Как выполнить программу подсчета символов в MapReduce Hadoop?
Предварительные требования: Hadoop и MapReduce
Необходимая настройка для выполнения указанной ниже задачи.
- Установка Java
- Установка Hadoop
Наша задача - подсчитать частоту каждого символа, присутствующего во входном файле. Мы используем Java для реализации этого конкретного сценария. Однако программа MapReduce также может быть написана на Python или C ++. Выполните следующие шаги, чтобы выполнить задачу по поиску появления каждого символа.
Пример:
Вход
Компьютерщики
Выход
F 1 G 2 e 4 k 2 o 1 r 1 с 2
Шаг 1: Первый открытый Затмение -> затем выберите File -> New -> Java Project -> Имя его CharCount -> затем выберите использовать среду выполнения -> выбрать JavaSE-1.8 , то дальше -> Finish.
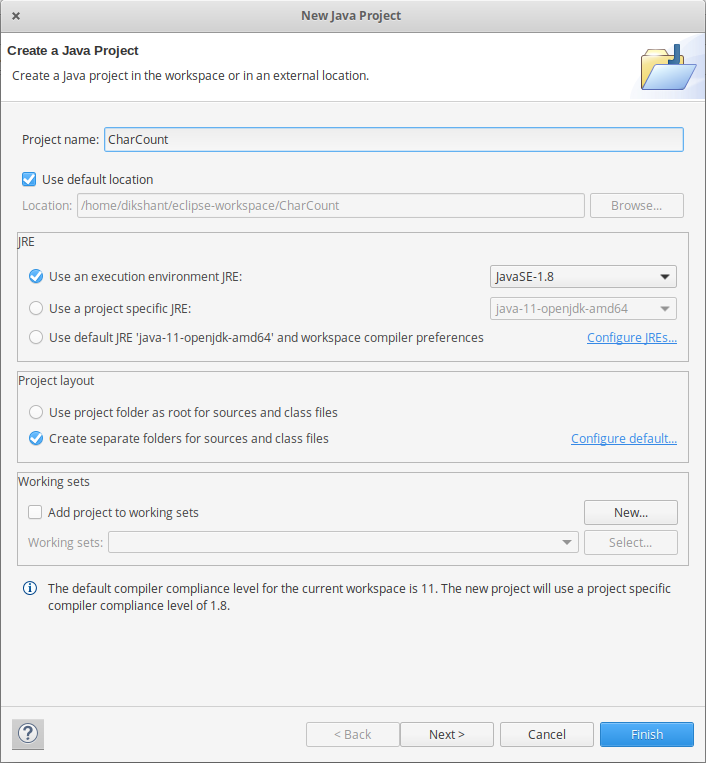
Шаг 2. Создайте в проекте три класса Java. Назовите их CharCountDriver (имеющий основную функцию), CharCountMapper , CharCountReducer.
Mapper Code: You have to copy and paste this program into the CharCountMapper Java Class file.
Java
import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapred.MapReduceBase; import org.apache.hadoop.mapred.Mapper; import org.apache.hadoop.mapred.OutputCollector; import org.apache.hadoop.mapred.Reporter; public class CharCountMapper extends MapReduceBase implements Mapper<LongWritable,Text,Text,IntWritable>{ public void map(LongWritable key, Text value,OutputCollector<Text,IntWritable> output, Reporter reporter) throws IOException{ String line = value.toString(); String tokenizer[] = line.split(""); for(String SingleChar : tokenizer) { Text charKey = new Text(SingleChar); IntWritable One = new IntWritable(1); output.collect(charKey, One); } } } |
Reducer Code: You have to copy-paste this below program into the CharCountReducer Java Class file.
Java
import java.io.IOException;import java.util.Iterator;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapred.MapReduceBase;import org.apache.hadoop.mapred.OutputCollector;import org.apache.hadoop.mapred.Reducer;import org.apache.hadoop.mapred.Reporter; public class CharCountReducer extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> { public void reduce(Text key, Iterator<IntWritable> values, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException { int sum = 0; while (values.hasNext()) { sum += values.next().get(); } output.collect(key, new IntWritable(sum)); }} |
Driver Code: You have to copy-paste this below program into the CharCountDriver Java Class file.
