Потоковая передача Hadoop с использованием Python - проблема подсчета слов
Hadoop Streaming - это функция, которая поставляется с Hadoop и позволяет пользователям или разработчикам использовать различные языки для написания программ MapReduce, таких как Python, C ++, Ruby и т. Д. Он поддерживает все языки, которые могут читать из стандартного ввода и записывать в стандартный вывод. Мы будем реализовывать Python с Hadoop Streaming и посмотрим, как это работает. Мы реализуем проблему подсчета слов в Python, чтобы понять Hadoop Streaming. Мы будем создавать mapper.py и reducer.py для выполнения задач сопоставления и сокращения.
Давайте создадим один файл, содержащий несколько слов, которые мы можем сосчитать.
Шаг 1: Создайте файл с именем word_count_data.txt и добавьте в него данные.
cd Documents / #, чтобы изменить каталог на / Documents touch word_count_data.txt # touch используется для создания пустого файла nano word_count_data.txt # nano - редактор командной строки для редактирования файла cat word_count_data.txt # cat используется для просмотра содержимого файла

Шаг 2: Создайте файл mapper.py , реализующий логику сопоставителя. Он будет читать данные из STDIN, разбивать строки на слова и генерировать вывод каждого слова с его индивидуальным счетчиком.
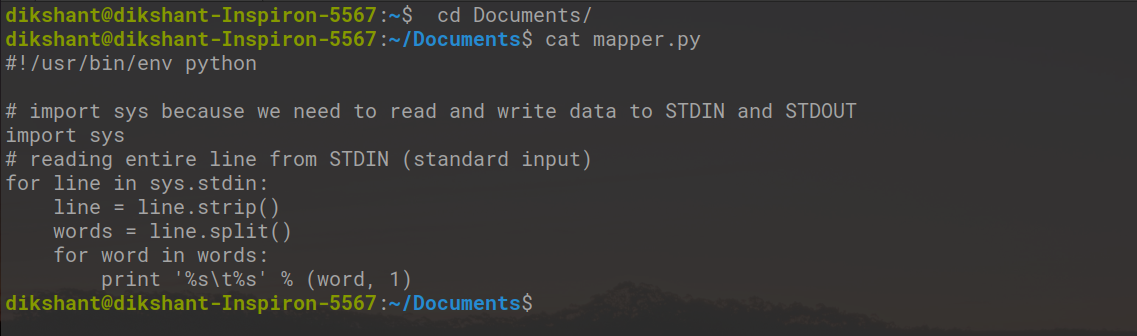
cd Documents/ # to change the directory to /Documents touch mapper.py # touch is used to create an empty file cat mapper.py # cat is used to see the content of the file
Copy the below code to the mapper.py file.
Python3
#!/usr/bin/env python # import sys because we need to read and write data to STDIN and STDOUTimport sys # reading entire line from STDIN (standard input)for line in sys.stdin: # to remove leading and trailing whitespace line = line.strip() # split the line into words words = line.split() # we are looping over the words array and printing the word # with the count of 1 to the STDOUT for word in words: # write the results to STDOUT (standard output); # what we output here will be the input for the # Reduce step, i.e. the input for reducer.py print "%s %s" % (word, 1) |
Здесь в программе выше #! известен как shebang и используется для интерпретации сценария. Файл будет запущен с использованием указанной нами команды.
Давайте проверим наш mapper.py локально, работает он нормально или нет.
Синтаксис:
cat <text_data_file> | python <mapper_code_python_file>
Команда (в моем случае)
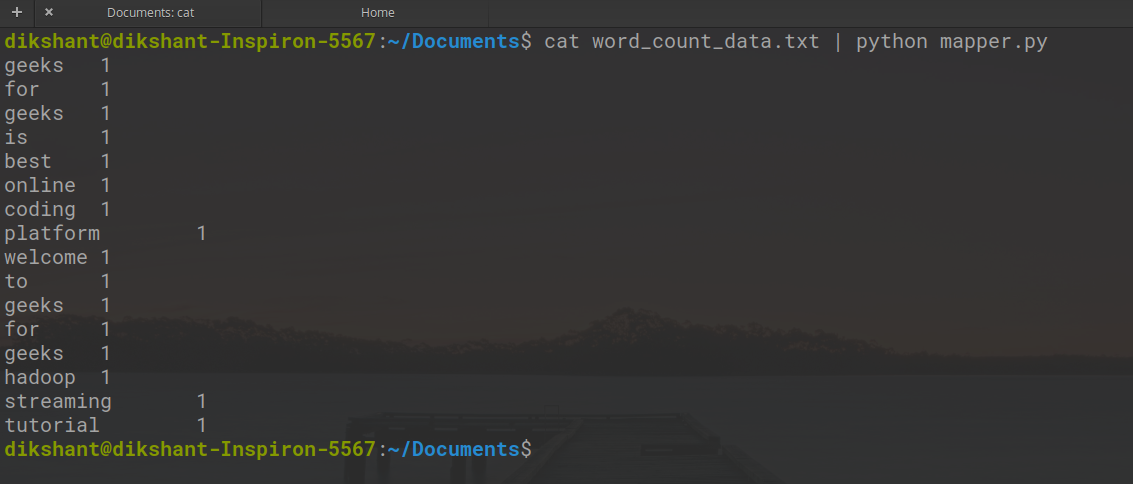
кот word_count_data.txt | python mapper.py
Результат работы картографа показан ниже.
Step 3: Create a reducer.py file that implements the reducer logic. It will read the output of mapper.py from STDIN(standard input) and will aggregate the occurrence of each word and will write the final output to STDOUT.
cd Documents/ # to change the directory to /Documents touch reducer.py # touch is used to create an empty file
Python3
#!/usr/bin/env python from operator import itemgetterimport sys current_word = Nonecurrent_count = 0word = None # read the entire line from STDINfor line in sys.stdin: # remove leading and trailing whitespace line = line.strip() # slpiting the data on the basis of tab we have provided in mapper.py word, count = line.split(" ", 1) # convert count (currently a string) to int try: count = int(count) except ValueError: # count was not a number, so silently # ignore/discard this line continue # this IF-switch only works because Hadoop sorts map output # by key (here: word) before it is passed to the reducer if current_word == word: current_count += count else: if current_word: # write result to STDOUT print "%s %s" % (current_word, current_count) current_count = count current_word = word # do not forget to output the last word if needed!if current_word == word: print "%s %s" % (current_word, current_count) |
Теперь давайте проверим наш код редуктора reducer.py с помощью mapper.py, правильно он работает или нет, с помощью следующей команды.
кот word_count_data.txt | python mapper.py | sort -k1,1 | python reducer.py
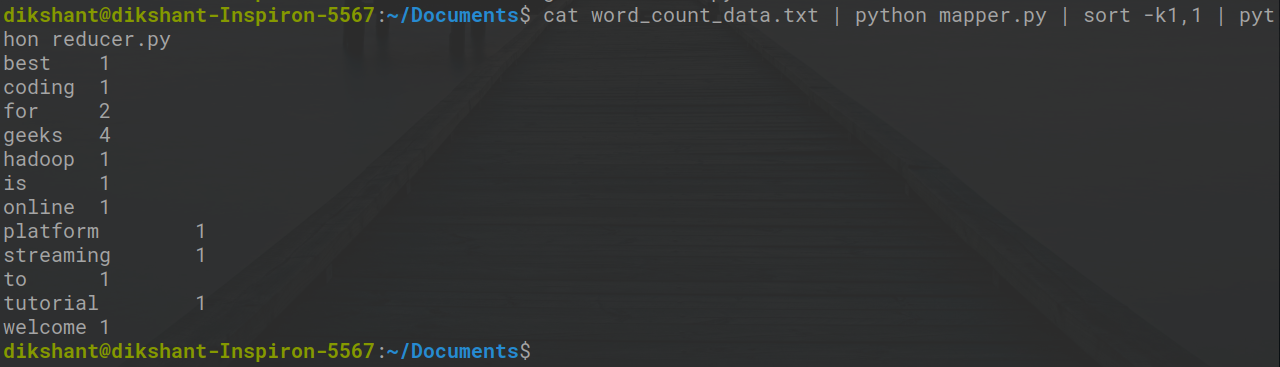
Мы видим, что наш редуктор также отлично работает в нашей локальной системе.
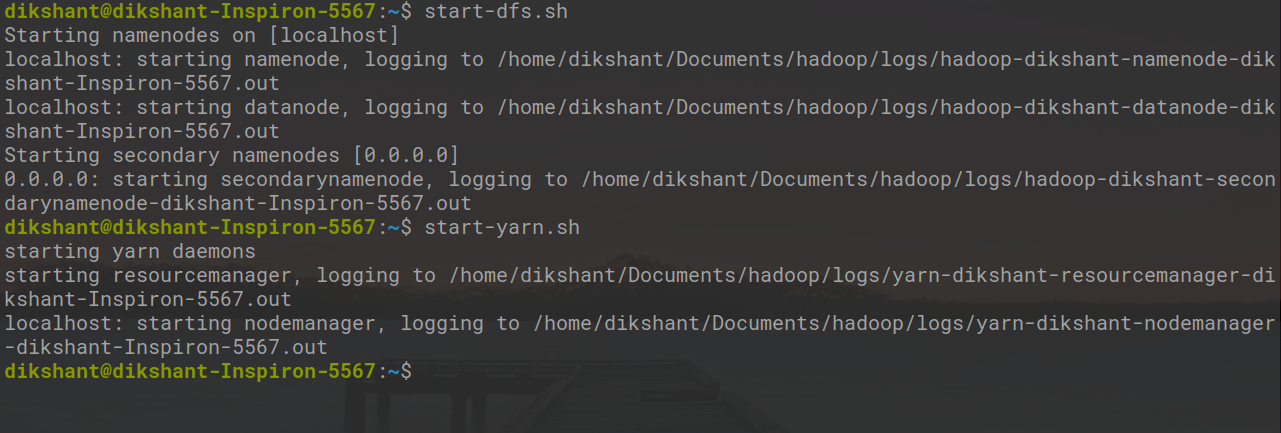
Шаг 4: Теперь давайте запустим все наши демоны Hadoop с помощью следующей команды.
start-dfs.sh start-yarn.sh
Теперь создайте каталог word_count_in_python в нашей HDFS в корневом каталоге, в котором будет храниться наш файл word_count_data.txt, с помощью следующей команды.
hdfs dfs -mkdir / word_count_in_python
Скопируйте word_count_data.txt в эту папку в нашей HDFS с помощью команды copyFromLocal.
Синтаксис для копирования файла из вашей локальной файловой системы в HDFS приведен ниже:
hdfs dfs -copyFromLocal / путь 1 / путь 2 .... / путь n / пункт назначения
Актуальная команда (в моем случае)
hdfs dfs -copyFromLocal /home/dikshant/Documents/word_count_data.txt / word_count_in_python

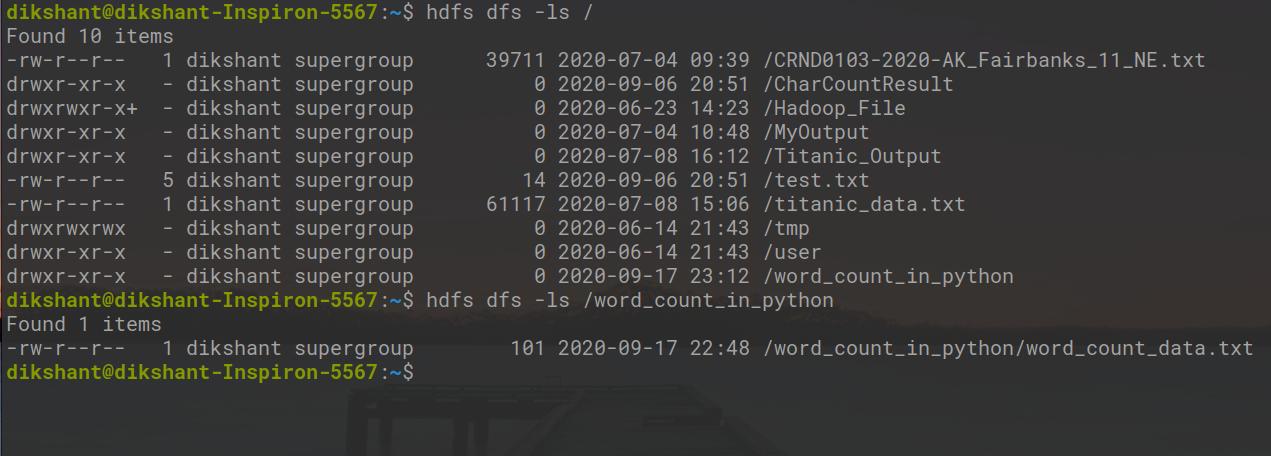
Теперь наш файл данных был успешно отправлен в HDFS. мы можем проверить, отправляет он или нет, используя команду ниже или вручную посетив нашу HDFS.
hdfs dfs -ls / # вывести список содержимого корневого каталога hdfs dfs -ls / word_count_in_python # перечислить содержимое каталога / word_count_in_python
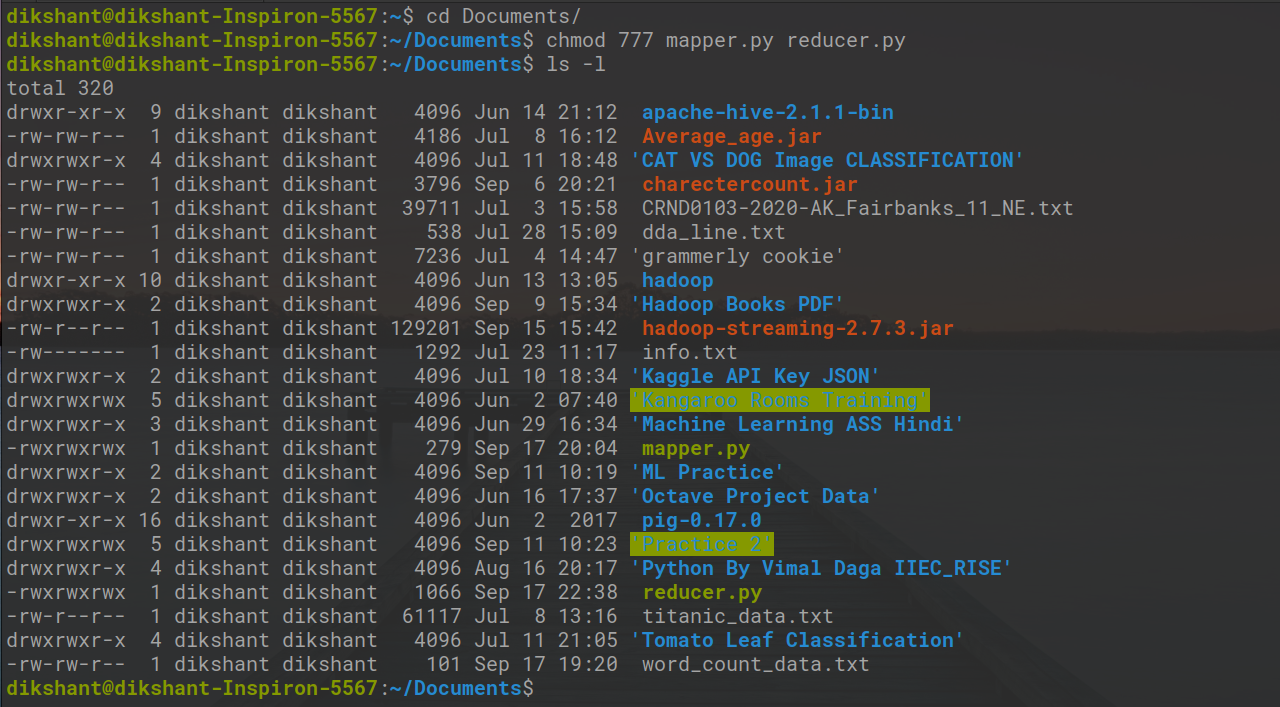
Давайте дадим исполняемое разрешение нашим mapper.py и reducer.py с помощью команды ниже.
cd документы / chmod 777 mapper.py reducer.py # изменение разрешения на чтение, запись, выполнение для пользователя, группы и других
На изображении ниже мы видим, что мы изменили права доступа к файлу.
Шаг 5: Теперь загрузите последнюю версию jar-файла с потоковой передачей hadoop по этой ссылке. Затем поместите этот файл jar с потоковой передачей Hadoop в место, откуда вы можете легко получить к нему доступ. В моем случае я помещаю его в папку / Documents, где есть файлы mapper.py и reducer.py .
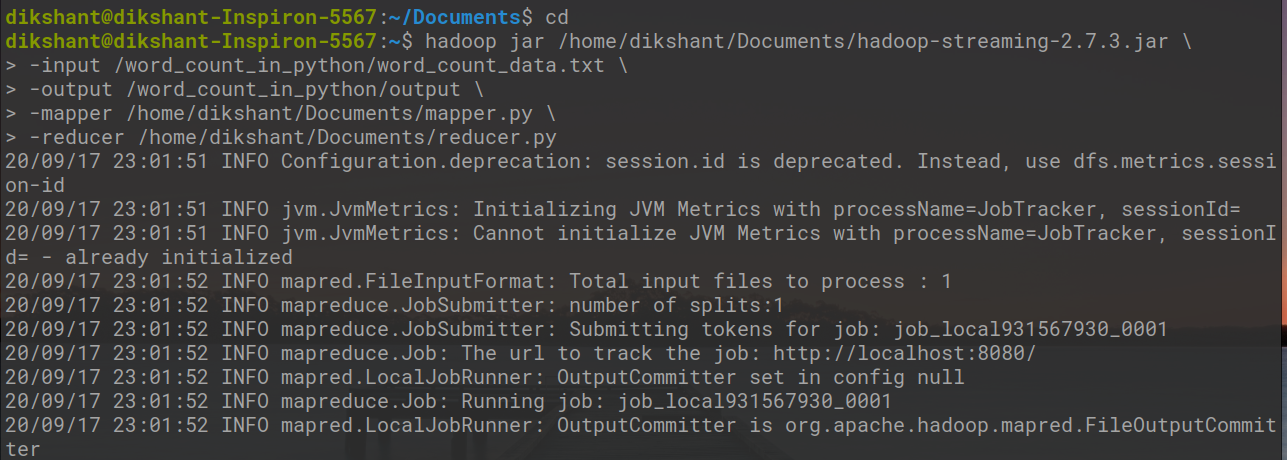
Теперь давайте запустим наши файлы python с помощью утилиты потоковой передачи Hadoop, как показано ниже.
банка hadoop /home/dikshant/Documents/hadoop-streaming-2.7.3.jar > -ввод /word_count_in_python/word_count_data.txt > -output / word_count_in_python / output > -mapper /home/dikshant/Documents/mapper.py > -reducer /home/dikshant/Documents/reducer.py
В приведенной выше команде in -output , мы укажем место в HDFS, где мы хотим сохранить наш вывод. Итак, давайте проверим наш вывод в выходном файле по адресу / word_count_in_python / output / part-00000 в моем случае. Мы можем проверить результаты, вручную просмотрев местоположение в HDFS или с помощью команды cat, как показано ниже.
hdfs dfs -cat / word_count_in_python / output / part-00000
Основные параметры, которые мы можем использовать с Hadoop Streaming Вариант Описание -маппер Команда, которую нужно запустить в качестве картографа -редуктор Команда, которую нужно запустить как редуктор -Вход Путь ввода DFS для шага Map -выход Каталог вывода DFS для шага Reduce