Лучшие библиотеки Python для машинного обучения
Машинное обучение, как следует из названия, - это наука о программировании компьютера, с помощью которого они могут учиться на различных типах данных. Артур Самуэль дал более общее определение: «Машинное обучение - это область обучения, которая дает компьютерам возможность учиться без явного программирования». Обычно они используются для решения различных жизненных проблем.
Раньше люди выполняли задачи машинного обучения, вручную кодируя все алгоритмы и математические и статистические формулы. Это делало процесс трудоемким, утомительным и неэффективным. Но в наши дни это стало намного проще и эффективнее по сравнению с былыми днями с помощью различных библиотек, фреймворков и модулей Python. Сегодня Python является одним из самых популярных языков программирования для этой задачи, и он заменил многие языки в отрасли, одной из причин этого является его обширная коллекция библиотек. Библиотеки Python, которые используются в машинном обучении:
- Numpy
- Scipy
- Scikit-Learn
- Theano
- TensorFlow
- Керас
- PyTorch
- Панды
- Матплотлиб
Numpy

NumPy - очень популярная библиотека Python для обработки больших многомерных массивов и матриц с помощью большого набора математических функций высокого уровня. Это очень полезно для фундаментальных научных вычислений в машинном обучении. Это особенно полезно для возможностей линейной алгебры, преобразования Фурье и случайных чисел. Высококачественные библиотеки, такие как TensorFlow, внутренне используют NumPy для управления тензорами.
# Python program using NumPy# for some basic mathematical# operations import numpy as np # Creating two arrays of rank 2x = np.array([[ 1 , 2 ], [ 3 , 4 ]])y = np.array([[ 5 , 6 ], [ 7 , 8 ]]) # Creating two arrays of rank 1v = np.array([ 9 , 10 ])w = np.array([ 11 , 12 ]) # Inner product of vectorsprint (np.dot(v, w), "
" ) # Matrix and Vector productprint (np.dot(x, v), "
" ) # Matrix and matrix productprint (np.dot(x, y)) |
Выход:
219 [29 67] [[19 22] [43 50]]
Для получения более подробной информации обратитесь к Numpy.
SciPy

SciPy - очень популярная библиотека среди энтузиастов машинного обучения, поскольку она содержит различные модули для оптимизации, линейной алгебры, интеграции и статистики. Есть разница между библиотекой SciPy и стеком SciPy. SciPy - один из основных пакетов, составляющих стек SciPy. SciPy также очень полезен для обработки изображений.
# Python script using Scipy # for image manipulation from scipy.misc import imread, imsave, imresize # Read a JPEG image into a numpy arrayimg = imread("D:/Programs / cat.jpg") # path of the imageprint(img.dtype, img.shape) # Tinting the imageimg_tint = img * [1, 0.45, 0.3] # Saving the tinted imageimsave("D:/Programs / cat_tinted.jpg", img_tint) # Resizing the tinted image to be 300 x 300 pixelsimg_tint_resize = imresize(img_tint, (300, 300)) # Saving the resized tinted imageimsave("D:/Programs / cat_tinted_resized.jpg", img_tint_resize) |
Исходное изображение:
Тонированное изображение:
Изменен размер тонированного изображения:
Для получения более подробной информации обратитесь к документации.
Scikit-Learn

Skikit-learn - одна из самых популярных библиотек машинного обучения для классических алгоритмов машинного обучения. Он построен на основе двух базовых библиотек Python, а именно NumPy и SciPy. Scikit-learn поддерживает большинство контролируемых и неконтролируемых алгоритмов обучения. Scikit-learn также можно использовать для интеллектуального анализа и анализа данных, что делает его отличным инструментом для начинающих с машинного обучения.
# Python script using Scikit-learn# for Decision Tree Clasifier # Sample Decision Tree Classifierfrom datasets import sklearnfrom sklearn import metricsfrom sklearn.tree import DecisionTreeClassifier # load the iris datasetsdataset = datasets.load_iris() # fit a CART model to the datamodel = DecisionTreeClassifier()model.fit(dataset.data, dataset.target)print (model) # make predictionsexpected = dataset.targetpredicted = model.predict(dataset.data) # summarize the fit of the modelprint (metrics.classification_report(expected, predicted))print (metrics.confusion_matrix(expected, predicted)) |
Выход:
DecisionTreeClassifier (class_weight = None, критерий = 'gini', max_depth = None,
max_features = Нет, max_leaf_nodes = Нет,
min_impurity_decrease = 0,0, min_impurity_split = Нет,
min_samples_leaf = 1, min_samples_split = 2,
min_weight_fraction_leaf = 0,0, предварительная сортировка = False, random_state = None,
splitter = 'лучший')
точный отзыв поддержка f1-score
0 1,00 1,00 1,00 50
1 1,00 1,00 1,00 50
2 1,00 1,00 1,00 50
микро средн. 1,00 1,00 1,00 150
макрос в среднем 1,00 1,00 1,00 150
средневзвешенный 1,00 1,00 1,00 150
[[50 0 0]
[0 50 0]
[0 0 50]]
Для получения более подробной информации обратитесь к документации.
Theano

