ML | Неконтролируемый конвейер кластеризации лиц
Распознавание лиц в реальном времени - проблема, с которой до сих пор сталкиваются автоматизированные подразделения безопасности. Благодаря достижениям в области сверточных нейронных сетей и особенно творческим способам использования Region-CNN, уже подтверждено, что с нашими текущими технологиями мы можем выбрать варианты контролируемого обучения, такие как FaceNet, YOLO, для быстрого и живого распознавания лиц в реальной среде. .
Чтобы обучить контролируемую модель, нам нужно получить наборы данных наших целевых меток, что по-прежнему является утомительной задачей. Нам нужно эффективное и автоматизированное решение для создания наборов данных с минимальными усилиями по маркировке при вмешательстве пользователя.
Предложенное решение -
Введение: мы предлагаем конвейер генерации наборов данных, который берет видеоклип в качестве источника, извлекает все лица и группирует их в ограниченные и точные наборы изображений, представляющих отдельного человека. Каждый набор можно легко пометить с помощью человеческого ввода.
Технические детали: мы собираемся использовать opencv lib для посекундного извлечения кадров из входного видеоклипа. 1 секунда кажется подходящей для покрытия соответствующих данных и ограниченных рамок для обработки.
Мы будем использовать face_recognition (поддерживаемую dlib ) для извлечения лиц из кадров и выравнивания их для извлечения функций.
Затем мы извлечем наблюдаемые человеком функции и сгруппируем их с помощью кластеризации DBSCAN, предоставляемой scikit-learn .
Для решения мы вырежем все лица, создадим метки и сгруппируем их в папки, чтобы пользователи могли адаптировать их в качестве набора данных для своих учебных сценариев использования.
Проблемы при реализации: Для более широкой аудитории мы планируем реализовать решение для выполнения в ЦП, а не в графическом процессоре NVIDIA. Использование графического процессора NVIDIA может повысить эффективность конвейера.
Реализация извлечения эмбеддинга лиц на центральном процессоре выполняется очень медленно (30+ секунд на изображение). Чтобы справиться с проблемой, мы реализуем их с параллельным выполнением конвейера (что дает ~ 13 секунд на изображение), а затем объединяем их результаты для дальнейших задач кластеризации. Мы представляем tqdm вместе с PyPiper для обновления хода выполнения и изменения размера кадров, извлеченных из входного видео, для плавного выполнения конвейера.
Вход: видео.mp4 Выход: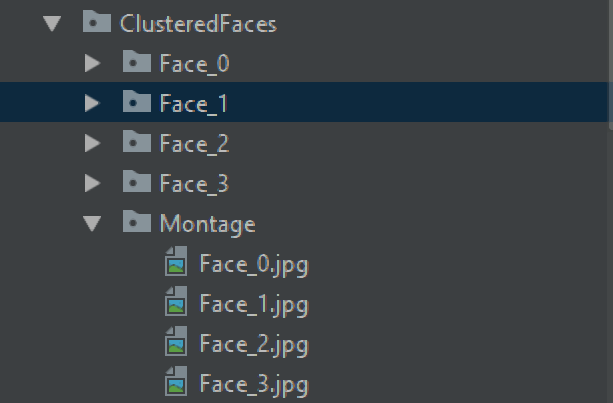
Required Python3 modules:
os, cv2, numpy, tensorflow, json, re, shutil, time, pickle, pyPiper, tqdm, imutils, face_recognition, dlib, warnings, sklearn
Раздел фрагментов:
Что касается содержимого файла FaceClusteringLibrary.py , который содержит все определения классов, ниже приведены фрагменты и объяснение их работы.
Реализация класса ResizeUtils предоставляет функции rescale_by_height и rescale_by_width .
Rescale_by_width - это функция, которая принимает в качестве входных данных 'image' и 'target_width'. Он увеличивает / уменьшает размер изображения для ширины, чтобы соответствовать target_width . Высота рассчитывается автоматически, поэтому соотношение сторон остается неизменным. rescale_by_height тоже то же самое, но вместо ширины он нацелен на высоту.
'''The ResizeUtils provides resizing function to keep the aspect ratio intactCredits: AndyP at StackOverflow'''class ResizeUtils: # Given a target height, adjust the image # by calculating the width and resize def rescale_by_height( self , image, target_height, method = cv2.INTER_LANCZOS4): # Rescale `image` to `target_height` # (preserving aspect ratio) w = int ( round (target_height * image.shape[ 1 ] / image.shape[ 0 ])) return (cv2.resize(image, (w, target_height), interpolation = method)) # Given a target width, adjust the image # by calculating the height and resize def rescale_by_width( self , image, target_width, method = cv2.INTER_LANCZOS4): # Rescale `image` to `target_width` # (preserving aspect ratio) h = int ( round (target_width * image.shape[ 0 ] / image.shape[ 1 ])) return (cv2.resize(image, (target_width, h), interpolation = method)) |
Ниже приводится определение класса FramesGenerator Этот класс предоставляет функциональные возможности для извлечения изображений jpg путем последовательного чтения видео. Если мы возьмем пример входного видеофайла, он может иметь частоту кадров ~ 30 кадров в секунду. Можно сделать вывод, что на 1 секунду видео будет 30 изображений. Даже для 2-минутного видео количество изображений для обработки будет 2 * 60 * 30 = 3600. Это слишком большое количество изображений для обработки и может занять несколько часов для полной конвейерной обработки.
