Методы интеллектуального анализа данных
Интеллектуальный анализ данных относится к извлечению или извлечению знаний из больших объемов данных. Другими словами, интеллектуальный анализ данных — это наука, искусство и технология обнаружения больших и сложных объемов данных для обнаружения полезных закономерностей. Теоретики и практики постоянно ищут улучшенные методы, чтобы сделать процесс более эффективным, экономичным и точным. Многие другие термины имеют аналогичное или несколько иное значение для интеллектуального анализа данных, например, извлечение знаний из данных, извлечение знаний, углубление данных анализа данных / шаблонов.
Интеллектуальный анализ данных рассматривается как синоним другого широко используемого термина, извлечения знаний из данных или KDD. Другие рассматривают интеллектуальный анализ данных как просто важный шаг в процессе обнаружения знаний, в котором применяются интеллектуальные методы для извлечения шаблонов данных.
Грегори Пиатецкий-Шапиро ввел термин «Обнаружение знаний в базах данных» в 1989 году. Однако термин «интеллектуальный анализ данных» стал более популярным в деловых кругах и в прессе. В настоящее время интеллектуальный анализ данных и обнаружение знаний взаимозаменяемы.
В настоящее время интеллектуальный анализ данных используется практически во всех местах, где хранится и обрабатывается большой объем данных.
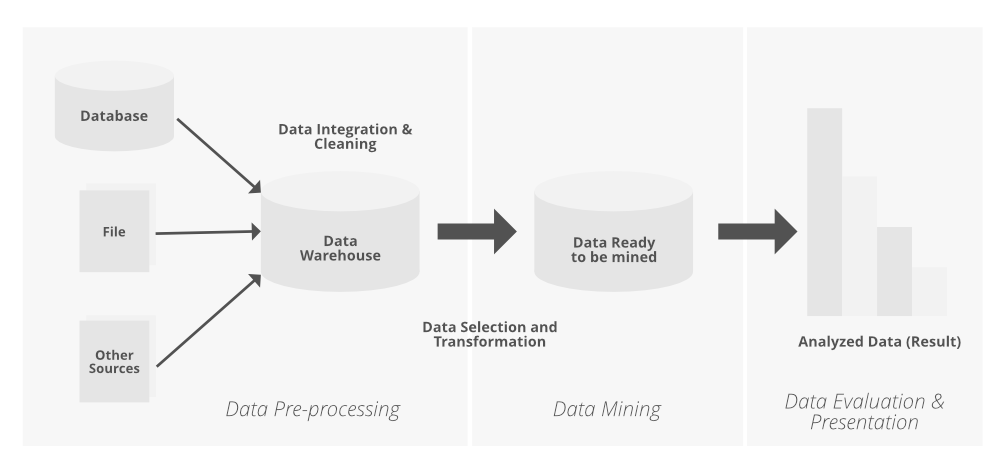
Обнаружение знаний из данных состоит из следующих шагов:
- Очистка данных (удаление шума или ненужных данных).
- Интеграция данных (где несколько источников данных могут быть объединены).
- Выбор данных (где данные, относящиеся к задаче анализа, извлекаются из базы данных).
- Преобразование данных (где данные преобразуются или консолидируются в формы, подходящие для анализа, путем выполнения функций суммирования или агрегирования, например).
- Интеллектуальный анализ данных (важный процесс, в котором применяются интеллектуальные методы для извлечения шаблонов данных).
- Оценка шаблонов (для выявления увлекательных шаблонов, представляющих знания, на основе некоторых показателей интереса).
- Презентация знаний (где методы представления и визуализации знаний используются для представления добытых знаний пользователю).
Теперь мы обсудим здесь различные типы методов интеллектуального анализа данных, которые используются для прогнозирования желаемого результата.