Все мы знаем, что машинное обучение - это в основном математика и статистика. Theano - популярная библиотека Python, которая используется для эффективного определения, оценки и оптимизации математических выражений, включающих многомерные массивы. Это достигается за счет оптимизации использования CPU и GPU. Он широко используется для модульного тестирования и самопроверки для обнаружения и диагностики различных типов ошибок. Theano - это очень мощная библиотека, которая долгое время использовалась в крупномасштабных научных проектах с интенсивными вычислениями, но при этом проста и достаточно доступна для использования отдельными людьми в своих собственных проектах.
# Python program using Theano# for computing a Logistic# Function import theanoimport theano.tensor as Tx = T.dmatrix( 'x' )s = 1 / ( 1 + T.exp( - x))logistic = theano.function([x], s)logistic([[ 0 , 1 ], [ - 1 , - 2 ]]) |
Выход:
массив ([[0,5, 0,73105858],
[0,26894142, 0,11920292]])
Для получения более подробной информации обратитесь к документации.
TensorFlow

TensorFlow - очень популярная библиотека с открытым исходным кодом для высокопроизводительных численных вычислений, разработанная командой Google Brain в Google. Как следует из названия, Tensorflow - это фреймворк, который включает определение и выполнение вычислений с использованием тензоров. Он может обучать и запускать глубокие нейронные сети, которые можно использовать для разработки нескольких приложений искусственного интеллекта. TensorFlow широко используется в области исследований и приложений глубокого обучения.
# Python program using TensorFlow# for multiplying two arrays # import `tensorflow`import tensorflow as tf # Initialize two constantsx1 = tf.constant([ 1 , 2 , 3 , 4 ])x2 = tf.constant([ 5 , 6 , 7 , 8 ]) # Multiplyresult = tf.multiply(x1, x2) # Initialize the Sessionsess = tf.Session() # Print the resultprint (sess.run(result)) # Close the sessionsess.close() |
Выход:
[5 12 21 32]
Для получения более подробной информации обратитесь к документации.
Керас
![]()
Keras - очень популярная библиотека машинного обучения для Python. Это высокоуровневый API нейронных сетей, способный работать поверх TensorFlow, CNTK или Theano. Он может без проблем работать как на CPU, так и на GPU. Keras помогает новичкам в ML создавать и проектировать нейронную сеть. Одна из лучших особенностей Keras - это то, что он позволяет легко и быстро создавать прототипы.
Для получения более подробной информации обратитесь к документации.
PyTorch

