MapReduce - Комбайнеры
Map-Reduce - это модель программирования, которая используется для обработки больших наборов данных в распределенных системах в Hadoop. Фаза карты и фаза сокращения - две основные важные части любой работы по уменьшению карты. Приложения Map-Reduce ограничены доступной полосой пропускания в кластере, потому что данные перемещаются от Mapper к Reducer.
Например , если у нас есть 1 Гбит / с (гигабит в секунду) сети в нашем кластере, и мы обрабатываем данные, которые находятся в диапазоне сотен ПБ (петабайт). Перемещение такого большого набора данных на скорость более 1 Гбит / с занимает много времени. Комбайнер используется для решения этой проблемы путем минимизации данных, которые перетасовывались между Map и Reduce.
В этой статье мы рассмотрим Combiner в Map-Reduce, охватывая все перечисленные ниже аспекты.
- Что такое комбайнер?
- Как работает комбайнер
- Преимущество комбайнеров
- Недостаток комбайнера
Что такое комбайнер?
Combiner всегда работает между Mapper и Reducer. Вывод, производимый Mapper, является промежуточным выводом с точки зрения пар ключ-значение, который имеет огромный размер. Если мы напрямую скармливаем этот огромный вывод редуктору, это приведет к увеличению перегрузки сети . Итак, чтобы свести к минимуму эту перегрузку сети, мы должны поместить объединитель между Mapper и Reducer. Эти комбайнеры также известны как полуредукторы . Нет необходимости добавлять комбайнер в вашу программу Map-Reduce, это необязательно. Combiner также является классом в нашей Java-программе, например классом Map и Reduce, который используется между классами Map и Reduce. Combiner помогает нам создавать абстрактные детали или сводку очень больших наборов данных. Когда мы обрабатываем или имеем дело с очень большими наборами данных, использование Hadoop Combiner очень необходимо, что приводит к повышению общей производительности.
Как работает комбайнер?
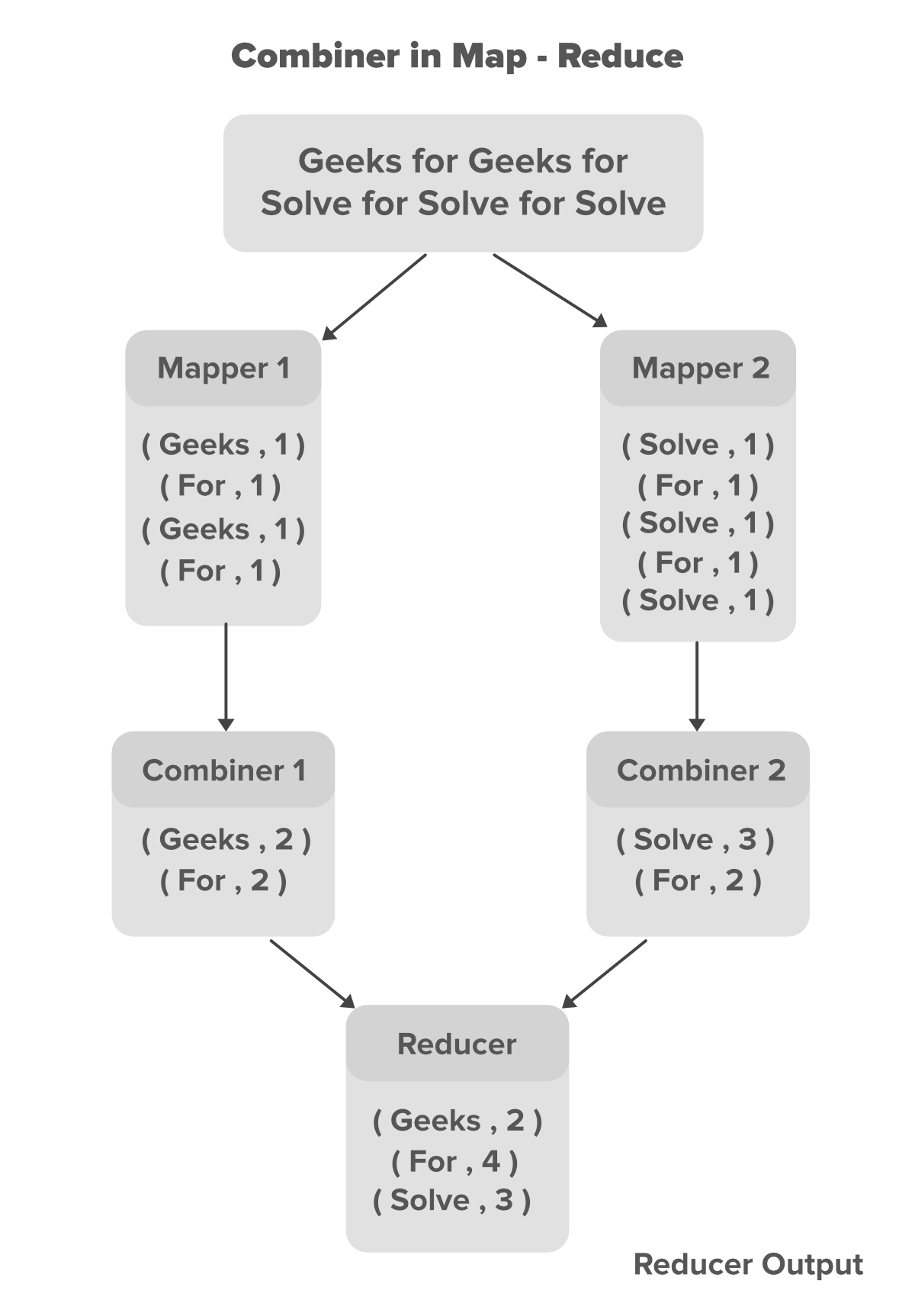
В приведенном выше примере мы видим, что два сопоставителя содержат разные данные. основной текстовый файл разделен на два разных модуля отображения. Каждому картографу назначена обработка отдельной строки наших данных. В нашем примере выше у нас есть две строки данных, поэтому у нас есть два Mapper для обработки каждой строки. Картографы создают промежуточные пары ключ-значение, где имя конкретного слова является ключевым, а его счетчик - его значением . Например, для данных Компьютерщиков Для компьютерных фанатов пары ключ-значение показаны ниже.
