Как установить Hadoop в Linux?
Hadoop - это среда, написанная на Java для запуска приложений на большом кластере оборудования сообщества. Он похож на файловую систему Google. Чтобы установить Hadoop, нам сначала понадобится java, поэтому сначала мы устанавливаем java в наш Ubuntu.
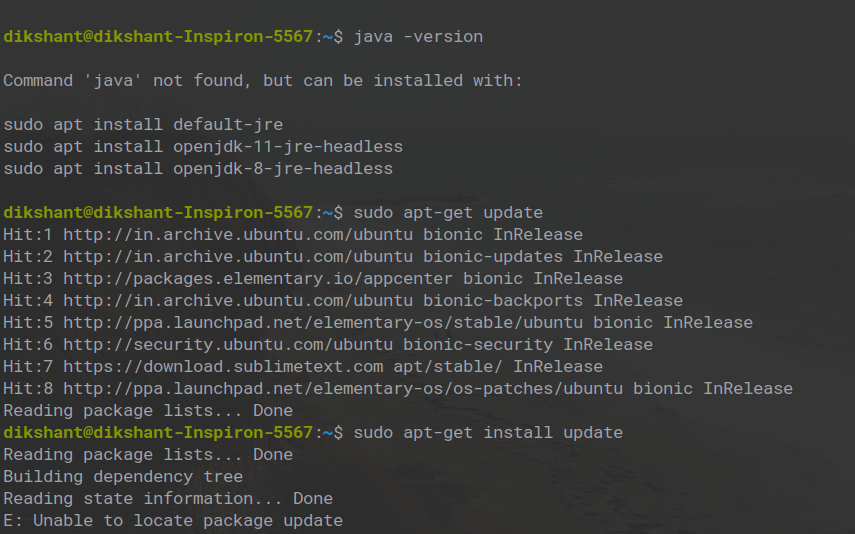
Шаг 1. Откройте свой терминал и сначала проверьте, оснащена ли ваша система Java или нет, с помощью команды
java -version
Шаг 2: Теперь пришло время обновить вашу систему. Ниже приведены 2 команды для обновления вашей системы.
sudo apt-get update
sudo apt-get install update
Шаг 3: Теперь мы установим JDK по умолчанию для java, используя следующую команду:
sudo apt-get install default-jdk
Вам будет предложено ввести Y / N, нажмите Y.
Шаг 4: Теперь проверьте, установлена ли Java, используя команду
java -version
Шаг 5: После установки нам потребуется специальный пользователь для этого. В этом нет необходимости, но сделать специального пользователя для установки Hadoop - это хорошо. Вы можете использовать следующую команду:
sudo addgroup hadoop

sudo adduser --ingroup hadoop hadoopusr

Шаг 6: Теперь, после выполнения двух вышеуказанных команд, вы успешно создали выделенного пользователя с именем hadoopusr . Теперь он запросит новый пароль UNIX, поэтому выбирайте пароль по своему усмотрению (убедитесь, что иногда он не отображает набираемый вами символ или цифру, поэтому запомните, что вы вводите). Затем он запросит у вас такую информацию, как полное имя и т. Д. Продолжайте нажимать клавишу ввода для значения по умолчанию, затем нажмите Y для получения правильной информации.

Шаг 7: Теперь используйте следующую команду:
sudo adduser hadoopusr sudo
С помощью этой команды вы добавляете свой «hadoopusr» в группу «sudo», чтобы мы также могли сделать его суперпользователем.

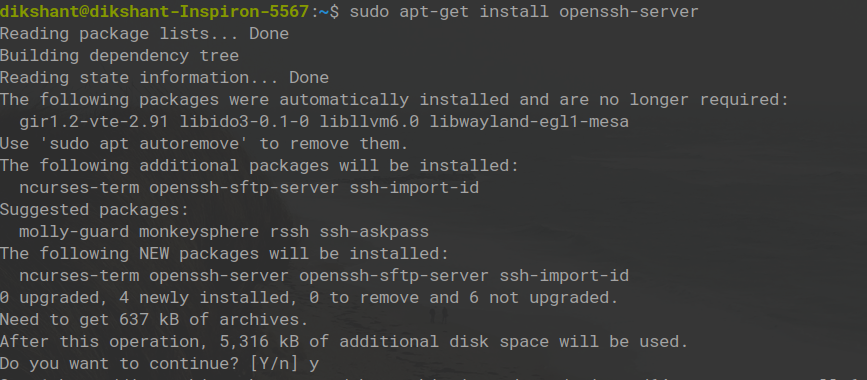
Шаг 8: Теперь нам также нужно установить ключ ssh, который является защищенной оболочкой.
sudo apt-get install openssh-server
Шаг 9: Теперь нам пора переключиться на нового пользователя hadoopusr, а также ввести пароль, который вы используете выше, команду для переключения пользователя:
su - hadoopusr

