Установка Apache Pig в Windows и пример использования
Apache Pig - это инструмент для обработки данных, созданный на основе Hadoop MapReduce. Pig предоставляет нам язык сценариев для более простого и быстрого манипулирования данными. Этот язык сценариев называется Pig Latin.
Скрипты Apache Pig можно выполнить тремя способами:
- Использование оболочки Grunt (интерактивный режим) - напишите команды в оболочке grunt и получите результат самостоятельно с помощью команды DUMP.
- Использование сценариев Pig (пакетный режим) - запишите латинские команды pig в один файл с расширением .pig и выполните сценарий в командной строке.
- Использование пользовательских функций (встроенный режим) - напишите свои собственные функции на таких языках, как Java, а затем используйте их в сценариях.
Установка свиньи:
Прежде чем продолжить, вам необходимо убедиться, что у вас есть все эти предварительные условия.
- Экосистема Hadoop установлена в вашей системе, и все четыре компонента, то есть DataNode, NameNode, ResourceManager, TaskManager, работают. Если какой-либо из них случайно отключается, вам необходимо исправить это, прежде чем продолжить.
- 7-Zip требуется для извлечения файлов .tar.gz в Windows.
Давайте посмотрим, как установить версию Pig (0.17.0) в Windows следующим образом.
Шаг 1. Загрузите tar-файл Pig версии 0.17.0 с официального сайта Apache Pig. Перейдите на сайт https://downloads.apache.org/pig/latest/. Загрузите с веб-сайта файл pig-0.17.0.tar.gz.
Затем извлеките этот tar-файл с помощью инструмента 7-Zip (используйте 7-Zip для более быстрого извлечения. Сначала мы извлекаем файл .tar.gz, щелкнув его правой кнопкой мыши и выбрав «7-Zip → Извлечь сюда». Затем мы извлекаем файл .tar.gz. .tar файл таким же образом). Чтобы иметь те же пути, что и на схеме, вам необходимо извлечь файлы на диск C :.

Шаг 2: Добавьте переменные пути PIG_HOME и PIG_HOME bin
Нажмите кнопку Windows и в строке поиска введите «Переменные среды». Затем нажмите «Изменить системные переменные среды».

Затем нажмите «Переменные среды» в нижней части вкладки. Во вновь открытой вкладке нажмите кнопку «Создать» в разделе пользовательских переменных.
После нажатия нового Добавьте следующие значения в поля.
Variable Name - PIG_HOME Variable value - C:pig-0.17.0

Весь путь к извлеченной папке свиней в поле Variable Value. Я извлек его в каталог «C». Затем нажмите ОК.

Теперь нажмите на переменную Path в Системных переменных. Это откроет новую вкладку. Затем нажмите кнопку «Новый». И добавьте значение C: pig-0.17.0 bin в текстовое поле. Затем нажимайте ОК, пока все вкладки не закроются.

Шаг 3 : исправление командного файла Pig
Найдите файл pig.cmd в папке bin файла pig (C: pig-0.17.0 bin)
установить HADOOP_BIN_PATH =% HADOOP_HOME% bin
Найдите строку:
установить HADOOP_BIN_PATH =% HADOOP_HOME% bin
Замените эту строку на:
установить HADOOP_BIN_PATH =% HADOOP_HOME% libexec
И сохраните этот файл. Наконец-то мы здесь. Теперь вы готовы приступить к изучению Свиньи и ее окружающей среды.
Есть 2 способа вызвать оболочку grunt:
Локальный режим: все файлы устанавливаются, открываются и запускаются на самом локальном компьютере. Нет необходимости использовать HDFS. Команда для запуска Pig в локальном режиме выглядит следующим образом.
свинья -x местный

Режим MapReduce: все файлы находятся в HDFS. Нам нужно загрузить эти данные, чтобы обработать их. Команда для запуска Pig в режиме MapReduce / HDFS выглядит следующим образом.
свинья -x mapreduce

ПРИМЕР ИЗ ПРАКТИКИ Apache PIG:
1. Загрузите набор данных, содержащий данные, относящиеся к сельскому хозяйству, о сельскохозяйственных культурах в различных регионах, их площади и продукции. Ссылка на набор данных - https://www.kaggle.com/abhinand05/crop-production-in-india Набор данных содержит 7 столбцов, а именно:
State_Name: chararray; Название района: chararray; Crop_Year: int; Сезон: чараррей; Урожай: чараррей; Площадь: внутр .; Производство: int
Кол- во рядов: 246092 Кол-во столбцов : 7

2. Войдите в локальный режим скребка, используя
ворчание> свинья -x местный

3. Загрузите набор данных в локальном режиме.
grunt> сельское хозяйство = ЗАГРУЗИТЬ 'F: / csv files / crop_production.csv' с использованием PigStorage (',')
как (State_Name: chararray, District_Name: chararray, Crop_Year: int,
Сезон: chararray, Урожай: chararray, Площадь: int, Производство: int);
4. Сделайте дамп и опишите набор данных по сельскому хозяйству, используя
хрюканье> свалка земледелия; ворчание> опишите сельское хозяйство;

