Программа MapReduce - определение среднего возраста мужчин и женщин, погибших в катастрофе "Титаник"
Все мы знакомы с катастрофой, случившейся 14 апреля 1912 года. Большой гигантский корабль весом 46000 тонн затонул на глубине 13000 футов в северной части Атлантического океана. Наша цель - проанализировать данные, полученные после этой катастрофы. Hadoop MapReduce можно использовать для эффективной работы с этими большими наборами данных, чтобы найти любое решение для конкретной проблемы.
Постановка проблемы: анализ набора данных Titanic Disaster для определения среднего возраста мужчин и женщин, погибших в этой катастрофе, с помощью MapReduce Hadoop.
Шаг 1:
Мы можем скачать Titanic Dataset по этой ссылке. Ниже представлена структура столбцов нашего набора данных Titanic. Он состоит из 12 столбцов, каждая строка которых описывает информацию о конкретном человеке.

Шаг 2:
Первые 10 записей набора данных показаны ниже.

Шаг 3:
Make the project in Eclipse with below steps:
- First Open Eclipse -> then select File -> New -> Java Project ->Name it Titanic_Data_Analysis -> then select use an execution environment -> choose JavaSE-1.8 then next -> Finish.
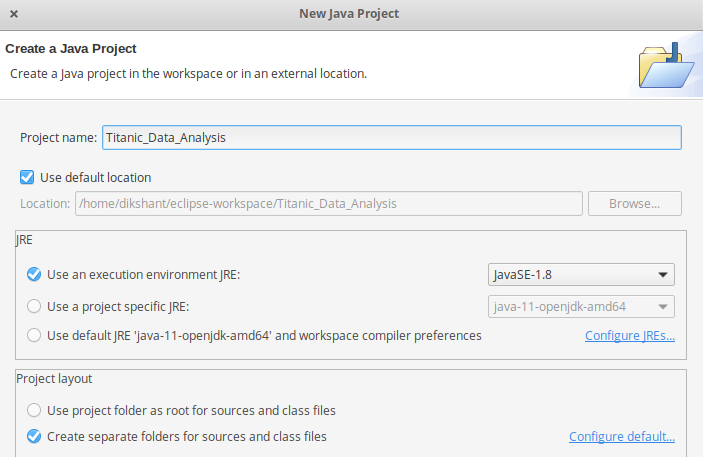
- In this Project Create Java class with name Average_age -> then click Finish
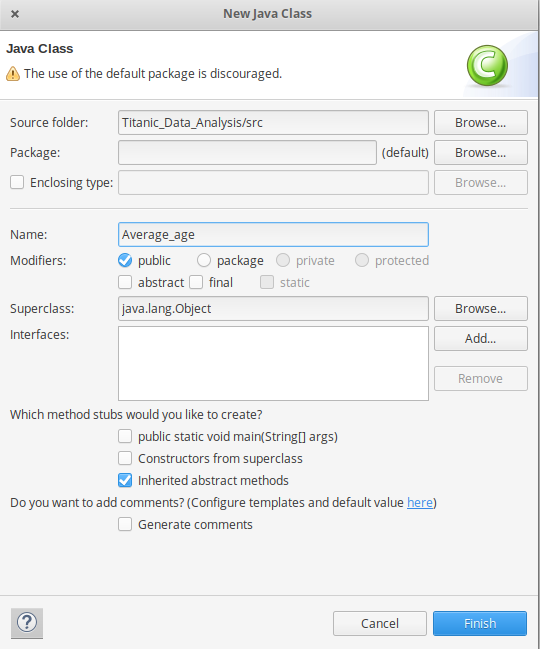
- Copy the below source code to this Average_age java class
// import librariesimportjava.io.IOException;importorg.apache.hadoop.fs.Path;importorg.apache.hadoop.conf.*;importorg.apache.hadoop.io.*;importorg.apache.hadoop.mapreduce.*;importorg.apache.hadoop.mapreduce.lib.input.FileInputFormat;importorg.apache.hadoop.mapreduce.lib.input.TextInputFormat;importorg.apache.hadoop.mapreduce.lib.output.FileOutputFormat;importorg.apache.hadoop.mapreduce.lib.output.TextOutputFormat;// Making a class with name Average_agepublicclassAverage_age {publicstaticclassMapextendsMapper<LongWritable, Text, Text, IntWritable> {// private text gender variable which// stores the gender of the person// who died in the Titanic DisasterprivateText gender =newText();// private IntWritable variable age will store// the age of the person for MapReduce. where// key is gender and value is ageprivateIntWritable age =newIntWritable();// overriding map method(run for one time for each record in dataset)publicvoidmap(LongWritable key, Text value, Context context)throwsIOException, InterruptedException{// storing the