Установка Apache Hive с базой данных Derby и Beeline
Apache Hive - это хранилище данных и мощный инструмент ETL (извлечение, преобразование и загрузка), построенный на основе Hadoop, который можно использовать с реляционными базами данных для управления и выполнения операций в СУБД. Он написан на Java и был выпущен Apache Foundation в 2012 году для людей, которые не очень хорошо знакомы с java. Hive использует язык HIVEQL, синтаксис которого очень похож на синтаксис SQL. HIVE поддерживает языки программирования C ++, Java и Python. Мы можем обрабатывать или запрашивать петабайты данных с помощью hive и SQL.
Derby также является инструментом реляционной базы данных с открытым исходным кодом, который поставляется с кустом (по умолчанию) и принадлежит apache. В настоящее время, с точки зрения отрасли, дерби используется только для целей тестирования, а для целей развертывания используется Metastore of MySqlis.
Предварительное условие: должен быть предварительно установлен Hadoop.
Шаг 1. Загрузите Hive версии 3.1.2 по этой ссылке.
Шаг 2: Поместите загруженный tar-файл в желаемое место (в нашем случае мы помещаем его в каталог / home).
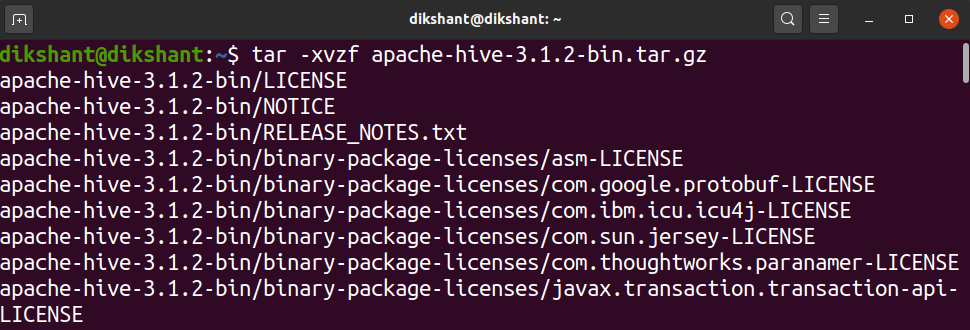
Шаг 3: Теперь извлеките tar-файл с помощью команды, показанной ниже.
tar -xvzf apache-hive-3.1.2-bin.tar.gz
Шаг 4: Теперь мы должны поместить путь к улью в файл .bashrc. Для этого используйте команду ниже.