Методы интеллектуального анализа данных
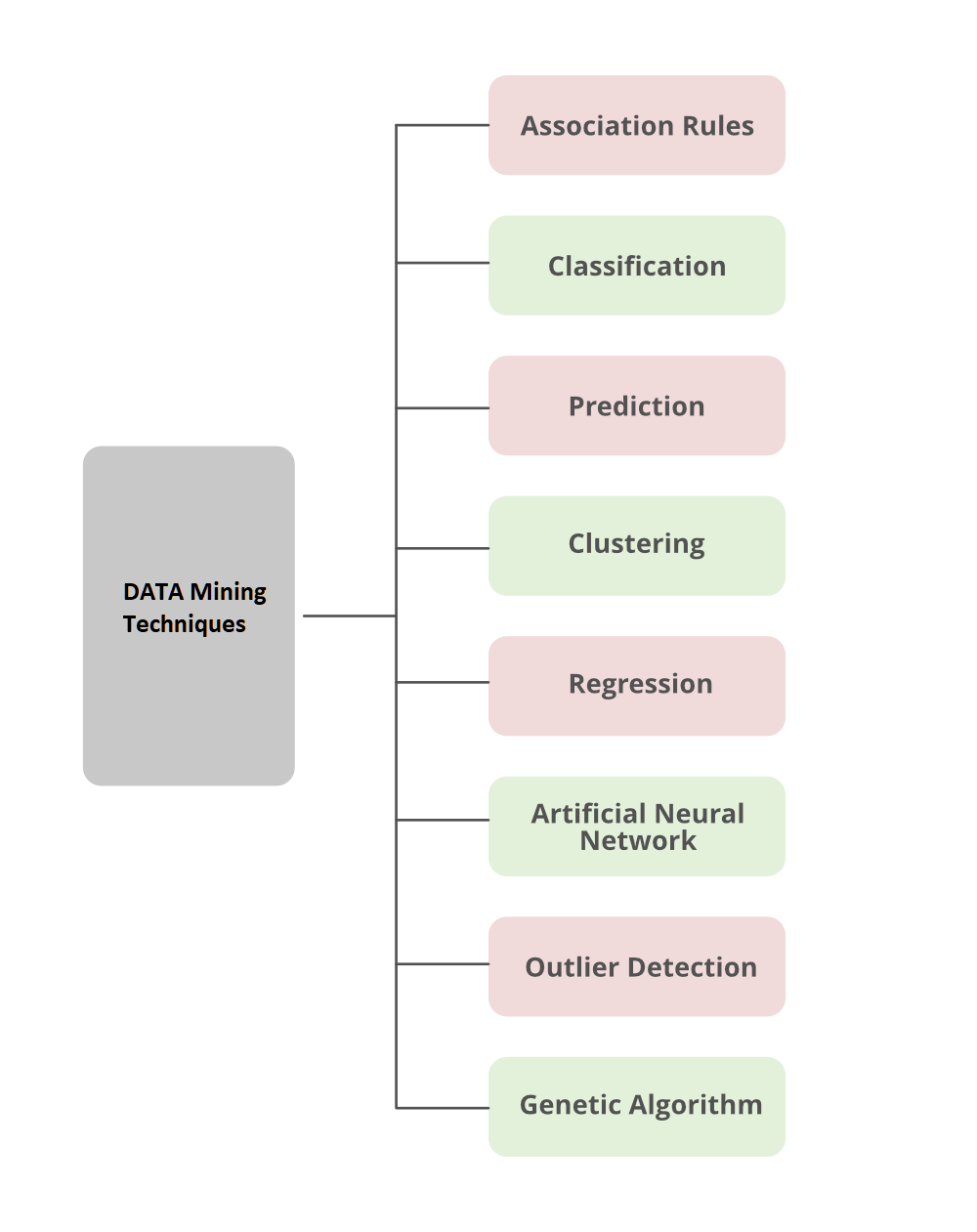
1. Ассоциация
Ассоциативный анализ — это нахождение правил ассоциации, показывающих условия атрибут-значение, которые часто встречаются вместе в заданном наборе данных. Ассоциативный анализ широко используется для анализа рыночной корзины или данных о сделках. Интеллектуальный анализ ассоциативных правил является важной и исключительно динамичной областью исследований в области интеллектуального анализа данных. Один из методов классификации на основе ассоциаций, называемый ассоциативной классификацией, состоит из двух этапов. На основном этапе инструкции по ассоциации генерируются с использованием модифицированной версии стандартного алгоритма анализа правил ассоциации, известного как априори. На втором этапе создается классификатор на основе обнаруженных правил ассоциации.
2. Классификация
Классификация — это процесс поиска набора моделей (или функций), которые описывают и различают классы данных или концепции, с целью возможности использования модели для прогнозирования класса объектов, метка класса которых неизвестна. Определенная модель зависит от исследования набора информации обучающих данных (т. е. объектов данных, метка класса которых известна). Производная модель может быть представлена в различных формах, таких как правила классификации (если – то), деревья решений и нейронные сети. Data Mining имеет другой тип классификатора:
- Древо решений
- SVM (машина опорных векторов)
- Обобщенные линейные модели
- Байесовская классификация:
- Классификация по обратному распространению
- Классификатор К-НН
- Классификация на основе правил
- Классификация на основе часто встречающихся шаблонов
- Грубая теория множеств
- Нечеткая логика
Деревья решений . Дерево решений представляет собой древовидную структуру, похожую на блок-схему, где каждый узел представляет тест значения атрибута, каждая ветвь обозначает результат теста, а листья дерева представляют классы или распределения классов. Деревья решений можно легко преобразовать в правила классификации. Составление дерева решений — это непараметрическая методология построения моделей классификации. Другими словами, он не требует каких-либо предварительных предположений относительно типа распределения вероятностей, которому удовлетворяет класс и другие атрибуты. Деревья решений, особенно деревья меньшего размера, относительно легко интерпретировать. Точность деревьев также сопоставима с двумя другими методами классификации для очень простого набора данных. Они обеспечивают выразительное представление для изучения функций с дискретными значениями. Однако они плохо упрощают определенные типы булевых задач.