// Пары ключ-значение, генерируемые для данных Компьютерщики Для компьютерных фанатов Для (Гики, 1) (Для, 1) (Гики, 1) (Для, 1)
Пары ключ-значение, генерируемые Mapper, известны как промежуточные пары ключ-значение или промежуточные выходные данные Mapper. Теперь мы можем минимизировать количество этих пар ключ-значение, введя объединитель для каждого Mapper в нашей программе. В нашем случае у нас есть 4 пары ключ-значение, генерируемые каждым Mapper. поскольку эти промежуточные пары "ключ-значение" не готовы к прямой передаче в Reducer, поскольку это может увеличить перегрузку сети, Combiner объединит эти промежуточные пары "ключ-значение" перед их отправкой в Reducer. Комбайнер объединяет эти промежуточные пары ключ-значение в соответствии с их ключом . В приведенном выше примере для компьютерных фанатов Для компьютерных фанатов Объединитель частично сократит их, объединив те же пары в соответствии с их значением ключа и сгенерируя новые пары ключ-значение, как показано ниже.
// Частично сокращенные пары ключ-значение с помощью комбайнера (Гики, 2) (Для, 2)
С помощью Combiner выходные данные Mapper были частично уменьшены с точки зрения размера (пары ключ-значение), которые теперь можно сделать доступными для Reducer для повышения производительности. Теперь Reducer снова сократит выходные данные, полученные от объединителей, и создаст окончательный результат, который сохраняется в HDFS (распределенная файловая система Hadoop).
Преимущество комбайнеров
- Сокращает время, необходимое для передачи данных из Mapper в Reducer.
- Уменьшает размер промежуточного вывода, создаваемого Mapper.
- Повышает производительность за счет минимизации перегрузки сети.
Недостаток комбайнеров
- Промежуточные пары ключ-значение, сгенерированные Mappers, хранятся на локальном диске, и комбайнеры будут запускаться позже, чтобы частично уменьшить вывод, что приводит к дорогостоящему вводу-выводу диска.
- Задание map-Reduce не может зависеть от функции комбайнера, потому что при его выполнении нет такой гарантии.