Преобразователь преобразования текста в текст в расширении данных
- Вы хотите достичь самых современных результатов в своем следующем проекте НЛП?
- Недостаточно ли ваших данных для обучения модели машинного обучения?
- Вы хотите повысить точность своей модели машинного обучения с помощью дополнительных данных?
Если да, все, что вам нужно, это расширение данных . Создаете ли вы классификацию текста, обобщение, ответы на вопросы или любую другую модель машинного обучения. Расширение данных поможет повысить производительность вашей модели.
Есть пять методов увеличения данных:
- Вложения слов
- БЕРТ
- Обратный перевод
- Преобразователь текста в текст
- Ансамблевый подход.
Преобразователь текста в текст:
Увеличение данных с помощью преобразователя передачи текста в текст (T5) - это большая модель преобразователя, обученная на наборе данных Colossal Clean Crawled Corpus (C4). Google предоставил открытый исходный код предварительно обученной модели T5, которая способна выполнять несколько задач, таких как перевод, обобщение, ответы на вопросы и классификация.
T5 reframes every NLP task into text to text format.
- Пример 1 : Модель T5 можно обучить для перевода с английского на немецкий с помощью Input translate text English to German, English text и German text as output.
- Пример 2: Чтобы обучить модель классификации тональности, входными данными может быть классификация тональности, входным текстом, а в качестве выходных данных может быть тональность.
Одну и ту же модель можно обучить для нескольких задач, задав разные задачи. Конкретная строка префикса во входных обучающих данных. T5 добился передовых результатов по множеству задач НЛП.
Как использовать эту модель для увеличения данных?
Это можно сделать несколькими способами.
В обратном переводе мы использовали предварительно обученные модели из коробки. Если мы хотим использовать T5 из коробки, мы можем использовать его возможности текстового резюмирования для увеличения данных.
- T5 может принимать ввод в формате, резюмировать, вводить текст и генерировать резюме ввода.
- T5 - это абстрактный алгоритм реферирования.
- T5 может перефразировать предложения или использовать новые слова для составления резюме.
- Техника увеличения данных T5 полезна для задач НЛП, связанных с длинными текстовыми документами.
Для короткого текста это может дать не очень хорошие результаты.
Другой подход к использованию T5 для увеличения данных заключается в использовании техники передачи обучения и использовании знаний, хранящихся в T5, для генерации синтетических данных. Это можно сделать несколькими способами.
1) Один из способов - точно настроить T5 на задачу предсказания замаскированного слова, на которой обучается BERT.
Точная настройка данных в задаче прогнозирования замаскированных слов
Мы можем использовать тот же набор данных C4, на котором предварительно обучен T5, для дальнейшей тонкой настройки его для предсказания замаскированных слов . Таким образом, вход в модель будет начинаться с некоторого префикса, такого как маска прогноза, за которым следует входное предложение, содержащее замаскированное слово, а на выходе будет исходное предложение без маски.
Мы также можем замаскировать несколько слов в одном предложении и обучить T5 предсказывать объем слов . Если мы замаскируем одно слово, модель не сможет генерировать новые данные с вариациями в структуре предложения. Но если мы замаскируем несколько слов, модель может научиться генерировать данные с небольшими вариациями в структуре предложения. Таким образом, наш подход к увеличению данных будет очень похож на подход, основанный на BERT.
2) Другой способ использовать T5 для увеличения данных - настроить его на перефразированную задачу генерации .
Перефразирование означает создание выходного предложения, которое имеет то же значение, что и входное, но с другой структурой предложения и ключевым словом. Это именно то, что нам нужно для пополнения данных.
Мы собираемся использовать набор данных PAWS, чтобы найти мелодию T5 для генерации перефразирования. PAWS означает перефразирование противников из шифрования слов. Этот набор данных содержит тысячи перефразировок и доступен на шести языках, кроме английского.
Итак, наш подход к увеличению данных с использованием T5 будет следующим:
Шаг 1. Включите некоторую предварительную обработку данных, которая преобразует набор данных PAWS в формат, необходимый для обучения T5.
Шаг 2: Следующим шагом будет точная настройка, T5. Для точной настройки наши входные данные для модели будут в формате, сгенерировать перефразированный входной текст, а выходные данные будут перефразированием входного текста.
Как только у нас будет точная настройка модели, мы можем использовать ее для генерации перефразирования любого входного текста. Мы можем предоставить ввод с префиксом генерировать парафраз, и модель выведет его перефразирование.
Модель может быть настроена на вывод нескольких перефразирований. Таким образом, мы можем очень легко создать нашу собственную модель генерации перефразирования для увеличения данных.
Предварительно обученная модель T5 доступна в пяти различных размерах.
- T5 Small (60M Params)
- База T5 (220 параметров)
- T5 большой (770 параметров)
- T5 3 B (3 параметра B)
- T5 11 B (11 B Params)
Модель большего размера дает лучшие результаты, но также требует большей вычислительной мощности и требует много времени на обучение. Но это разовый процесс. После того, как у вас будет качественно настроенная модель генерации перефразирования, обученная на соответствующем наборе данных, ее можно будет использовать для увеличения данных в нескольких задачах НЛП.
Реализация увеличения данных с использованием T5
Мы собираемся реализовать расширение данных с помощью преобразователя передачи текста в текст с помощью библиотеки простых преобразователей. Эта библиотека основана на библиотеке трансформеров Hugging Face. Это упрощает точную настройку моделей на основе трансформаторов.
- Шаг 1. Мы собираемся загрузить набор данных PAWS (перефразируя противников из шифрования слов), который нам нужен для точной настройки.
- Шаг 2: Нам нужно подготовить набор данных для обучения, чтобы мы могли начать точную настройку модели.
- Шаг 3: Мы создадим и сохраним настроенную модель на Google Диске.
- Шаг 4: Наконец, мы загрузим сохраненную модель и сгенерируем пересказы, которые можно использовать для увеличения данных.
1) Установить зависимости
Python3
!pip install simpletransformers import pandas as pdfrom simpletransformers.t5 import T5Modelfrom pprint import pprintimport logging |
2) Подготовьте набор данных для обучения
Вы можете скачать набор данных по этой ссылке PAWS wiki, помеченной набором данных. В нем есть три файла: train , dev и test.tsv . Мы будем использовать только файлы train и dev. Этот набор данных состоит из трех столбцов: первого предложения, второго предложения и метки. Ярлык - это одно из двух предложений, являющихся перефразированием, и ноль в противном случае.
Python
df = pd.read_csv( 'train.tsv' ,sep = ' ' )df.head( 5 ) |