complete record// in a variable name lineString line = value.toString();// spliting the line with ", " as the// values are separated with this// delimiterString str[] = line.split(", ");/* checking for the condition where thenumber of columns in our datasethas to be more than 6. This helps ineliminating the ArrayIndexOutOfBoundsExceptionwhen the data sometimes is incorrectin our dataset*/if(str.length >6) {// storing the gender// which is in 5th columngender.set(str[4]);// checking the 2nd column value in// our dataset, if the person is// died then proceed.if((str[1].equals("0"))) {// checking for numeric data with// the regular expression in this columnif(str[5].matches("\d+")) {// converting the numeric// data to INT by typecastinginti = Integer.parseInt(str[5]);// storing the person of ageage.set(i);}}}// writing key and value to the context// which will be output of our map phasecontext.write(gender, age);}}publicstaticclassReduceextendsReducer<Text, IntWritable, Text, IntWritable> {// overriding reduce method(runs each time for every key )publicvoidreduce(Text key, Iterable<IntWritable> values, Context context)throwsIOException, InterruptedException{// declaring the variable sum which// will store the sum of ages of peopleintsum =0;// Variable l keeps incrementing for// all the value of that key.intl =0;// foreach loopfor(IntWritable val : values) {l +=1;// storing and calculating// sum of valuessum += val.get();}sum = sum / l;context.write(key,newIntWritable(sum));}}publicstaticvoidmain(String[] args)throwsException{Configuration conf =newConfiguration();@SuppressWarnings("deprecation")Job job =newJob(conf,"Averageage_survived");job.setJarByClass(Average_age.class);job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(IntWritable.class);// job.setNumReduceTasks(0);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);job.setMapperClass(Map.class);job.setReducerClass(Reduce.class);job.setInputFormatClass(TextInputFormat.class);job.setOutputFormatClass(TextOutputFormat.class);FileInputFormat.addInputPath(job,newPath(args[0]));FileOutputFormat.setOutputPath(job,newPath(args[1]));Path out =newPath(args[1]);out.getFileSystem(conf).delete(out);job.waitForCompletion(true);}} - Now we need to add external jar for the packages that we have import. Download the jar package Hadoop Common and Hadoop MapReduce Core according to your Hadoop version.
Check Hadoop Version :
hadoop version