Но есть еще один факт, что лица и люди могут не измениться за секунду. Таким образом, учитывая 2-минутное видео, создание 30 изображений за 1 секунду является громоздким и повторяющимся процессом. Вместо этого мы можем сделать только 1 снимок за 1 секунду. Реализация «FramesGenerator» выгружает только 1 изображение в секунду из видеоклипа.
Учитывая, что выгруженные изображения подлежат face_recognition/dlib для извлечения лиц, мы стараемся поддерживать пороговое значение высоты не более 500 и ширины до 700. Это ограничение накладывается функцией «AutoResize», которая далее вызывает rescale_by_height или rescale_by_width для уменьшения размера изображения в случае превышения ограничений, но при этом сохраняется соотношение сторон.
AutoResize к следующему фрагменту, функция AutoResize пытается наложить ограничение на заданный размер изображения. Если ширина больше 700, мы уменьшаем ее, чтобы сохранить ширину 700 и сохранить соотношение сторон. Другой установленный здесь предел: высота не должна превышать 500.
# The FramesGenerator extracts image# frames from the given video file# The image frames are resized for# face_recognition / dlib processingclass FramesGenerator: def __init__( self , VideoFootageSource): self .VideoFootageSource = VideoFootageSource # Resize the given input to fit in a specified # size for face embeddings extraction def AutoResize( self , frame): resizeUtils = ResizeUtils() height, width, _ = frame.shape if height > 500 : frame = resizeUtils.rescale_by_height(frame, 500 ) self .AutoResize(frame) if width > 700 : frame = resizeUtils.rescale_by_width(frame, 700 ) self .AutoResize(frame) return frame |
Ниже приведен фрагмент функции GenerateFrames Он запрашивает частоту кадров, чтобы решить, из какого количества кадров можно выгрузить одно изображение. Мы очищаем выходной каталог и начинаем повторять кадры. AutoResize размер изображения, если оно достигает предела, указанного в функции AutoResize.
# Extract 1 frame from each second from video footage# and save the frames to a specific folderdef GenerateFrames( self , OutputDirectoryName): cap = cv2.VideoCapture( self .VideoFootageSource) _, frame = cap.read() fps = cap.get(cv2.CAP_PROP_FPS) TotalFrames = cap.get(cv2.CAP_PROP_FRAME_COUNT) print ( "[INFO] Total Frames " , TotalFrames, " @ " , fps, " fps" ) print ( "[INFO] Calculating number of frames per second" ) CurrentDirectory = os.path.curdir OutputDirectoryPath = os.path.join( CurrentDirectory, OutputDirectoryName) if os.path.exists(OutputDirectoryPath): shutil.rmtree(OutputDirectoryPath) time.sleep( 0.5 ) os.mkdir(OutputDirectoryPath) CurrentFrame = 1 fpsCounter = 0 FrameWrittenCount = 1 while CurrentFrame < TotalFrames: _, frame = cap.read() if (frame is None ): continue if fpsCounter > fps: fpsCounter = 0 frame = self .AutoResize(frame) filename = "frame_" + str (FrameWrittenCount) + ".jpg" cv2.imwrite(os.path.join( OutputDirectoryPath, filename), frame) FrameWrittenCount + = 1 fpsCounter + = 1 CurrentFrame + = 1 print ( '[INFO] Frames extracted' ) |
Ниже приведен фрагмент класса FramesProvider Он наследует «Узел», который можно использовать для построения конвейера обработки изображений. Реализуем функции «настройка» и «запуск». Любые аргументы, определенные в функции «setup», могут иметь параметры, которые конструктор будет ожидать в качестве параметров во время создания объекта. Здесь мы можем передать sourcePath параметр в FramesProvider объекта. Функция «настройка» запускается только один раз. Функция «run» запускается и продолжает передавать данные, вызывая emit для конвейера обработки, пока не будет вызвана функция close
Здесь, в «настройке», мы принимаем sourcePath в качестве аргумента и перебираем все файлы в заданном каталоге фреймов. Какое бы расширение файла ни было .jpg (которое будет сгенерировано классом FrameGenerator ), мы добавляем его в список «filesList».