sudo gedit ~ / .bashrc
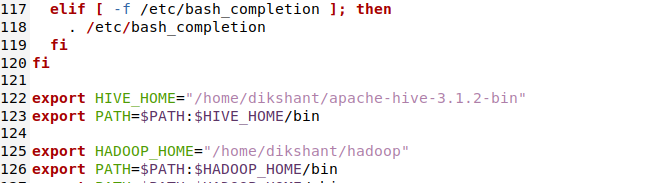
Путь к улью (добавьте правильный путь и название версии куста)
экспорт HIVE_HOME = "/ home / dikshant / apache-hive-3.1.2-bin" экспорт ПУТЬ = $ ПУТЬ: $ HIVE_HOME / bin
Поместите путь HIVE в этот файл .bashrc (не забудьте сохранить, нажмите CTRL + S). Для справки проверьте строки 122 и 123 на изображении ниже.
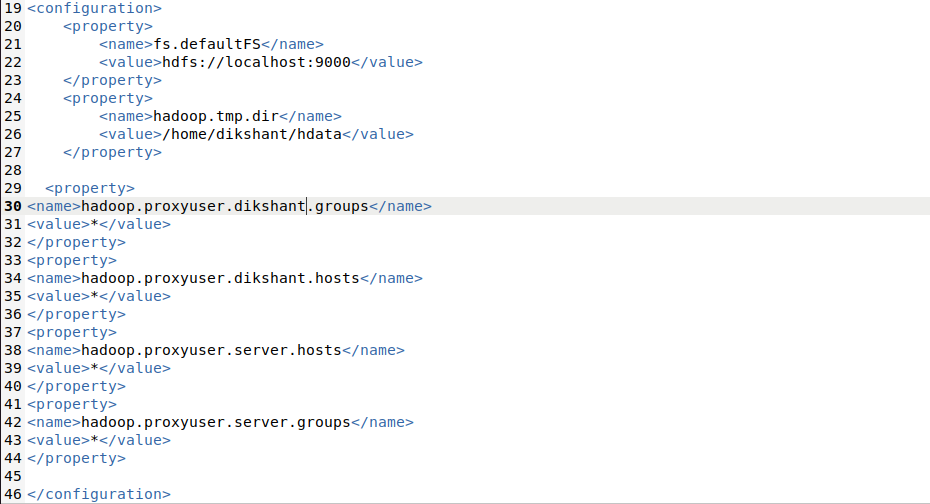
Шаг 5: Теперь добавьте указанное ниже свойство в файл core-site.xml. Мы можем найти файл в каталоге / home / {user-name} / hadoop / etc / hadoop . Для простоты мы переименовали мою папку hadoop-3.1.2 только в Hadoop.
# изменить каталог компакт-диск / домой / дикшант / hadoop / и т. д. / hadoop / # для вывода содержимого каталога ls # открыть и отредактировать core-site.xml sudo gedit core-site.xml
Свойство (не удаляйте ранее добавленные свойства Hadoop)
<собственность> <имя> hadoop.proxyuser.dikshant.groups </name> <value> * </value> </property> <собственность> <имя> hadoop.proxyuser.dikshant.hosts </name> <value> * </value> </property> <собственность> <имя> hadoop.proxyuser.server.hosts </name> <value> * </value> </property> <собственность> <имя> hadoop.proxyuser.server.groups </name> <value> * </value> </property>
Шаг 6: Теперь создайте каталог с именем / tmp в HDFS с помощью приведенной ниже команды.
hdfs dfs -mkdir / tmp