Шаг 10: Теперь пришло время сгенерировать ключ ssh, потому что Hadoop требует доступа ssh для управления своим узлом, удаленным или локальным компьютером, поэтому для нашего единственного узла настройки Hadoop мы настраиваем так, чтобы у нас был доступ к локальному хосту.
ssh-keygen -t rsa -P ""
После этой команды просто нажмите Enter .
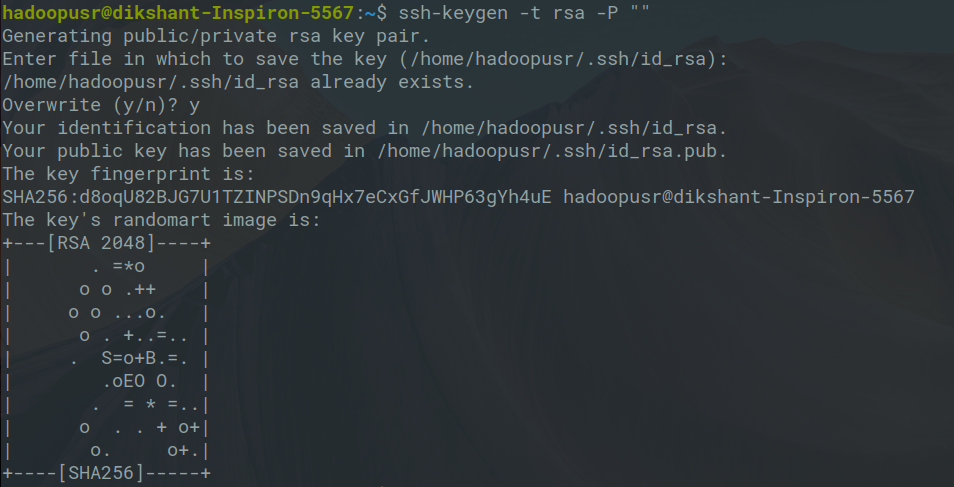
Шаг 11: Теперь мы используем приведенную ниже команду, потому что нам нужно добавить открытый ключ компьютера в авторизованный ключевой файл компьютера, к которому вы хотите получить доступ с помощью ключей ssh, поэтому мы запустили эту команду.
cat $ HOME / .ssh / id_rsa.pub >> $ HOME / .ssh / authorized_keys

Шаг 12: Теперь проверьте локальный хост, то есть ssh localhost с помощью приведенной ниже команды, нажмите « Да», чтобы продолжить, и введите свой пароль, если он спросит, затем введите exit.
ssh localhost
Теперь вы выполнили основные требования для установки Hadoop.
Шаг 13: Теперь загрузите пакет, который вы собираетесь установить. загрузите его из Hadoop-2.9.0, щелкнув файл, показанный на изображении ниже.

Шаг 14: После загрузки hadoop-2.9.0.tar.gz поместите этот tar-файл в желаемое место и извлеките его с помощью следующих команд. В моем случае я переместил его в папку / Documents.
Теперь мы извлекаем этот файл с помощью приведенной ниже команды и вводим ваш пароль hadoopusr. Если вы не знаете пароль, не волнуйтесь, вы можете просто сменить пользователя и изменить пароль в соответствии с вашими предпочтениями.
команда: sudo tar xvzf hadoop-2.9.0.tar.gz

Шаг 15: Теперь нам нужно переместить эту извлеченную папку пользователю hadoopusr, чтобы для этого типа приведенной ниже команды (убедитесь, что имя извлеченной папки - hadoop ):
sudo mv hadoop / usr / local / hadoop
Шаг 16: Теперь нам нужно изменить владельца, чтобы эта команда была:
sudo chown -R hadoopusr / usr / местный

Шаг 17: Это самый важный шаг, т.е. теперь мы собираемся настроить некоторые файлы, это действительно очень важно.
Сначала мы настраиваем наш файл ./bashrc , чтобы открыть этот файл, введите следующую команду:
sudo gedit ~ / .bashrc

