Механизм высокой доступности в Cassandra
В этой статье мы узнаем о механизме высокой доступности в Cassandra, используя следующую ключевую терминологию.
1. Семенной узел 2. Протокол обмена сплетнями. 3. Обнаружение сбоев 4. Намеченная передача обслуживания
давайте обсудим один за другим.
1. Семенной узел:
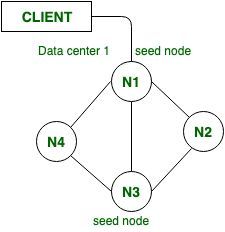
В Apache Cassandra это первые узлы, которые запускаются в кластере. Если мы хотим настроить начальный узел, мы можем настроить его в файле Cassandra.yaml, который является основным файлом в Cassandra для изменения любых параметров конфигурации. Узел seed помогает в начальной загрузке для новых узлов, присоединяющихся к кластеру в Cassandra.
Исходный узел также полезен для предоставления информации о другом узле. Когда новый узел подключается к сети, он будет опрашивать начальный узел, чтобы получить информацию о других узлах в кластере.
Последовательность запуска:
В Cassandra стартовая последовательность играет важную роль. start sequence дает начальную последовательность, поэтому запускайте начальные узлы один за другим, а затем остальные узлы.
Лучшая практика: в Cassandra всегда рекомендуется устанавливать более одного начального узла для каждого центра обработки данных в кластере.
Адрес слушателя и порт хранения:
В межузловом взаимодействии мы использовали listener_address и порт хранения для связи в Cassandra. Идентификатор порта по умолчанию для Cassandra - 7000. В Cassandra идентификатор порта должен быть одинаковым для каждого узла в кластере.
listener_address = IP-адрес узла storage_port = 7000 (по умолчанию)
2. Протокол обмена сплетнями:
В Cassandra узлы периодически (каждую секунду) обмениваются информацией о состоянии (например, мертвый или живой) о себе, а затем о других узлах, о которых они знают. В Cassandra Gossip Communication Protocol также известен как эпидемический протокол. Это быстрый децентрализованный автоматический способ узнать о себе для кластера, который очень полезен для информации об узлах в кластере.
В протоколе связи слухов, чтобы обеспечить быстрый перезапуск, информация о сплетнях сохраняется локально каждым узлом. Понимание значения настойчивости важно для оценки различных систем хранения данных.
Стойкость - это «продолжение действия после того, как его причина устранена». В контексте хранения данных в компьютерной системе это означает, что данные сохраняются после завершения процесса, с помощью которого они были созданы. Другими словами, чтобы хранилище данных считалось постоянным, оно должно записываться в энергонезависимое хранилище.
Критический:
Одной из важных задач является то, что список начальных узлов в любом центре обработки данных должен быть одинаковым на каждом узле в кластере.
3. Обнаружение сбоев:
В случае обнаружения сбоя, узел локально определяет состояние и историю сплетен и соответствующим образом корректирует маршруты в кластере. Начисление Phi - важный алгоритм для алгоритма обнаружения сбоев. В нем указывается постоянный уровень подозрений между мертвым и активным состоянием узла в отношении того, насколько уверенно узел вышел из строя. Это может быть производительность сети, проблема рабочей нагрузки, которую необходимо принять во внимание, и так далее.
В случае обнаружения сбоя узла другие узлы будут периодически пытаться посплетничать с отказавшим узлом, чтобы узнать, вернется ли он в сеть.
Теперь давайте посмотрим на CQL-запрос, чтобы проверить состояние узла. По умолчанию cqlsh подключается к 127.0.0.1. Чтобы получить такую информацию, как идентификатор хоста, версия выпуска и т. Д., Используется следующий запрос CQL.
SELECT peer, data_center, host_id,
предпочтительный_IP, стойка, версия_выпуска,
rpc_address, schema_version
ОТ system.peers;Чтобы получить информацию об узле, используется следующая команда CQL в Cassandra.
nodetool gossipinfo
Чтобы завершить работу узла, выполнив:
nodetool stopdaemon
Проверьте информацию gossipinfo на node1. Обратите внимание, что информация о сплетнях node2 все еще присутствует, поскольку он является частью кластера, но его состояние STATUS - выключено.
4. Намек на передачу:
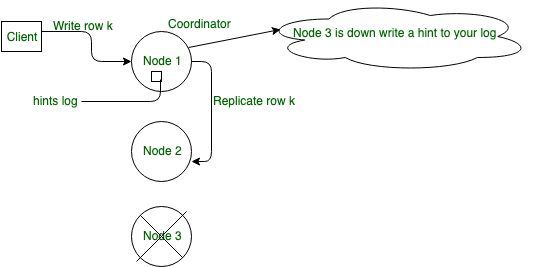
В Cassandra это один из важных аспектов механизма высокой доступности. Это помогает сократить время восстановления отказавшего узла, повторно присоединяющегося к кластеру, и обеспечить абсолютную доступность записи, допуская несогласованные чтения. Как показано на диаграмме, если реплика не работает во время записи, другая работоспособная реплика хранит подсказку, а если все соответствующие реплики отключены, координатор или локально хранит подсказку.
Подсказка = местоположение [неудачная реплика]
+ затронут [ключ строки]
+ записываемые данныеПримечание:
В Cassandra подсказка будет передана, когда узел, ответственный за этот диапазон токенов, снова поднимется.
Антиэнтропия:
В случае механизма высокой доступности Антиэнтропия - это механизм синхронизации реплик для обеспечения актуальности данных на всех узлах.
Пример:
Как правило, рекомендуется иметь достаточное количество узлов в кластере и достаточный коэффициент репликации, чтобы избежать сбоев запросов на запись. Например, рассмотрим кластер, состоящий из трех узлов: Узел 1, Узел 2 и Узел 3, с коэффициентом репликации 2. Когда строка K записывается в координатор (узел A в данном случае), даже если Узел 3 является вниз, может быть достигнут уровень согласованности ОДИН или КВОРУМ. Почему? И узел 1, и узел 2 получат данные, поэтому требование уровня согласованности выполнено. Подсказка узла 1 сохраняется для узла 3 и записывается, когда узел 3 появляется. Тем временем координатор может подтвердить, что запись прошла успешно.
Вниманию читателя! Не прекращайте учиться сейчас. Получите все важные концепции теории CS для собеседований SDE с курсом теории CS по доступной для студентов цене и будьте готовы к отрасли.