Шаг 7: Используйте приведенную ниже команду для создания хранилища, куста и пользовательского каталога, которые мы будем использовать для хранения наших таблиц и других данных.
hdfs dfs -mkdir / пользователь hdfs dfs -mkdir / пользователь / куст hdfs dfs -mkdir / пользователь / улей / склад

Теперь проверьте, успешно ли созданы каталоги с помощью приведенной ниже команды.
hdfs dfs -ls -R / #switch -R поможет -ls повторно отображать данные / (root) hdfs

Шаг 8: Теперь дайте разрешение на чтение, запись и выполнение всем пользователям этих созданных каталогов с помощью следующих команд.
hdfs dfs -chmod ugo + rwx / tmp hdfs dfs -chmod ugo + rwx / пользователь / улей / склад

Шаг 9: Перейдите в каталог /apache-hive-3.1.2-bin/conf и измените имя файла hive-default.xml.template на hive-site.xml . Теперь в этом файле перейдите к строке №. 3215 и удалите & # 8; потому что это приведет к ошибке при инициализации базы данных derby и, поскольку она присутствует в описании, для нас это не очень важно.
Потом,

Теперь,

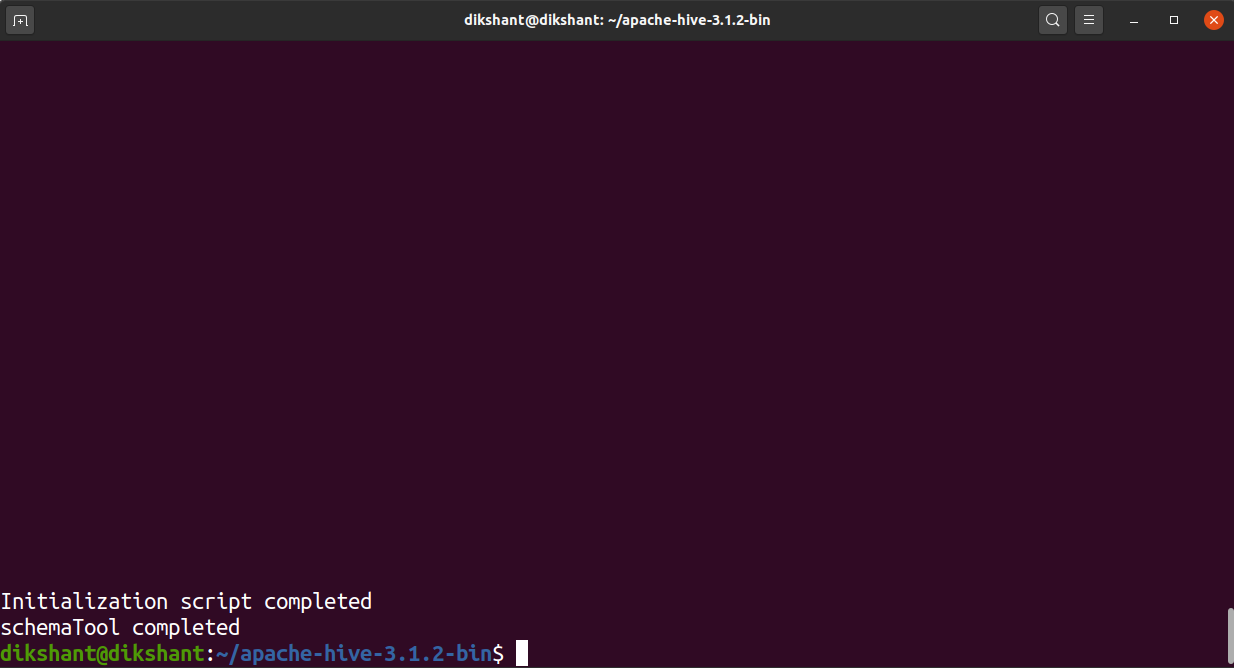
Шаг 10: Теперь инициализируйте базу данных derby, поскольку HIVE по умолчанию использует базу данных derby для хранения и других перспектив. Используйте приведенную ниже команду (убедитесь, что вы находитесь в каталоге apache-hive-3.1.2-bin).
bin / schematool -dbType derby -initSchema