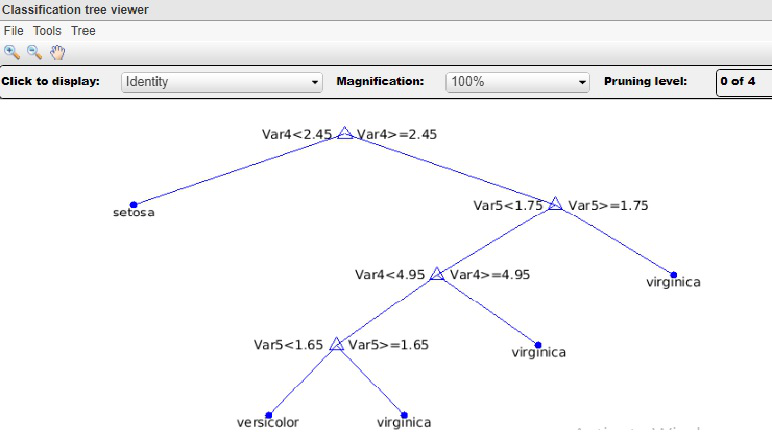
Этот рисунок создан на основе набора данных IRIS репозитория UCI. По сути, в наборе данных доступны три разных метки класса: Setosa, Versicolor и Virginia.
Метод классификатора машины опорных векторов (SVM) : Машины опорных векторов — это контролируемая стратегия обучения, используемая для классификации и дополнительно используемая для регрессии. Когда выходной сигнал машины опорных векторов является непрерывным значением, утверждается, что методология обучения выполняет регрессию; и как только методология обучения предскажет метку категории входного объекта, это называется классификацией. Независимые переменные могли или не могли быть количественными. Уравнения ядра - это функции, которые преобразуют линейно неразделимую информацию в одной области в другую область, где экземпляры становятся линейно делимыми. Уравнения ядра также бывают линейными, квадратичными, гауссовскими или любыми другими, которые достигают этой конкретной цели. Метод линейной классификации может быть классификатором, который использует линейную функцию своих входных данных для принятия решения. Применение уравнений ядра упорядочивает экземпляры информации таким образом, через интервалы в многомерном пространстве, что существует гиперплоскость, которая отделяет экземпляры знаний одного вида от экземпляров другого. Преимущество машин опорных векторов заключается в том, что они будут использовать определенные ядра для преобразования проблемы, поэтому мы можем применять методы линейной классификации к нелинейным знаниям. Как только нам удастся разделить информацию на два разных класса, наша цель состоит в том, чтобы включить наиболее эффективную гиперплоскость для разделения двух типов экземпляров.
Обобщенные линейные модели: Обобщенные линейные модели (GLM) - это статистический метод для линейного моделирования. GLM предоставляет обширную статистику коэффициентов и статистику моделей, а также диагностику строк. Он также поддерживает доверительные границы.
Байесовская классификация: Байесовский классификатор является статистическим классификатором. Они могут предсказывать вероятности принадлежности к классу, например, вероятность того, что данная выборка принадлежит к определенному классу. Байесовская классификация создана на основе теоремы Байеса. Исследования, сравнивающие алгоритмы классификации, показали, что простой байесовский классификатор, известный как наивный байесовский классификатор, сравним по производительности с деревом решений и классификаторами нейронных сетей. Байесовские классификаторы также продемонстрировали высокую точность и скорость при применении к большим базам данных. Наивные байесовские классификаторы предполагают, что точное значение атрибута в данном классе не зависит от значений других атрибутов. Это допущение называется условной независимостью класса. Это сделано для упрощения расчетов и считается «наивным». Байесовские сети доверия представляют собой графические реплики, которые, в отличие от наивных байесовских классификаторов, позволяют отображать зависимости между подмножествами атрибутов. Байесовское убеждение также может быть использовано для классификации.