Java
import java.io.IOException;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapred.FileInputFormat;import org.apache.hadoop.mapred.FileOutputFormat;import org.apache.hadoop.mapred.JobClient;import org.apache.hadoop.mapred.JobConf;import org.apache.hadoop.mapred.TextInputFormat;import org.apache.hadoop.mapred.TextOutputFormat;public class CharCountDriver { public static void main(String[] args) throws IOException { JobConf conf = new JobConf(CharCountDriver.class); conf.setJobName("CharCount"); conf.setOutputKeyClass(Text.class); conf.setOutputValueClass(IntWritable.class); conf.setMapperClass(CharCountMapper.class); conf.setCombinerClass(CharCountReducer.class); conf.setReducerClass(CharCountReducer.class); conf.setInputFormat(TextInputFormat.class); conf.setOutputFormat(TextOutputFormat.class); FileInputFormat.setInputPaths(conf, new Path(args[0])); FileOutputFormat.setOutputPath(conf, new Path(args[1])); JobClient.runJob(conf); }} |
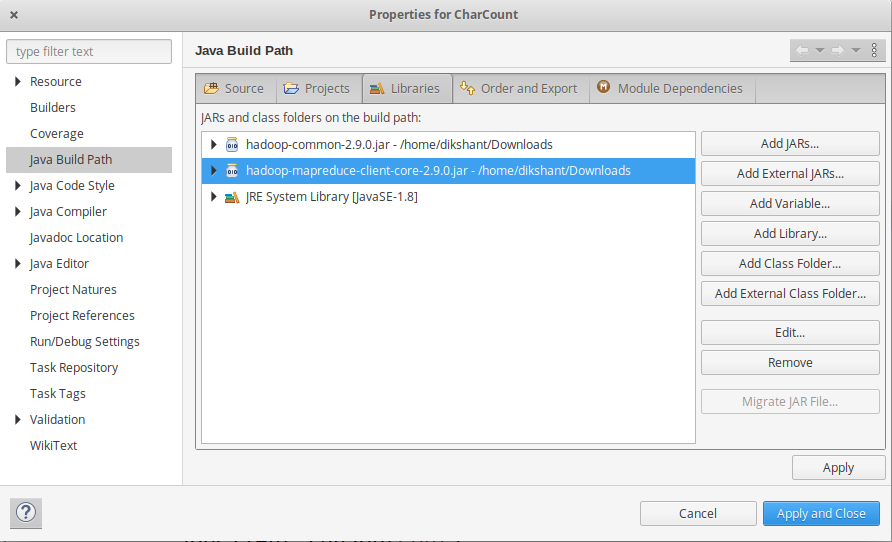
Шаг 3: Теперь нам нужно добавить внешнюю банку для пакетов, которые мы импортируем. Загрузите пакет jar Hadoop Common и Hadoop MapReduce Core в соответствии с вашей версией Hadoop. Вы можете проверить версию Hadoop с помощью следующей команды:
версия хадупа

Шаг 4: Теперь мы добавляем эти внешние jar-файлы в наш проект CharCount. Щелкните правой кнопкой мыши CharCount -> затем выберите Путь сборки -> Щелкните Настроить путь сборки и выберите Добавить внешние банки …. и добавьте банки из места загрузки, затем нажмите -> Применить и закрыть .