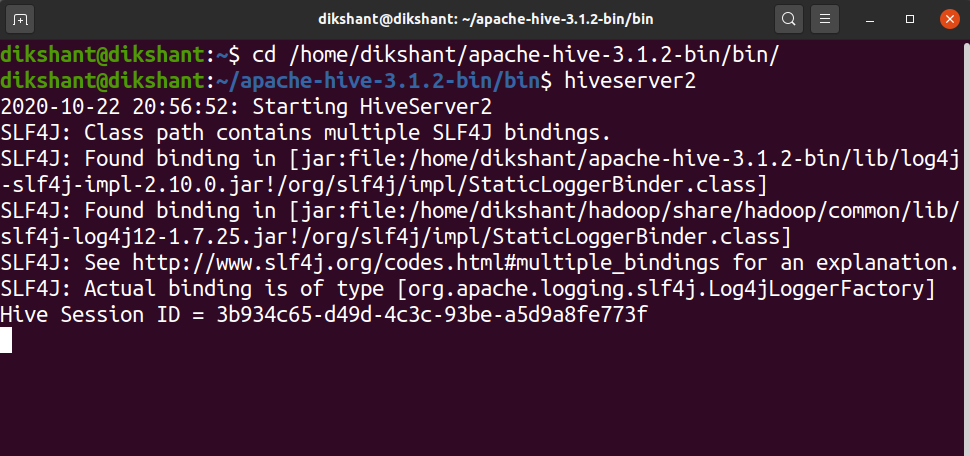
Шаг 11: Теперь запустите HiveServer2, используя следующую команду.
hiveserver2
Шаг 12: Введите следующие команды на другой вкладке, чтобы запустить командную оболочку beeline.
cd /home/dikshant/apache-hive-3.1.2-bin/bin/ beeline -n dikshant -u jdbc: hive2: // localhost: 10000 (Если у вас возникнут проблемы, попробуйте использовать hadoop вместо вашего имени пользователя)
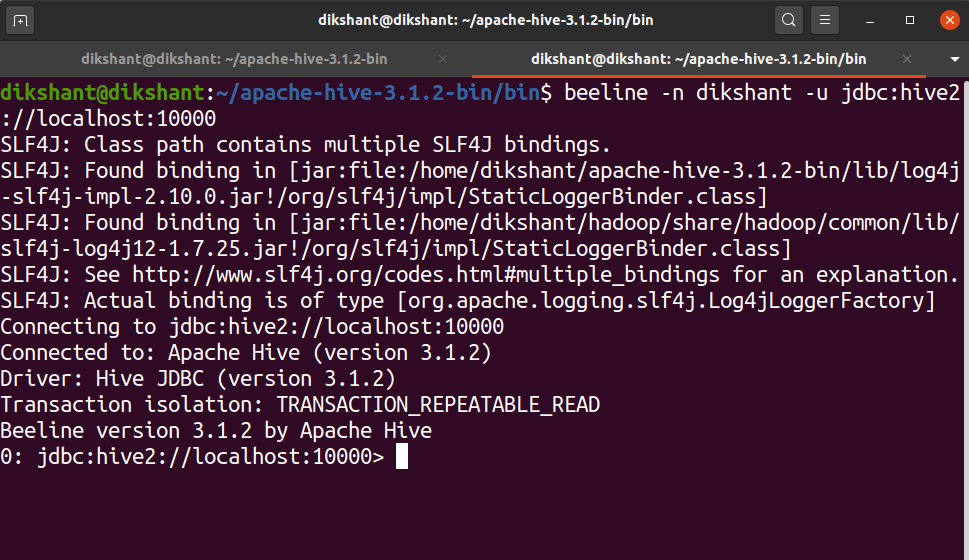
Теперь мы успешно настроили и установили apache hive с базой данных derby.
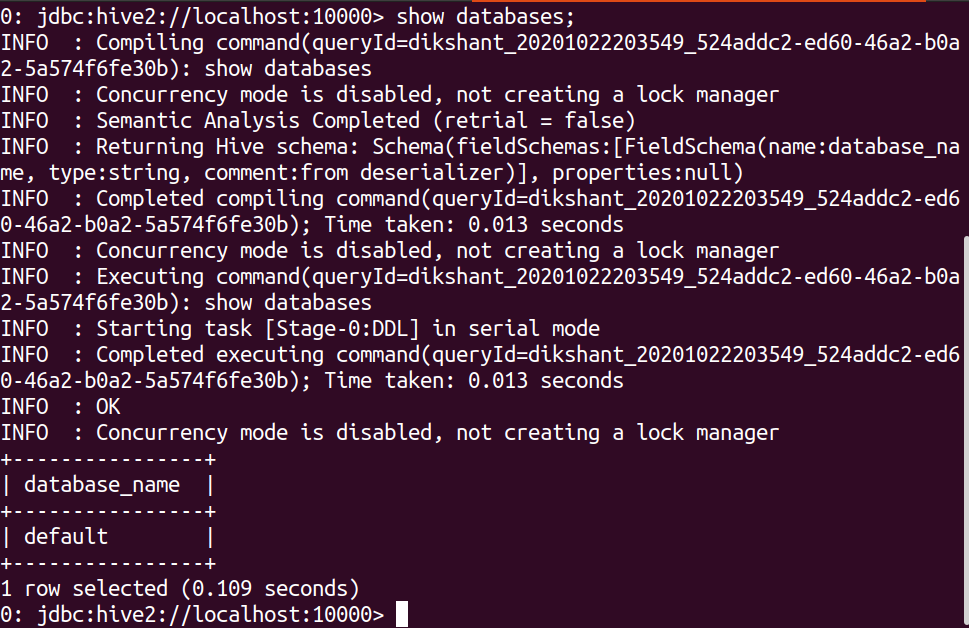
Шаг 13: Давайте воспользуемся командой show databases, чтобы проверить, работает она или нет.
показать базы данных;