PyTorch - популярная библиотека машинного обучения с открытым исходным кодом для Python, основанная на Torch, которая представляет собой библиотеку машинного обучения с открытым исходным кодом, которая реализована на C с оболочкой в Lua. Он имеет широкий выбор инструментов и библиотек, которые поддерживают компьютерное зрение, обработку естественного языка (NLP) и многие другие программы машинного обучения. Это позволяет разработчикам выполнять вычисления на тензорах с ускорением графического процессора, а также помогает в создании вычислительных графов.
# Python program using PyTorch# for defining tensors fit a# two-layer network to random# data and calculating the loss import torch dtype = torch. floatdevice = torch.device( "cpu" )# device = torch.device("cuda:0") Uncomment this to run on GPU # N is batch size; D_in is input dimension;# H is hidden dimension; D_out is output dimension.N, D_in, H, D_out = 64 , 1000 , 100 , 10 # Create random input and output datax = torch.randn(N, D_in, device = device, dtype = dtype)y = torch.randn(N, D_out, device = device, dtype = dtype) # Randomly initialize weightsw1 = torch.randn(D_in, H, device = device, dtype = dtype)w2 = torch.randn(H, D_out, device = device, dtype = dtype) learning_rate = 1e - 6for t in range ( 500 ): # Forward pass: compute predicted y h = x.mm(w1) h_relu = h.clamp( min = 0 ) y_pred = h_relu.mm(w2) # Compute and print loss loss = (y_pred - y). pow ( 2 ). sum ().item() print (t, loss) # Backprop to compute gradients of w1 and w2 with respect to loss grad_y_pred = 2.0 * (y_pred - y) grad_w2 = h_relu.t().mm(grad_y_pred) grad_h_relu = grad_y_pred.mm(w2.t()) grad_h = grad_h_relu.clone() grad_h[h < 0 ] = 0 grad_w1 = xt().mm(grad_h) # Update weights using gradient descent w1 - = learning_rate * grad_w1 w2 - = learning_rate * grad_w2 |
Выход:
0 47168344,0 1 46385584,0 2 43153576,0 ... ... ... 497 3.987660602433607e-05 498 3.945609932998195e-05 499 3.897604619851336e-05
Для получения более подробной информации обратитесь к документации.
Панды

Pandas - популярная библиотека Python для анализа данных. Это не имеет прямого отношения к машинному обучению. Как мы знаем, набор данных необходимо подготовить перед обучением. В этом случае вам пригодится Pandas, поскольку он был разработан специально для извлечения и подготовки данных. Он предоставляет высокоуровневые структуры данных и широкий спектр инструментов для анализа данных. Он предоставляет множество встроенных методов для поиска, объединения и фильтрации данных.
# Python program using Pandas for# arranging a given set of data# into a table # importing pandas as pdimport pandas as pd data = { "country" : [ "Brazil" , "Russia" , "India" , "China" , "South Africa" ], "capital" : [ "Brasilia" , "Moscow" , "New Dehli" , "Beijing" , "Pretoria" ], "area" : [ 8.516 , 17.10 , 3.286 , 9.597 , 1.221 ], "population" : [ 200.4 , 143.5 , 1252 , 1357 , 52.98 ] } data_table = pd.DataFrame(data)print (data_table) |
Выход: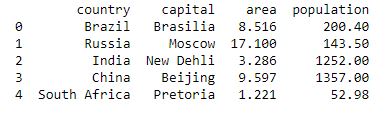
Для получения более подробной информации обратитесь к Pandas.
Матплотлиб
![]()
Matpoltlib - очень популярная библиотека Python для визуализации данных. Как и Pandas, он не имеет прямого отношения к машинному обучению. Это особенно удобно, когда программист хочет визуализировать закономерности в данных. Это библиотека 2D-графиков, используемая для создания 2D-графиков и графиков. Модуль под названием pyplot упрощает для программистов построение графиков, поскольку он предоставляет функции для управления стилями линий, свойствами шрифтов, осями форматирования и т. Д. Он предоставляет различные виды графиков и графиков для визуализации данных, а именно, гистограммы, диаграммы ошибок, гистограммы. , так далее,
# Python program using Matplotib# for forming a linear plot # importing the necessary packages and modulesimport matplotlib.pyplot as pltimport numpy as np # Prepare the datax = np.linspace( 0 , 10 , 100 ) # Plot the dataplt.plot(x, x, label = 'linear' ) # Add a legendplt.legend() # Show the plotplt.show() |
Выход: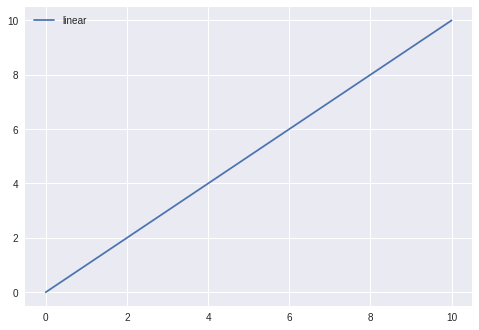
Для получения более подробной информации обратитесь к документации.
Внимание компьютерщик! Укрепите свои основы с помощью базового курса программирования Python и изучите основы.
Для начала подготовьтесь к собеседованию. Расширьте свои концепции структур данных с помощью курса Python DS. А чтобы начать свое путешествие по машинному обучению, присоединяйтесь к курсу Машинное обучение - базовый уровень.