Когда можно поддерживать сравнимую скорость потока , результаты высоки. Соответствующее предложение2 показывает, что результаты являются высокими, когда можно поддерживать сопоставимые скорости потока. Эти два предложения являются перефразированием, поэтому ярлык один.
Мы собираемся настроить T5 для генерации перефразирования. Так что нам нужны только перефразировки из этого набора данных. Это означает, что для нашей задачи пригодны только образцы, помеченные как один.
Python
df.describe() |
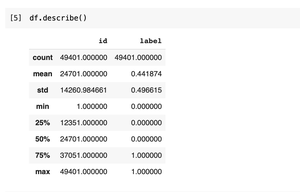
Размер этого набора данных - 49401.
Оставим только те пары, у которых есть метка один.
Python
paraphrase_train = df[df[ 'label' ] = = 1 ]paraphrase_train.head( 5 )paraphrase_train.describe() |

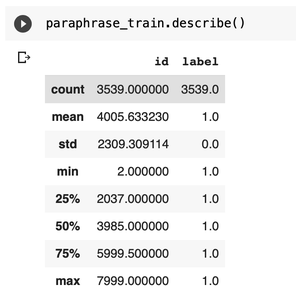
Теперь размер уменьшен почти вдвое. T5 можно обучить нескольким задачам. Поэтому при вводе данных в модель нам нужно добавить префикс для конкретной задачи. Для этого мы добавляем новый префикс столбца в наш фрейм данных с перефразированием сгенерированного значения.
Нам нужно также переименовать первое предложение и предложение с двумя столбцами. Обратите внимание, что переименование должно быть «input_text» и «target_text», иначе будет отображаться ошибка времени выполнения.
Python
paraphrase_train[ "prefix" ] = "Generate Paraphrase for this line"paraphrase_train = paraphrase_train.rename( columns = { "sentence1" : "input_text" , "sentence2" : "target_text" }) |
Те же шаги, нам нужно применить к dev.tsv.
Python
df = pd.read_csv( 'dev.tsv' ,sep = ' ' )paraphrase_dev = df[df[ 'label' ] = = 1 ]paraphrase_dev[ "prefix" ] = "Generate Paraphrase for this line"paraphrase_dev = paraphrase_dev.rename( columns = { "sentence1" : "input_text" , "sentence2" : "target_text" }) |
3) Точная настройка T5 для генерации перефразирования
Во-первых, нам нужно определиться с некоторыми параметрами конфигурации. Вы можете просмотреть документацию Simple Transformer, чтобы понять все эти параметры.
Последний параметр - определить, сколько перефразирований генерировать для каждого ввода. Перефразирование генерируется с использованием комбинации выборки top-k и выборки ядра top-p .
Чтобы создать объект класса модели T5, нам необходимо передать параметры конфигурации и тип модели T5. T5 доступен в нескольких размерах, мы собираемся использовать маленькую версию T5.
Python
model_args = { "reprocess_input_data" : True , "overwrite_output_dir" : True , "max_seq_length" : 128 , "train_batch_size" : 16 , "num_train_epochs" : 10 , "num_beams" : None , "do_sample" : True , "max_length" : 20 , "top_k" : 50 , "top_p" : 0.95 , "use_multiprocessing" : False , "save_steps" : - 1 , "save_eval_checkpoints" : True , "evaluate_during_training" : True , "evaluate_during_training_verbose" : True , "num_return_sequences" : 5} |
Python
model = T5Model( "t5" , "t5-small" , args = model_args)model.train_model(paraphrase_train, eval_data = paraphrase_dev) |


Сохранение лучшей модели на гугл диск:
Python
/ / import drivefrom drive import google.colabdrive.mount( '/content/gdrive' ) / / copy path of best_model!cp - r / content / outputs / best_model / / content / gdrive / 'My Drive' / T5 / / / load modelpre_trained_model = T5Model( "/content/gdrive/My Drive/T5/best_model" , model_args) |
4) Сгенерируйте перефразирование, набрав префикс как «Создать пересказ для этой строки».

В некоторых случаях это может не дать хороших результатов, но есть много возможностей для улучшения модели вместо использования маленькой версии T5. Если мы воспользуемся более крупной версией и настроим ее на более крупном наборе данных, мы сможем получить гораздо лучшие результаты.
Кроме того, вы можете перейти в репозиторий модели обнимающего лица и найти там T5. Вы можете найти какую-то модель T5, настроенную на генерацию перефразирования. Вы также можете опробовать эти модели или дополнительно настроить их в своем наборе данных для конкретной предметной области.
В этом преимущество этой техники увеличения данных.