5. Выполнение запросов PIG в локальном режиме.
Вы можете следовать этим письменным запросам для анализа набора данных с помощью различных функций и операторов в PIG. Прежде чем продолжить, вам необходимо выполнить все вышеперечисленные шаги.
Запрос 1: Группировка всех записей по состоянию.
Эта команда сгруппирует все записи по столбцу State_Name.
grunt> statewisecrop = ГРУППА сельское хозяйство ПО ИМЕНИ СОСТОЯНИЯ; grunt> DUMP statewisecrop; grunt> ОПИСАТЬ statewisecrop;

Теперь сохраните результат запроса в файле CSV для лучшего понимания. Мы должны указать имя объекта и путь, по которому он должен быть сохранен.
путь -> 'F: / csv files / statewiseoutput' grunt> СОХРАНИТЬ statewisecrop В 'F: / csv files / statewiseoutput';

Результат будет в файле с именем «part-r-00000», который необходимо переименовать в « part-r-00000.csv », чтобы открыть его в формате Excel и сделать его читабельным. Вы найдете этот файл по пути, который мы указали в приведенном выше запросе. В моем случае это было по пути «F: / csv files / statewiseoutput /».
Выходной файл будет выглядеть примерно так:
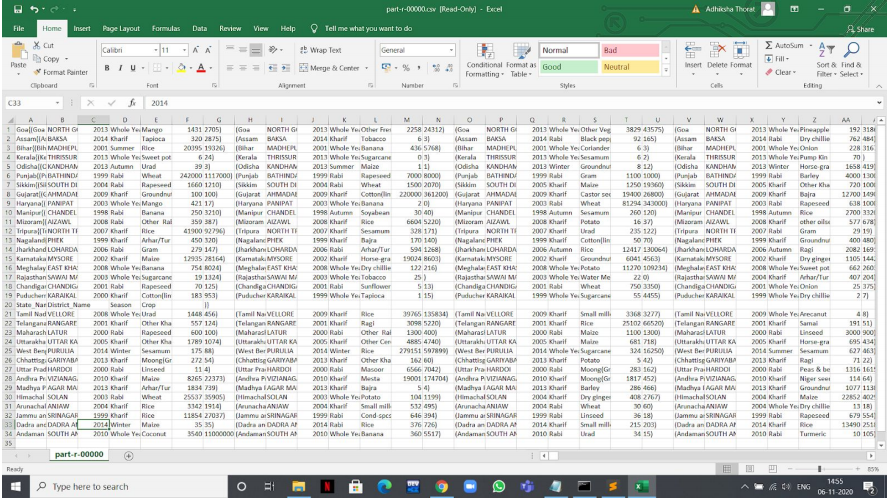
CSV-файл вывода запроса 1
Вы также можете проверить необработанный файл, открыв командную строку в режиме администратора и написав следующую команду.
C: Users Adhiksha > Head -2 'F: csv files statewiseoutput part-r-00000.csv';
Эта команда возвращает две верхние записи файла результатов вывода по состояниям. Выглядит примерно так.

Вывод запроса №1
Запрос 2: Генерация общего урожая с учетом производства и площадей
В приведенном выше запросе нам нужно сгруппировать по типу урожая, а затем найти СУММУ их продукции и площади.
grunt> cropinfo = FOREACH (ГРУППОВОЕ сельское хозяйство ПО Урожаям) GENERATE group AS Crop, SUM (сельское хозяйство.Площадь) как AreaPerCrop, СУМ (сельское хозяйство.Производство) как ProductionPerCrop; хрюкать> ОПИСАТЬ cropinfo;

grunt> СОХРАНИТЬ cropinfo В 'F: / csv files / cropinfooutput';
Результат будет в файле с именем «part-r-00000», который необходимо переименовать в «part-r-00000.csv», чтобы открыть его в формате Excel и сделать его читабельным.
Вы можете проверить вывод csv, открыв командную строку в режиме администратора и выполнив следующую команду.
C: Users> cat 'F: / csv files / cropinfooutput / part-r-00000.csv'
Это вернет весь вывод в командной строке. Вы можете видеть, что у нас есть три столбца на выходе.
Выход:
Обрезать , AreaperCrop, ProductionPerCrop.