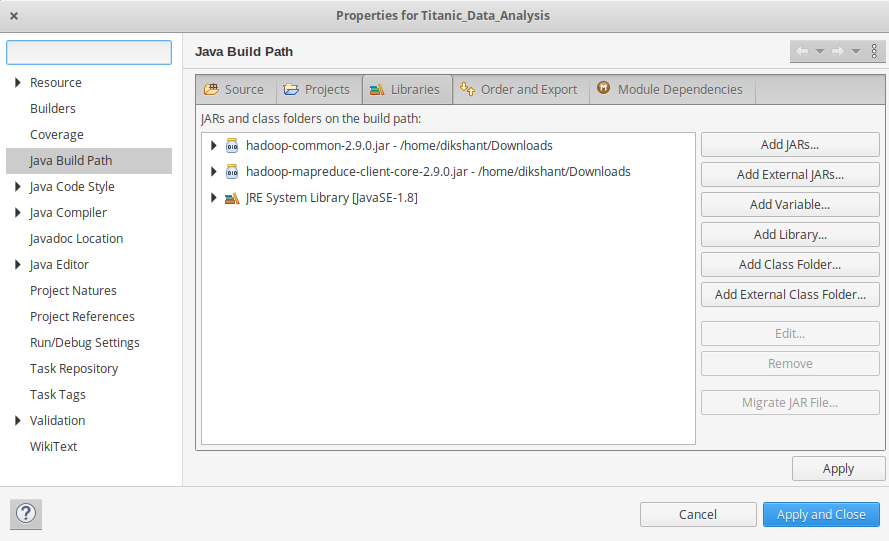
- Now we add these external jars to our Titanic_Data_Analysis project. Right Click on Titanic_Data_Analysis -> then select Build Path-> Click on Configue Build Path and select Add External jars…. and add jars from it’s download location then click -> Apply and Close.
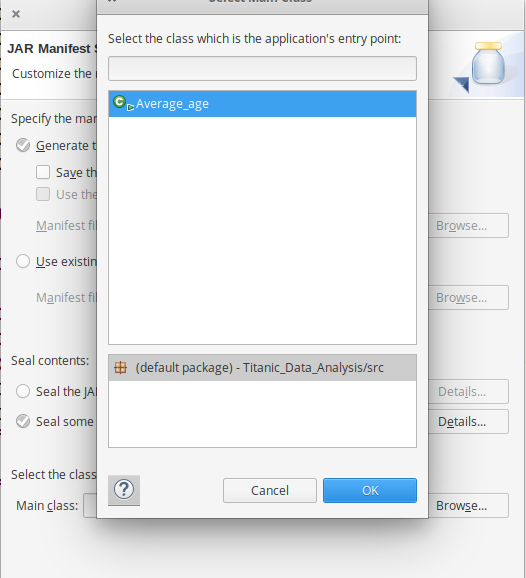
- Now export the project as jar file. Right-click on Titanic_Data_Analysis choose Export.. and go to Java -> JAR file click -> Next and choose your export destination then click -> Next. Choose Main Class as Average_age by clicking -> Browse and then click -> Finish -> Ok.

Step 4:
Start Hadoop Daemons
start-dfs.sh
start-yarn.sh
Then, Check Running Hadoop Daemons.
jps
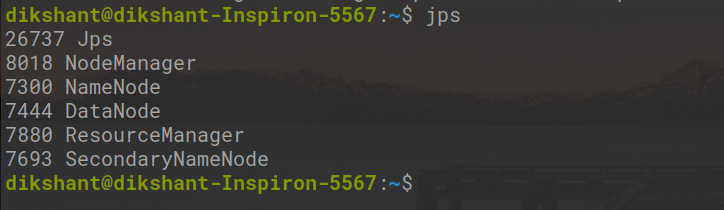
Step 5:
Move your dataset to the Hadoop HDFS.
Syntax:
hdfs dfs -put /file_path /destination
In below command / shows the root directory of our HDFS.
hdfs dfs -put /home/dikshant/Documents/titanic_data.txt /
Check the file sent to our HDFS.
hdfs dfs -ls /

Step 6:
Now Run your Jar File with below command and produce the output in Titanic_Output File.
Syntax:
hadoop jar /jar_file_location /dataset_location_in_HDFS /output-file_name
Command:
hadoop jar /home/dikshant/Documents/Average_age.jar /titanic_data.txt /Titanic_Output
Step 7:
Now Move to localhost:50070/, under utilities select Browse the file system and download part-r-00000 in /MyOutput directory to see result.
Note: We can also view the result with below command
hdfs dfs -cat /Titanic_Output/part-r-00000

In the above image, we can see that the average age of the female is 28 and male is 30 according to our dataset who died in the Titanic Disaster.