Классификация по обратному распространению: Обратное распространение обучается путем итеративной обработки набора обучающих выборок, сравнивая оценку сети для каждой выборки с фактической известной меткой класса. Для каждой обучающей выборки веса изменяются, чтобы минимизировать среднеквадратичную ошибку между прогнозом сети и фактическим классом. Эти изменения производятся в «обратном» направлении, т. е. от выходного слоя через каждый скрытый слой вниз к первому скрытому слою (отсюда и название «обратное распространение»). Хотя это и не гарантировано, в общем случае веса окончательно сойдутся, и процесс познания остановится.
Метод классификатора K-ближайших соседей (K-NN) : Классификатор k-ближайших соседей (K-NN) учитывается как классификатор на основе примеров, что означает, что учебные документы используются для сравнения вместо точной иллюстрации класса. , как профили классов, используемые другими классификаторами. Как таковой, нет никакой реальной обучающей секции. как только новый документ должен быть классифицирован, находятся k наиболее похожих документов (соседей), и если достаточно большая часть из них отнесена к определенному классу, новый документ также относится к текущему классу, в противном случае нет. Кроме того, поиск ближайших соседей ускоряется с использованием традиционных стратегий классификации.
Классификация на основе правил: Классификация на основе правил представляет знания в виде правил «если-то». Оценка правила, оцениваемого в соответствии с точностью и охватом классификатора. Если срабатывает более одного правила, нам необходимо разрешить конфликт в классификации на основе правил. Разрешение конфликтов может выполняться по трем различным параметрам: упорядочение по размеру, упорядочение на основе классов и упорядочение на основе правил. Есть некоторые преимущества классификатора на основе правил, такие как:
- Правила легче понять, чем большое дерево.
- Правила являются взаимоисключающими и исчерпывающими.
- Каждая пара атрибут-значение на пути образует соединение: каждый лист содержит предсказание класса.
Классификация на основе частых шаблонов: обнаружение частых шаблонов (или обнаружение FP, анализ FP или анализ частых наборов элементов) является частью интеллектуального анализа данных. Он описывает задачу поиска наиболее частых и релевантных закономерностей в больших наборах данных. Идея была впервые представлена для майнинга баз данных транзакций. Частые шаблоны определяются как подмножества (наборы элементов, подпоследовательности или подструктуры), которые появляются в наборе данных с частотой не ниже заданного пользователем или автоматически определяемого порога.
Грубая теория множеств: Теория грубых множеств может использоваться для классификации, чтобы обнаружить структурные отношения в неточных или зашумленных данных. Это относится к функциям с дискретными значениями. Следовательно, атрибуты с непрерывными значениями должны быть дискретными до их использования. Теория грубых множеств основана на установлении классов эквивалентности в данных обучающих данных. Все выборки данных, образующие класс подобия, неразличимы, то есть выборки равны по атрибутам, описывающим данные. Грубые наборы также можно использовать для сокращения признаков (где атрибуты, которые не способствуют классификации данных обучения, могут быть идентифицированы и удалены) и анализа релевантности (где вклад или значимость каждого атрибута оценивается по отношению к классификации). задача). Задача нахождения минимальных подмножеств (редактов) атрибутов, описывающих все концепты в заданном наборе данных, является NP-трудной. Однако были предложены алгоритмы для снижения интенсивности вычислений. Например, в одном методе используется матрица различимости, в которой хранятся различия между значениями атрибутов для каждой пары выборок данных. Вместо того, чтобы указывать на весь обучающий набор, вместо этого выполняется поиск в матрице для обнаружения избыточных атрибутов.
Нечеткая логика: системы классификации, основанные на правилах, имеют недостаток, заключающийся в том, что они включают четкие ограничения для непрерывных атрибутов. Нечеткая логика полезна для сред интеллектуального анализа данных, выполняющих группировку/классификацию. Это обеспечивает преимущество работы на высоком уровне абстракции. В общем, использование нечеткой логики в системах, основанных на правилах, включает следующее:
- Значения атрибутов изменены на нечеткие значения.
- Для данного нового набора данных/примера может применяться более одного нечеткого правила. Каждое применимое правило способствует голосованию за членство в категориях. Как правило, значения истинности для каждой прогнозируемой категории суммируются.
3. Прогноз
Прогнозирование данных — это двухэтапный процесс, аналогичный процессу классификации данных. Хотя для прогнозирования мы не используем формулировку «Атрибут метки класса», потому что атрибут, для которого прогнозируются значения, является последовательно оцененным (упорядоченным), а не категориальным (дискретно оцененным и неупорядоченным). Атрибут может называться просто предсказанным атрибутом. Прогнозирование можно рассматривать как построение и использование модели для оценки класса немаркированного объекта или для оценки значений или диапазонов значений атрибута, который, вероятно, будет иметь данный объект.