Во время вызовов run все пути к изображениям jpg из «filesList» упаковываются с атрибутами, указывающими уникальный «id» и «imagePath» в качестве объекта, и отправляются в конвейер для обработки.
# Following are nodes for pipeline constructions.# It will create and asynchronously execute threads# for reading images, extracting facial features and# storing them independently in different threads # Keep emitting the filenames into# the pipeline for processingclass FramesProvider(Node): def setup( self , sourcePath): self .sourcePath = sourcePath self .filesList = [] for item in os.listdir( self .sourcePath): _, fileExt = os.path.splitext(item) if fileExt = = '.jpg' : self .filesList.append(os.path.join(item)) self .TotalFilesCount = self .size = len ( self .filesList) self .ProcessedFilesCount = self .pos = 0 # Emit each filename in the pipeline for parallel processing def run( self , data): if self .ProcessedFilesCount < self .TotalFilesCount: self .emit({ 'id' : self .ProcessedFilesCount, 'imagePath' : os.path.join( self .sourcePath, self .filesList[ self .ProcessedFilesCount])}) self .ProcessedFilesCount + = 1 self .pos = self .ProcessedFilesCount else : self .close() |
Ниже приводится реализация класса FaceEncoder, который наследует «Node» и может быть передан в конвейер обработки изображений. В функции «setup» мы принимаем значение «detect_method» для вызова распознавателя лиц «face_recognition / dlib». Он может иметь детектор на основе «cnn» или «hog».
Функция «run» распаковывает входящие данные в «id» и «imagePath».
Затем он считывает изображение из «imagePath», запускает «face_location», определенный в библиотеке «face_recognition / dlib», чтобы вырезать выровненное изображение лица, которое является нашей областью интереса. Выровненное изображение лица - это прямоугольное обрезанное изображение, глаза и губы которого выровнены по определенному месту на изображении (Примечание: реализация может отличаться от других библиотек, например opencv).
Далее мы вызываем функцию «face_encodings», определенную в «face_recognition / dlib», чтобы извлечь вложения лиц из каждого блока. Это встраивание плавающих значений может помочь вам достичь точного местоположения функций на выровненном изображении лица.
Мы определяем переменную «d» как массив ящиков и соответствующих вложений. Теперь мы упаковываем «id» и массив вложений в качестве ключа «кодирования» в объект и отправляем его в конвейер обработки изображений.
# Encode the face embedding, reference path# and location and emit to pipelineclass FaceEncoder(Node): def setup( self , detection_method = 'cnn' ): self .detection_method = detection_method # detection_method can be cnn or hog def run( self , data): id = data[ 'id' ] imagePath = data[ 'imagePath' ] image = cv2.imread(imagePath) rgb = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) boxes = face_recognition.face_locations( rgb, model = self .detection_method) encodings = face_recognition.face_encodings(rgb, boxes) d = [{ "imagePath" : imagePath, "loc" : box, "encoding" : enc} for (box, enc) in zip (boxes, encodings)] self .emit({ 'id' : id , 'encodings' : d}) |
Ниже приводится реализация DatastoreManager которая снова наследуется от «узла» и может быть подключена к конвейеру обработки изображений. Цель этого класса - выгрузить массив «encodings» как файл pickle и использовать параметр «id» для уникального имени файла pickle. Мы хотим, чтобы конвейер работал многопоточным.
Чтобы использовать многопоточность для повышения производительности, нам нужно правильно разделить асинхронные задачи и попытаться избежать какой-либо необходимости в синхронизации. Итак, для максимальной производительности мы независимо разрешаем потокам в конвейере записывать данные в отдельный отдельный файл, не мешая другим операциям потока.
Если вы думаете, сколько времени это сэкономило на используемом оборудовании для разработки, без многопоточности, среднее время извлечения встраивания составило ~ 30 секунд. После многопоточного конвейера (с 4 потоками) он уменьшился до ~ 10 секунд, но за счет высокой загрузки ЦП.
Поскольку поток занимает около 10 секунд, частая запись на диск не происходит, и это не снижает нашу многопоточную производительность.
Другой случай, если вы думаете, почему используется pickle вместо альтернативы JSON? Правда в том, что JSON - лучшая альтернатива рассолу. Pickle очень небезопасен для хранения данных и обмена данными. Pickles можно злонамеренно модифицировать для встраивания исполняемых кодов в Python. Файлы JSON удобочитаемы и быстрее кодируются и декодируются. Единственное, в чем хорош pickle, - это безошибочный сброс объектов и содержимого Python в двоичные файлы.
Поскольку мы не планируем хранить и распространять файлы pickle, а для безошибочного выполнения мы используем pickle. В противном случае настоятельно рекомендуется использовать JSON и другие альтернативы.
