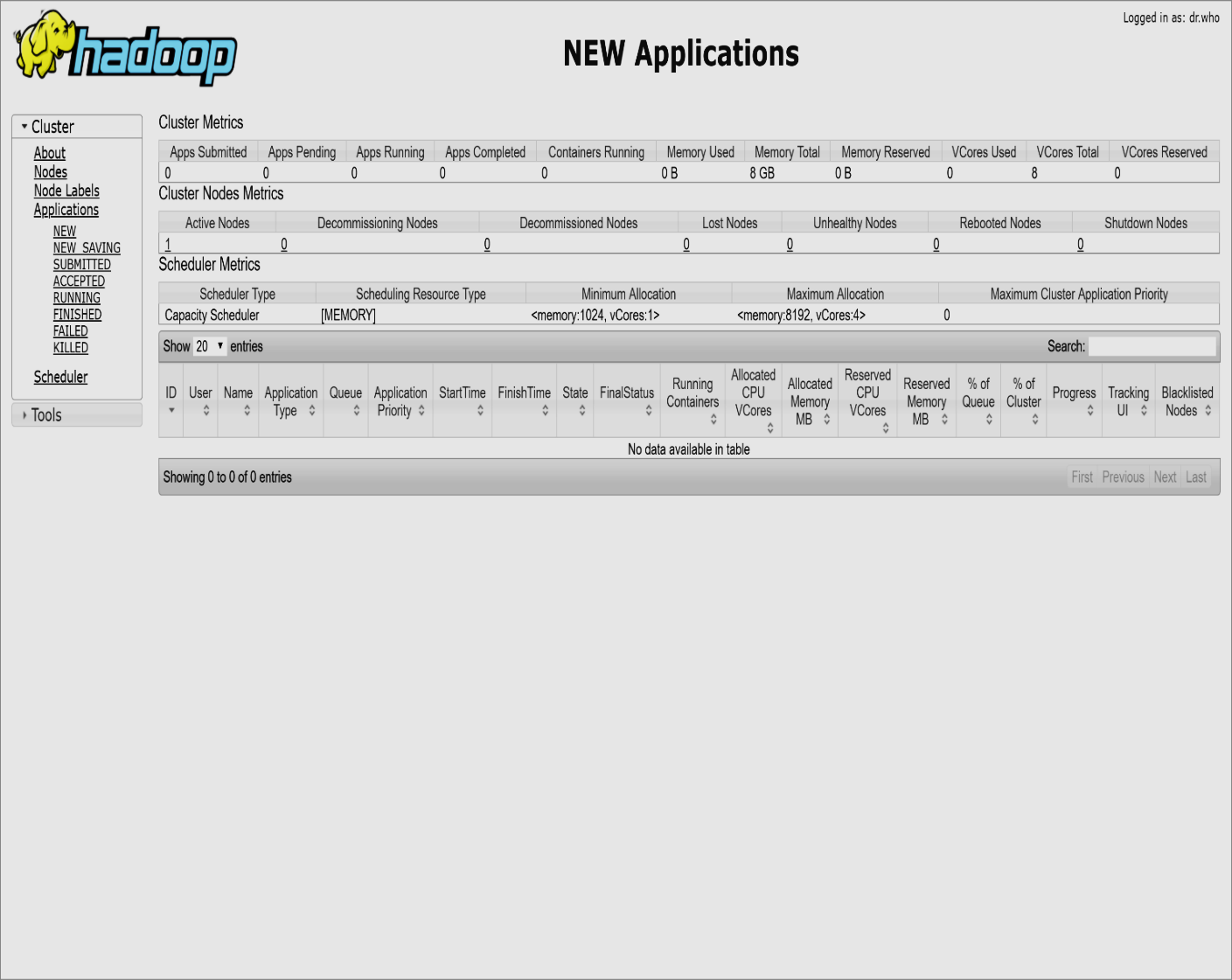
Шаг 13: диспетчер ресурсов
Откройте localhost: 8088, чтобы открыть диспетчер ресурсов.