4. Кластеризация
В отличие от классификации и предсказания, которые анализируют объекты данных или атрибуты, помеченные классом, кластеризация анализирует объекты данных без обращения к определенной метке класса. Как правило, метки классов не существуют в обучающих данных просто потому, что они неизвестны с самого начала. Для создания этих меток можно использовать кластеризацию. Объекты группируются по принципу максимизации внутриклассового сходства и минимизации межклассового сходства. То есть кластеры объектов создаются таким образом, что объекты внутри кластера имеют высокое сходство в отличие друг от друга, но являются разными объектами в других кластерах. Каждый сгенерированный кластер можно рассматривать как класс объектов, из которых можно вывести правила. Кластеризация также может способствовать формированию классификации, то есть организации наблюдений в иерархию классов, которые объединяют сходные события.
5. Регрессия
Регрессию можно определить как метод статистического моделирования, в котором ранее полученные данные используются для прогнозирования непрерывной величины для новых наблюдений. Этот классификатор также известен как классификатор непрерывного значения. Существует два типа моделей регрессии: модели линейной регрессии и модели множественной линейной регрессии.
6. Метод классификатора искусственной нейронной сети (ИНС).
Искусственная нейронная сеть (ИНС), также называемая просто «нейронной сетью» (НС), может быть моделью процесса, поддерживаемой биологическими нейронными сетями. Он состоит из взаимосвязанного набора искусственных нейронов. Нейронная сеть — это набор связанных блоков ввода/вывода, где каждое соединение имеет связанный с ним вес. На этапе знаний сеть получает информацию, регулируя веса, чтобы иметь возможность предсказать правильную метку класса входных выборок. Обучение нейронной сети также называют коннекционистским обучением из-за связей между модулями. Нейронные сети требуют длительного времени обучения и поэтому больше подходят для приложений, где это возможно. Для них требуется ряд параметров, которые обычно лучше всего определяются эмпирически, например топология или «структура» сети. Нейронные сети подвергались критике за их плохую интерпретируемость, поскольку людям трудно понять символическое значение заученных весов. Эти особенности сделали нейронные сети менее привлекательными для интеллектуального анализа данных.
Однако преимущества нейронных сетей заключаются в их высокой устойчивости к зашумленным данным, а также в их способности классифицировать шаблоны, на которых они не были обучены. Кроме того, недавно было разработано несколько алгоритмов для извлечения правил из обученных нейронных сетей. Эти проблемы способствуют полезности нейронных сетей для классификации при интеллектуальном анализе данных.
Искусственная нейронная сеть — это система прилагательных, которая изменяет свою поддерживаемую структурой информацию, которая проходит через искусственную сеть во время раздела обучения. ИНС основана на принципе обучения на примере. Существует два классических типа нейронных сетей: персептрон, а также многослойный персептрон.
7. Обнаружение выбросов
База данных может содержать объекты данных, которые не соответствуют общему поведению или модели данных. Эти объекты данных являются выбросами. Исследование данных OUTLIER известно как OUTLIER MINING. Выброс может быть обнаружен с помощью статистических тестов, которые предполагают модель распределения или вероятности для данных, или с помощью мер расстояния, когда объекты, имеющие небольшую долю «близких» соседей в пространстве, считаются выбросами. Вместо того, чтобы использовать фактические или дистанционные меры, методы, основанные на отклонениях, различают исключения / выбросы, проверяя различия в основных атрибутах элементов в группе.
8. Генетический алгоритм
Генетические алгоритмы представляют собой адаптивные эвристические алгоритмы поиска, которые относятся к большей части эволюционных алгоритмов. Генетические алгоритмы основаны на идеях естественного отбора и генетики. Это интеллектуальное использование случайного поиска с историческими данными для направления поиска в область с лучшей производительностью в пространстве решений. Они обычно используются для создания высококачественных решений задач оптимизации и задач поиска. Генетические алгоритмы имитируют процесс естественного отбора, что означает, что те виды, которые могут адаптироваться к изменениям в окружающей среде, способны выживать, размножаться и переходить к следующему поколению. Проще говоря, они имитируют «выживание наиболее приспособленных» среди особей последовательных поколений для решения проблемы. Каждое поколение состоит из популяции особей, и каждая особь представляет собой точку в пространстве поиска и возможное решение. Каждый индивидуум представлен в виде строки символов/целых чисел/плавающих чисел/битов. Эта строка аналогична хромосоме.