# Recieve the face embeddings for clustering and# id for naming the distinct filenameclass DatastoreManager(Node): def setup( self , encodingsOutputPath): self .encodingsOutputPath = encodingsOutputPath def run( self , data): encodings = data[ 'encodings' ] id = data[ 'id' ] with open (os.path.join( self .encodingsOutputPath, 'encodings_' + str ( id ) + '.pickle' ), 'wb' ) as f: f.write(pickle.dumps(encodings)) |
Ниже приведена реализация класса PickleListCollator . Он предназначен для чтения массивов объектов в нескольких файлах pickle, слияния в один массив и выгрузки объединенного массива в один файл pickle.
Здесь есть только одна функция GeneratePickle которая принимает outputFilepath который указывает единственный выходной файл pickle, который будет содержать объединенный массив.
# PicklesListCollator takes multiple pickle# files as input and merges them together# It is made specifically to support use-case# of merging distinct pickle files into oneclass PicklesListCollator: def __init__( self , picklesInputDirectory): self .picklesInputDirectory = picklesInputDirectory # Here we will list down all the pickles # files generated from multiple threads, # read the list of results append them to a # common list and create another pickle # with combined list as content def GeneratePickle( self , outputFilepath): datastore = [] ListOfPickleFiles = [] for item in os.listdir( self .picklesInputDirectory): _, fileExt = os.path.splitext(item) if fileExt = = '.pickle' : ListOfPickleFiles.append(os.path.join( self .picklesInputDirectory, item)) for picklePath in ListOfPickleFiles: with open (picklePath, "rb" ) as f: data = pickle.loads(f.read()) datastore.extend(data) with open (outputFilepath, 'wb' ) as f: f.write(pickle.dumps(datastore)) |
Ниже представлена реализация класса FaceClusterUtility Определен конструктор, который принимает «EncodingFilePath» со значением в качестве пути к объединенному файлу pickle. Мы читаем массив из файла pickle и пытаемся кластеризовать их, используя реализацию «DBSCAN» в библиотеке «scikit». В отличие от k-средних, сканирование DBSCAN не требует количества кластеров. Количество кластеров зависит от параметра порога и рассчитывается автоматически.
Реализация DBSCAN предоставляется в «scikit» и также принимает количество потоков для вычислений.
Здесь у нас есть функция «Cluster», которая будет вызываться для чтения данных массива из файла pickle, запуска «DBSCAN», печати уникальных кластеров как уникальных граней и возврата меток. Метки представляют собой уникальные значения, представляющие категории, которые можно использовать для определения категории лица, присутствующего в массиве. (Содержимое массива поступает из файла рассола).
# Face clustering functionalityclass FaceClusterUtility: def __init__( self , EncodingFilePath): self .EncodingFilePath = EncodingFilePath # Credits: Arian's pyimagesearch for the clustering code # Here we are using the sklearn.DBSCAN functioanlity # cluster all the facial embeddings to get clusters # representing distinct people def Cluster( self ): InputEncodingFile = self .EncodingFilePath if not (os.path.isfile(InputEncodingFile) and os.access(InputEncodingFile, os.R_OK)): print ( 'The input encoding file, ' + str (InputEncodingFile) + ' does not exists or unreadable' ) exit() NumberOfParallelJobs = - 1 # load the serialized face encodings # + bounding box locations from disk, # then extract the set of encodings to # so we can cluster on them print ( "[INFO] Loading encodings" ) data = pickle.loads( open (InputEncodingFile, "rb" ).read()) data = np.array(data) encodings = [d[ "encoding" ] for d in data] # cluster the embeddings print ( "[INFO] Clustering" ) clt = DBSCAN(eps = 0.5 , metric = "euclidean" , n_jobs = NumberOfParallelJobs) clt.fit(encodings) # determine the total number of # unique faces found in the dataset labelIDs = np.unique(clt.labels_) numUniqueFaces = len (np.where(labelIDs > - 1 )[ 0 ]) print ( "[INFO] # unique faces: {}" . format (numUniqueFaces)) return clt.labels_ |
Ниже представлена реализация TqdmUpdate который наследуется от «tqdm». tqdm - это библиотека Python, которая визуализирует индикатор выполнения в интерфейсе консоли.
Переменные «n» и «total» распознаются «tqdm». Значения этих двух переменных используются для расчета достигнутого прогресса.
Параметры «done» и «total_size» в функции «update» предоставляют значения при привязке к событию обновления в конвейерной структуре «PyPiper». super().refresh() вызывает реализацию функции «обновления» в классе «tqdm», которая визуализирует и обновляет индикатор выполнения в консоли.
# Inherit class tqdm for visualization of progressclass TqdmUpdate(tqdm): # This function will be passed as progress # callback function. Setting the predefined # variables for auto-updates in visualization def update( self , done, total_size = None ): if total_size not
|