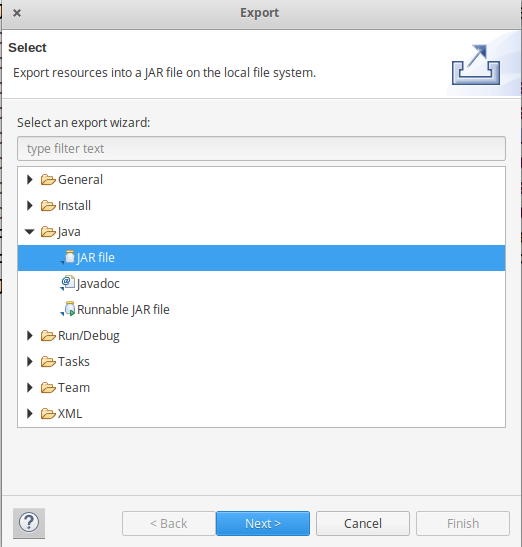
Шаг 5: Теперь экспортируйте проект как файл jar. Щелкните правой кнопкой мыши CharCount, выберите « Экспорт» ... и перейдите в раздел Java -> Файл JAR щелкните -> Далее и выберите место назначения для экспорта, затем нажмите -> Далее . Выберите основной класс как CharCount , нажав -> Обзор, а затем нажмите -> Готово -> ОК .
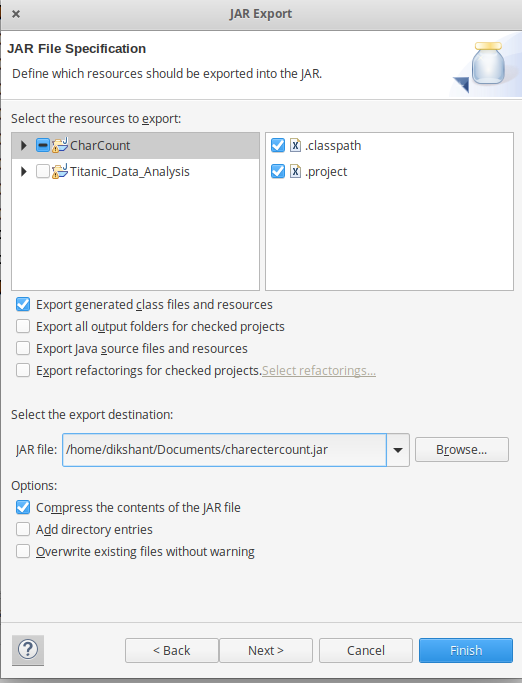
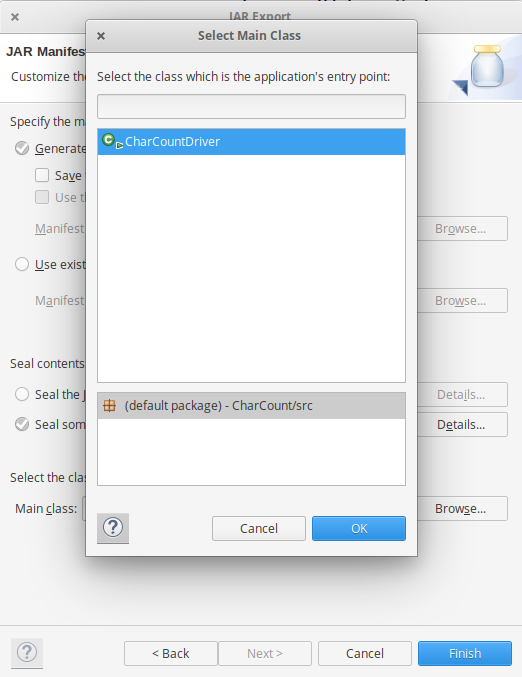
Теперь файл Jar успешно создан и сохранен в каталоге / Documents с именем charectercount.jar в моем случае.
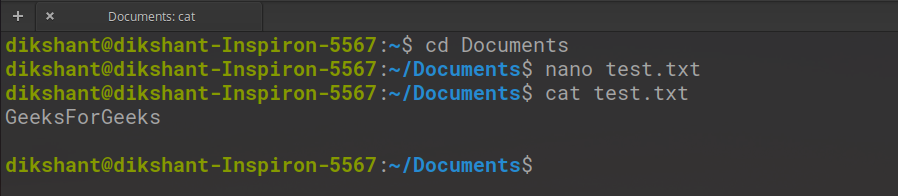
Шаг 6: Создайте простой текстовый файл и добавьте в него данные.
nano test.txt
Вы также можете добавить текст в файл вручную или с помощью другого редактора, например Vim или gedit.