Вопрос 3: большинство культур выращивается в сезон и в каком году.
В этом запросе нам нужно сгруппировать культуры по сезонам и расположить их в алфавитном порядке. Кроме того, это расскажет нам, какие культуры встречаются в сезоне и году.
grunt> seasoncrops = FOREACH (ГРУППОВОЕ сельское хозяйство по сезонам) {
order_crops = ЗАКАЗАТЬ сельское хозяйство ПО ASC урожая;
GENERATE группа AS Season, order_crops. (Crop) AS Crops;
};
grunt> ОПИСАТЬ сезонные культуры;

grunt> СОХРАНИТЬ сезонные урожаи В 'F: / csv files / seasonoutput;
Вывод будет в файле с именем «part-r-00000», который необходимо переименовать в «part-r-00000.csv», чтобы открыть его в формате Excel и сделать его читабельным. Вы можете проверить вывод csv, открыв командную строку в режиме администратора и выполнив следующую команду.
C: Users> cat 'F: / csv files / Seasonoutput / part-r-00000.csv'
Вы можете проверить вывод «part-r-00000.csv», открыв файл. Вы можете увидеть все отчетливые сезоны в первом ряду, за которыми следуют все культуры и годы их производства.
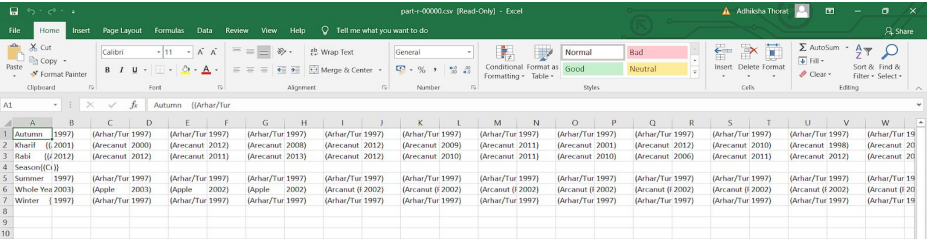
Вывод этого запроса номер 3
Вопрос 4: Средняя урожайность сельскохозяйственных культур в каждом районе после 2000 года.
Во-первых, нам нужно сгруппировать по названию района, а затем найти среднее значение от общего производства сельскохозяйственных культур, но только после 2000 года.
grunt> averagecrops = FOREACH (ГРУППА сельское хозяйство по имени района) {
after_year = ФИЛЬТР сельского хозяйства ПО ГОДУ урожая> 2000;
GENERATE group AS District_Name, AVG (after_year. (Производство)) AS
AvgProd;
};
хрюкать> ОПИСАТЬ средние урожаи;

grunt> СОХРАНИТЬ averagecrops В 'F: / csv files / averagecrops;
Вы можете проверить вывод «part-r-00000.csv», открыв файл. Этот файл будет содержать две колонки. Первый имеет все отдельные названия районов, а второй будет иметь среднее производство всех культур в каждом районе после 2000 года.
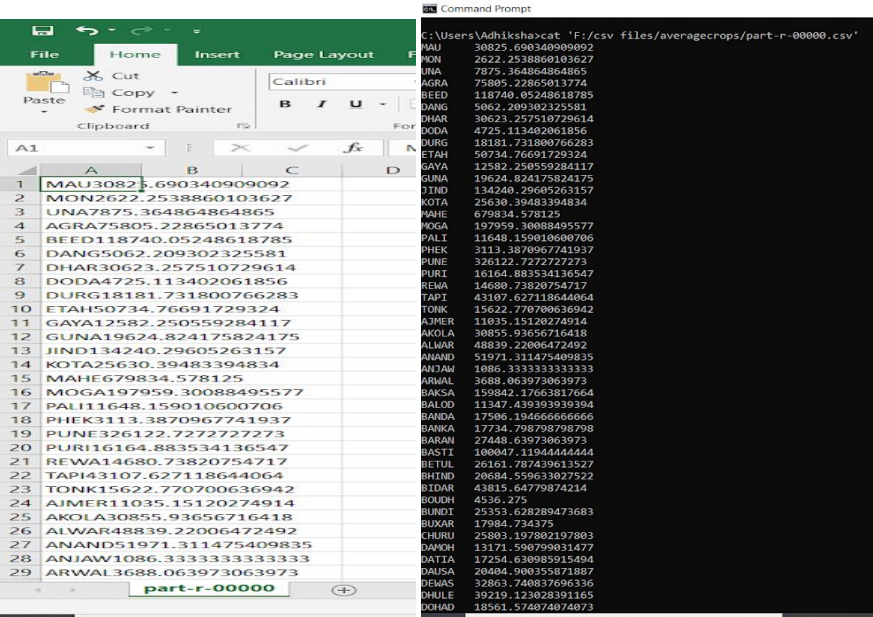
Вывод запроса № 4
Вопрос 5: самые высокие урожаи и подробная информация по каждому штату.
Во-первых, нам нужно сгруппировать ввод по имени состояния. Затем выполните итерацию по каждой сгруппированной записи, а затем найдите ТОП-1 запись с самым высоким уровнем производства в каждом состоянии.
grunt> top_agri = ГРУППА сельское хозяйство ПО ИМЕНИ СОСТОЯНИЯ;
grunt> data_top = FOREACH top_agri {
top = TOP (1, 6, сельское хозяйство);
СОЗДАТЬ вершину как запись;
}
хрюкать> ОПИСАТЬ cropinfo;
