Установите Apache Spark в автономном режиме в Windows
Apache Spark — это молниеносный унифицированный аналитический механизм, используемый для кластерных вычислений для больших наборов данных, таких как BigData и Hadoop, с целью запуска программ параллельно на нескольких узлах. Это комбинация нескольких стековых библиотек, таких как SQL и Dataframes, GraphX, MLlib и Spark Streaming.
Spark работает в 4 различных режимах:
- Автономный режим: здесь все процессы выполняются в рамках одного процесса JVM.
- Автономный режим кластера: в этом режиме используется встроенная в Spark структура планирования заданий.
- Apache Mesos: в этом режиме рабочие узлы работают на разных машинах, но драйвер работает только на главном узле.
- Hadoop YARN: в этом режиме драйверы запускаются внутри главного узла приложения и обрабатываются YARN в кластере.
В этой статье мы рассмотрим установку Apache Spark в автономном режиме. Apache Spark разработан на языке программирования Scala и работает на JVM. Установка Java — одна из обязательных вещей в Spark. Итак, начнем с установки Java.
Установка Java:
Шаг 1: Загрузите Java JDK.
Шаг 2. Откройте загруженный пакет разработки Java SE и следуйте инструкциям по установке.
Шаг 3: Откройте переменную среды на ноутбуке, введя ее в строке поиска Windows.
Установите переменные JAVA_HOME:
Чтобы установить переменную JAVA_HOME, выполните следующие действия:
- Нажмите на пользовательскую переменную Добавить JAVA_HOME в PATH со значением Значение: C:Program FilesJavajdk1.8.0_261.
- Щелкните системную переменную. Добавьте C:Program FilesJavajdk1.8.0_261in в переменную PATH.
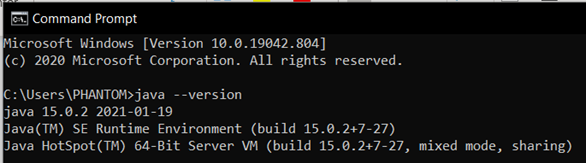
- Откройте командную строку и введите «java –version», она покажет ниже и проверьте установку Java.
Установка Скала:
Чтобы установить Scala на локальный компьютер, выполните следующие действия:
Шаг 1: Скачайте Scala.
Шаг 2: Нажмите на файл .exe и следуйте инструкциям, чтобы настроить установку в соответствии с вашими потребностями.
Шаг 3: Примите соглашение и нажмите кнопку «Далее».
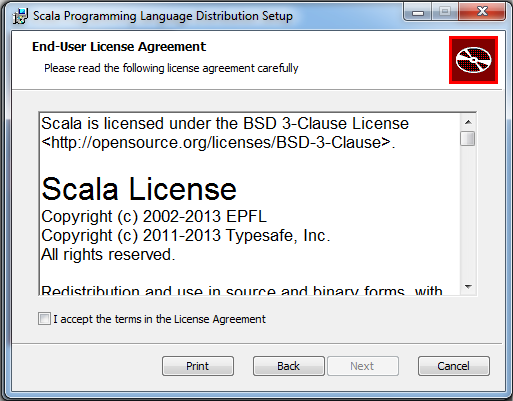
Установите переменные окружения:
- В пользовательской переменной добавьте SCALA_HOME в PATH со значением C:Program Files (x86)scala.
- В системной переменной добавьте C:Program Files (x86)scalain в переменную PATH.
Проверьте установку Scala:
В командной строке используйте следующую команду для проверки установки Scala:
scala

Установка Спарка:
Загрузите готовую версию Spark и извлеките ее на диск C, например C:Spark. Затем щелкните установочный файл и следуйте инструкциям по настройке Spark.
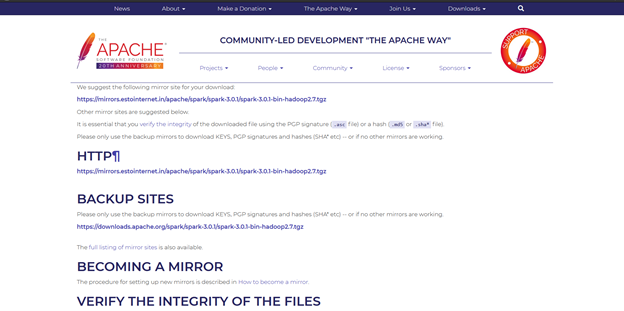
Установите переменные окружения:
- В пользовательской переменной добавьте SPARK_HOME в PATH со значением C:sparkspark-2.4.6-bin-hadoop2.7.
- В системной переменной добавьте% SPARK_HOME%in к переменной PATH.
Загрузите утилиты Windows:
Если вы хотите работать с данными Hadoop, выполните следующие действия, чтобы загрузить утилиту для Hadoop:
Шаг 1: Загрузите файл winutils.exe.
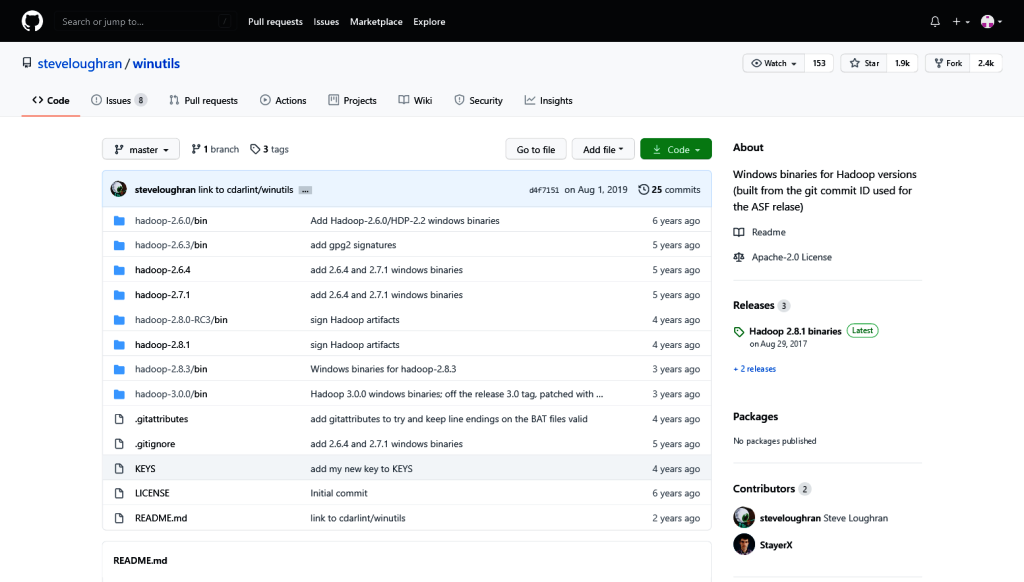
Шаг 2. Скопируйте файл в папку C:sparkspark-1.6.1-bin-hadoop2.6in.
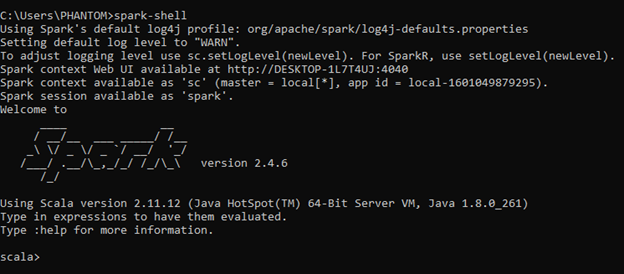
Шаг 3: Теперь выполните «spark-shell» в cmd, чтобы проверить установку искры, как показано ниже: