Почему блок в HDFS такой большой?
Диск имеет размер блока, от которого зависит, сколько информации или данных он может прочитать или записать. Блоки диска обычно отличаются от блока файловой системы. Блоки файловой системы обычно имеют размер несколько килобайт, тогда как блоки диска обычно имеют размер 512 байт. Обычно это просто для клиента файловой системы, который читает или записывает документ любой длины. df и fsck - это инструменты, которые работают на уровне блоков файловой системы и используются для обслуживания файловой системы.
Как и другие файловые системы, HDFS (распределенная файловая система Hadoop) также предназначена для хранения или управления данными в блоках. Но в HDFS размер блока по умолчанию намного больше, чем в простых файловых системах. Записи или файлы в HDFS разбиты на различные блоки измеряемого размера, которые размещаются как автономные единицы. Размер блока данных в HDFS по умолчанию составляет 64 МБ, что можно настроить вручную. Как правило, в промышленности используются блоки данных размером 128 МБ. Основное преимущество использования HDFS для хранения информации в кластере состоит в том, что если размер файла меньше, чем размер блока, то в этом случае он не будет занимать весь объем блока базового хранилища.
Почему блок в HDFS такой большой?
Блоки HDFS больше, чем блоки на диске, и это объясняется ограничением затрат на поиск. Время или стоимость передачи данных с диска можно сделать больше, чем время поиска начала блока, просто значительно увеличив размер блоков. Следовательно, для перемещения огромной записи или файла, состоящего из разных блоков, требуется нормальная скорость передачи данных на диск.
Быстрая оценка показывает, что если время поиска для блока данных составляет около 10 мс , а скорость обмена, то есть скорость, с которой передаются данные, составляет 100 МБ / с , в этот момент, чтобы найти время 1% от время обмена, мы должны сделать размер диска около 100 МБ . Однако размер блоков HDFS по умолчанию составляет 64 МБ, но многие, хотя и многочисленные установки HDFS, используют блоки данных размером 128 МБ. По мере роста скорости передачи дисков в будущем размер этих блоков данных также будет следовать восходящему движению, и эта цифра будет постоянно меняться.
Есть много других преимуществ, которые могут быть достигнуты только благодаря абстракции блока данных, давайте обсудим каждое из них.
- Возможно, что файл, который мы храним в HDFS, может быть больше, чем один диск в нашей кластерной сети. с блоками данных в HDFS нет необходимости хранить все блоки записи на одном диске. HDFS может использовать любой из дисков, доступных в кластере.
- В HDFS абстракция выполняется над блоками файла, а не над отдельным файлом, что упрощает подсистему хранения. Поскольку размер блоков фиксирован, легко управлять и вычислять, сколько блоков может быть сохранено на одном диске. Подсистема хранения упрощает систему управления хранением, устраняя проблему хранения метаданных (информации о правах доступа к файлам и журналов). Блоки HDFS могут хранить данные файла на нескольких узлах данных в кластере. Мы можем использовать другую систему, которая управляет метаданными отдельно, обычно известная как NameNode.
- Еще одним преимуществом использования абстракции блоков является простота репликации блоков данных, поэтому в нашем кластере Hadoop можно достичь отказоустойчивости и высокой доступности. По умолчанию каждый блок данных реплицируется трижды на физических машинах, доступных в нашем кластере. В случае, если блок данных каким-то образом недоступен, копия того же блока данных также может быть предоставлена с какого-либо другого узла, доступного в нашем кластере, где создается реплика. Поврежденный блок реплицируется на другую работающую машину, чтобы поддерживать коэффициент репликации в нормальном состоянии. Некоторым важным приложениям может потребоваться высокая репликация, чтобы обеспечить сверхвысокую доступность и распределить нагрузку чтения на наш кластер.
Команда HDFS fsck распознает блоки. выполнение приведенной ниже команды fsck выведет список всех деталей, касающихся блоков, из которых состоит каждый файл в файловой системе.
hdfs fsck / -files -blocks
Давайте быстро разберемся с этим, чтобы понять это:
Шаг 1. Запустите все свои демоны Hadoop с помощью следующих команд.
start-dfs.sh // это запустит ваш namenode, datanode и вторичный namenode start-yarn.sh // запустит ваш менеджер ресурсов и менеджер узлов
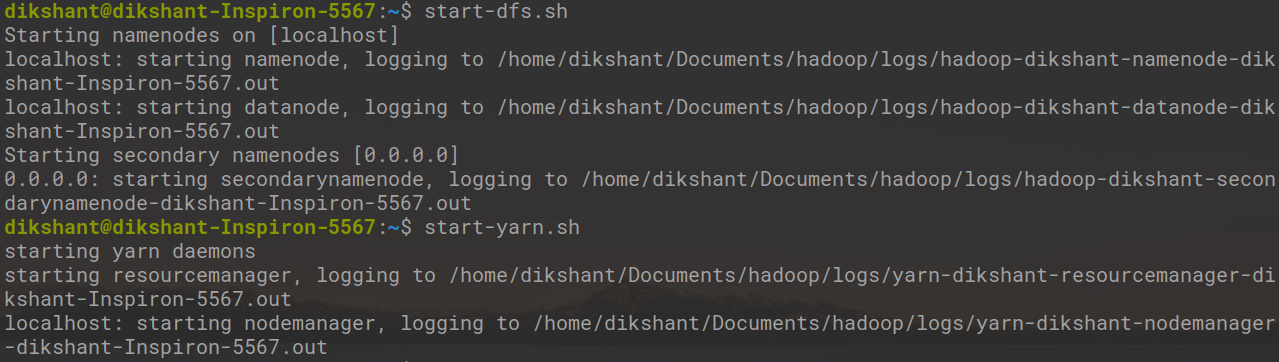
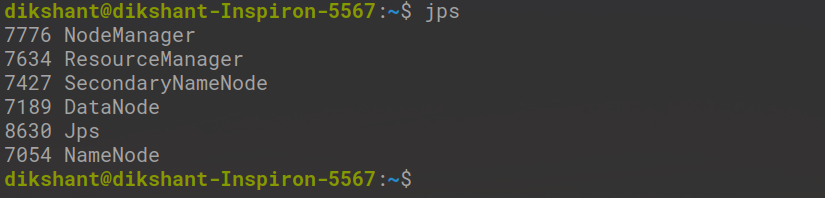
Шаг 2: проверьте состояние запуска Daemon с помощью следующих команд.
jps
Шаг 3. Запустите команду HDFS fsck.
hdfs fsck / -files -blocks

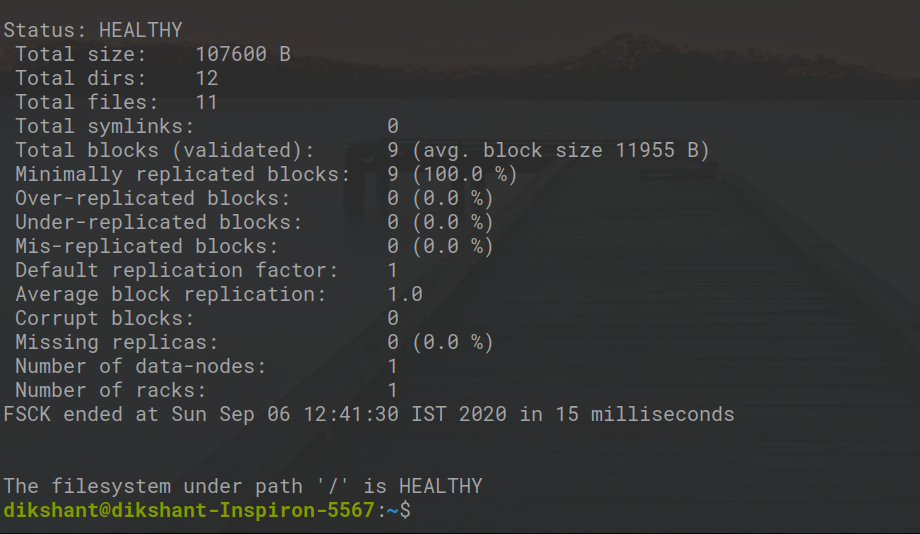
С помощью приведенного выше объяснения мы можем легко увидеть все детали, касающиеся блоков, из которых состоит каждый файл в нашей файловой системе.