Чтобы увидеть содержимое файла, используйте команду cat, доступную в Linux.
кошка test.txt
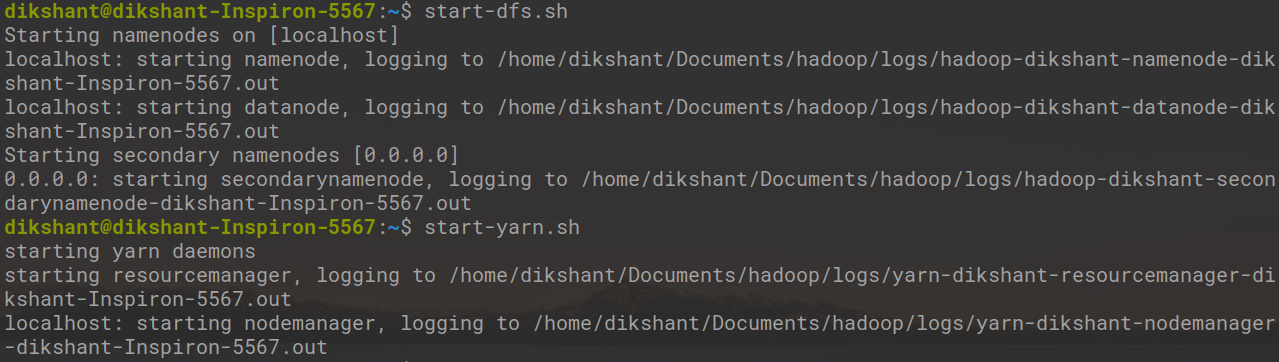
Шаг 7. Запустите наши демоны Hadoop
start-dfs.sh
start-yarn.sh
Шаг 8: Переместите файл test.txt в Hadoop HDFS.
Синтаксис:
hdfs dfs -put / путь_к_файлу / место назначения
В приведенной ниже команде / показан корневой каталог нашей HDFS.
hdfs dfs -put /home/dikshant/Documents/test.txt /
Убедитесь, что файл находится в корневом каталоге HDFS или нет.
hdfs dfs -ls /
![]()
Шаг 9: Теперь запустите файл Jar с помощью приведенной ниже команды и произведите вывод в файле CharCountResult.
Синтаксис:
хадуп jar / jar_file_location / dataset_location_in_HDFS / output-file_name
Команда:
банка hadoop /home/dikshant/Documents/charectercount.jar /test.txt / CharCountResult

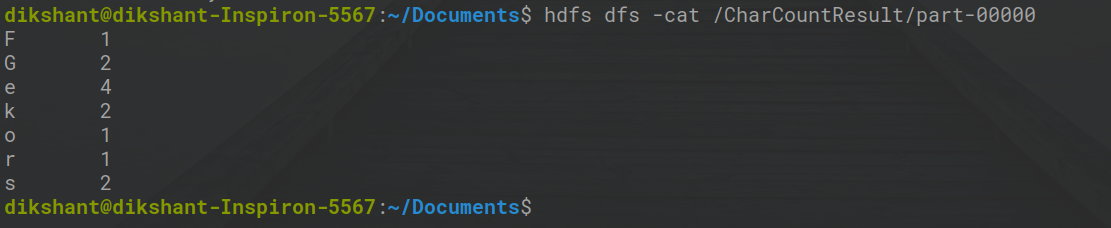
Шаг 10: Теперь перейдите на localhost: 50070 / , в разделе утилит выберите Обзор файловой системы и загрузите part-r-00000 в каталог / CharCountResult, чтобы увидеть результат. мы также можем проверить результат, то есть этот файл part-r-00000 с помощью команды cat, как показано ниже.
hdfs dfs -cat / CharCountResult / часть-00000