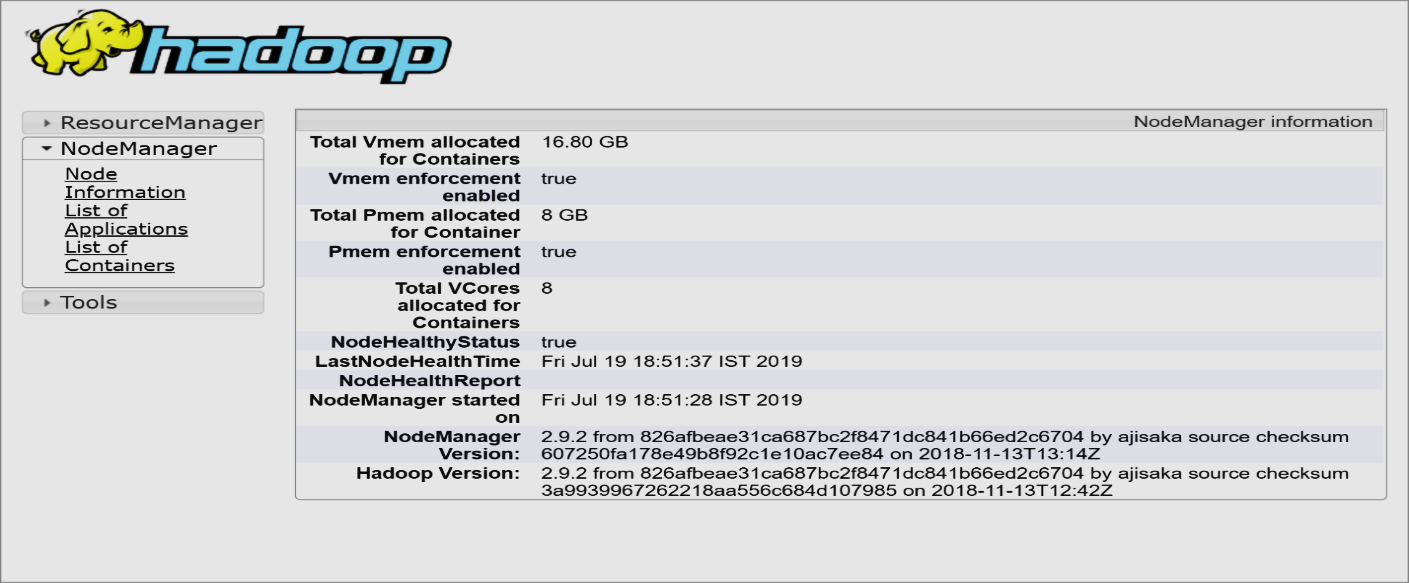
Шаг 14: Диспетчер узлов
Откройте localhost: 8042, чтобы открыть диспетчер узлов.
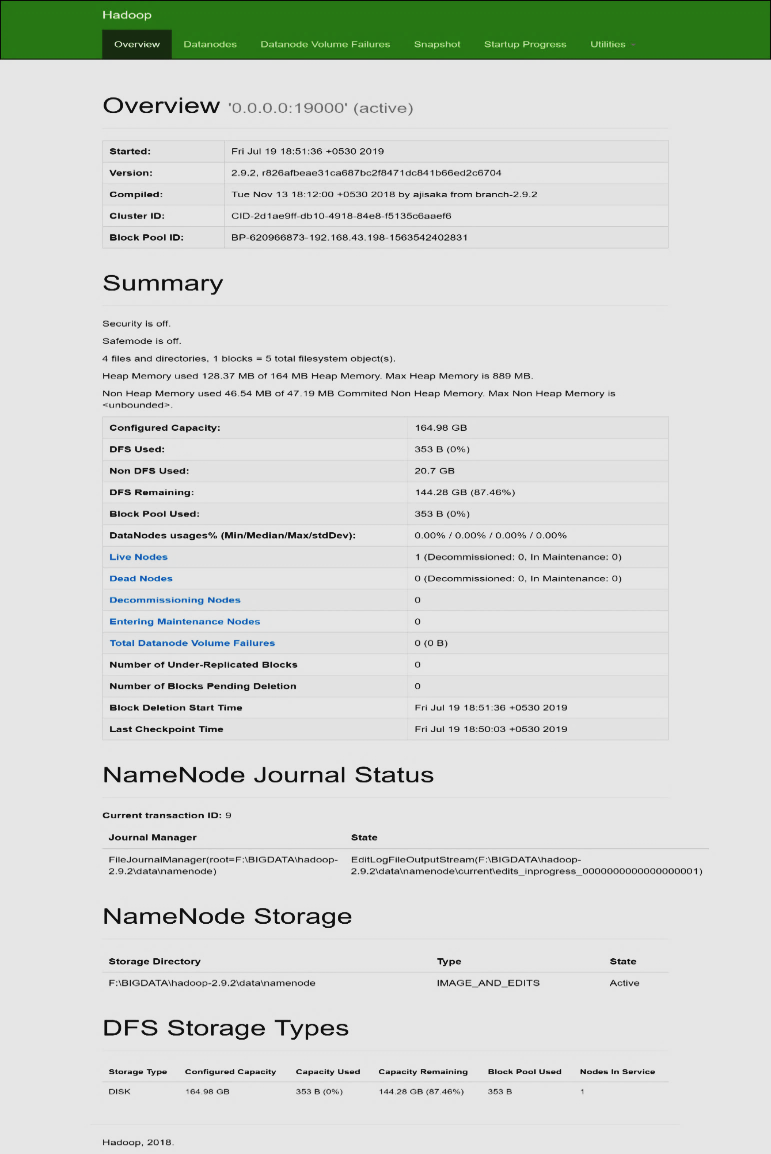
Шаг 15: Имя узла:
Откройте localhost: 9870, чтобы проверить работоспособность Name Node.
Шаг 16: Узел данных:
Откройте localhost: 9864, чтобы проверить узел данных.