Улей - Drop Table
Apache hive - это инструмент для хранения данных, который мы используем для управления нашими структурными данными в Hadoop. Таблицы в улье используются для хранения данных в табличном формате (структурированном). У Hive очень много возможностей, так что он может запрашивать петабайты записей, хранящихся в таблице улья.
Команда DROP TABLE в улье используется для удаления таблицы внутри улья. Hive удалит все свои данные и метаданные из мета-хранилища улья. Оператор Hive DROP TABLE имеет параметр PURGE. В случае, если упомянута опция PURGE, данные будут полностью потеряны и не могут быть восстановлены позже, но если не упомянута, то данные будут перемещены в каталог .Trash / current .
Синтаксис:
УДАЛИТЬ ТАБЛИЦУ [ЕСЛИ СУЩЕСТВУЕТ] имя_таблицы [ОЧИСТКА];
Пример:
Чтобы выполнить описанную ниже операцию, убедитесь, что ваш улей работает. Ниже приведены инструкции по запуску куста в вашей локальной системе.
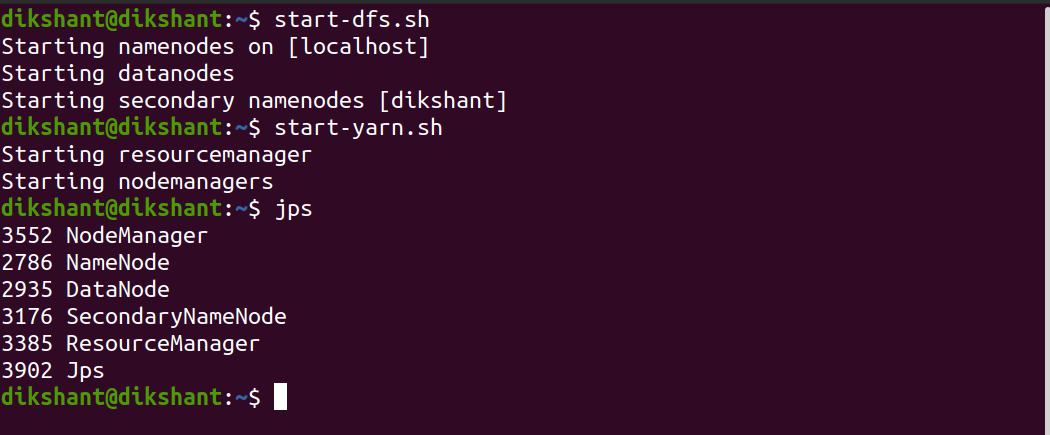
Шаг 1. Запустите все свои Hadoop Daemon
start-dfs.sh # это запустит namenode, datanode и вторичный namenode start-yarn.sh # это запустит диспетчер узлов и диспетчер ресурсов jps # Чтобы проверить запущенные демоны
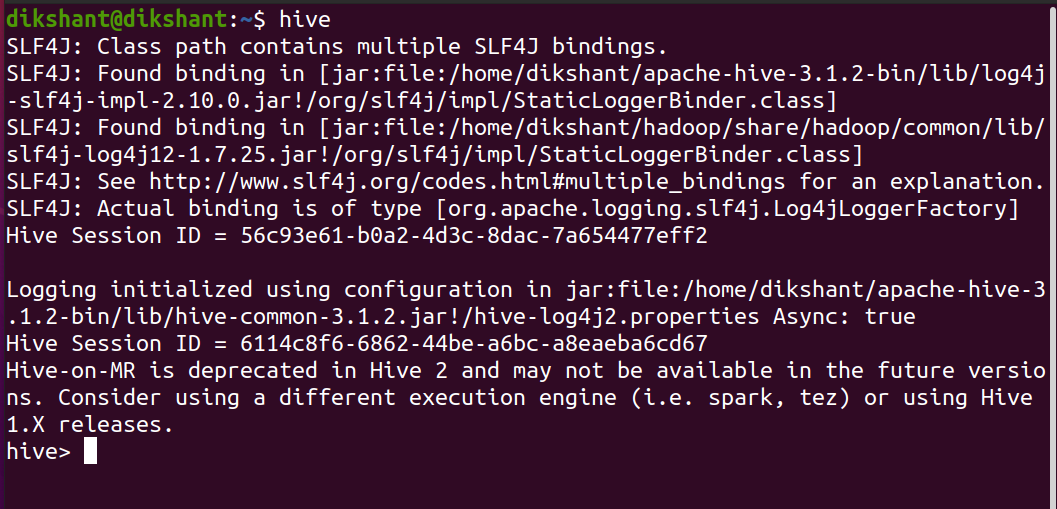
Шаг 2: запустите Hive
улей
Давайте сначала создадим таблицу в кусте с помощью приведенной ниже команды, чтобы мы могли УДАЛИТЬ ее с помощью оператора DROP TABLE. В нашем примере мы не указываем имя базы данных, поэтому hive будет использовать свою базу данных по умолчанию.
Команда:
СОЗДАТЬ ТАБЛИЦУ данные ( Имя STRING, Контакты Нет BIGINT) ФОРМАТ СТРОКИ УДАЛЕН ПОЛЯ, ЗАКОНЧЕННЫЕ ',';
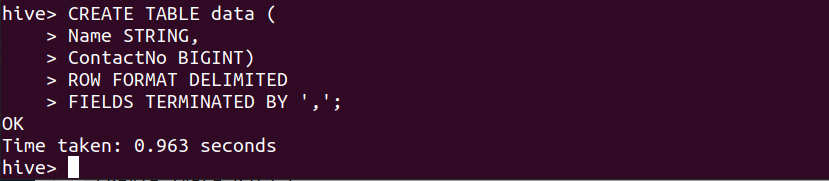
Мы успешно создали таблицу данных в базе данных по умолчанию улья. Ниже приведена команда для проверки
Синтаксис:
ПОКАЗАТЬ ТАБЛИЦЫ В <имя-базы-данных>;
Команда:
показывать таблицы по умолчанию;

ТАБЛИЦА ПАРАМЕТРОВ в Hive
С помощью приведенной ниже команды все содержимое таблицы данных будет удалено навсегда, потому что я использовал параметр PURGE с командой DROP TABLE.
Команда:
УДАЛИТЬ ТАБЛИЦУ, ЕСЛИ СУЩЕСТВУЕТ ОЧИСТКА данных;

Таблица успешно удалена.