Затем открывается файл ./bashrc, затем скопируйте приведенную ниже команду в этот файл (измените версию Java в соответствии с версией Java вашего ПК, например, это может быть java-8-openjdk-amd64).
экспорт JAVA_HOME = / usr / lib / jvm / java-11-openjdk-amd64 экспорт HADOOP_HOME = / usr / local / hadoop экспорт ПУТЬ = $ ПУТЬ: $ HADOOP_HOME / bin экспорт ПУТЬ = $ ПУТЬ: $ HADOOP_HOME / sbin экспорт HADOOP_MAPRED_HOME = $ HADOOP_HOME экспорт HADOOP_COMMON_HOME = $ HADOOP_HOME экспорт HADOOP_HDFS_HOME = $ HADOOP_HOME экспорт YARN_HOME = $ HADOOP_HOME экспорт HADOOP_COMMON_LIB_NATIVE_DIR = $ HADOOP_HOME / lib / native export HADOOP_OPTS = "- Djava.library.path = $ HADOOP_HOME / lib"
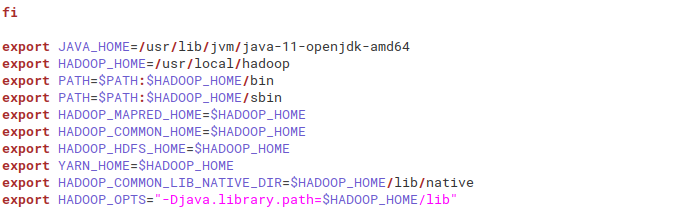
Затем проверьте, правильно ли вы его настроили.
источник ~ / .bashrc

Шаг 18: Перед настройкой дополнительных файлов сначала мы проверяем, какую версию java мы установили для этого, перейдите в местоположение / usr / lib / jvm и после перехода в это местоположение введите команду ls, чтобы вывести список файлов внутри него, теперь вы увидите версию java. , В моем случае это java-11-openjdk-amd64 .

Шаг 19: Теперь мы настроим hadoop-env.sh . Для этого откройте файл, используя команду ниже.
sudo gedit /usr/local/hadoop/etc/hadoop/hadoop-env.sh

После открытия файла скопируйте в него приведенную ниже команду экспорта и не забудьте прокомментировать уже существующую команду экспорта с помощью JAVA_HOME :
экспорт JAVA_HOME = / usr / lib / jvm / java-11-openjdk-amd64

Не забывайте экономить .
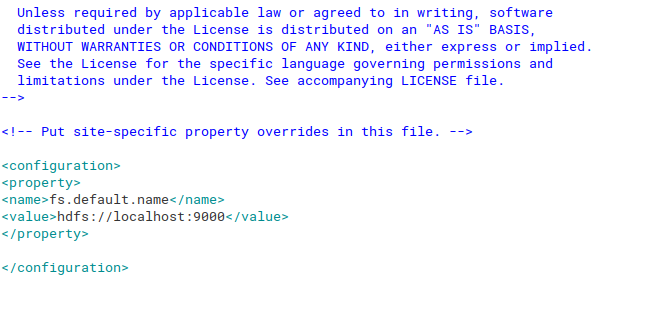
Шаг 20: Теперь мы настроим core-site.xml. Для этого откройте этот файл, используя команду ниже:
sudo gedit /usr/local/hadoop/etc/hadoop/core-site.xml

once the file opens copy the below text inside the configuration tag
См. Изображение ниже для лучшего понимания:
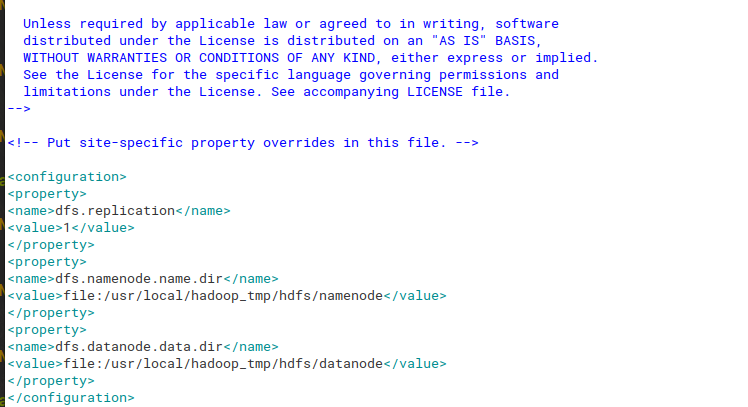
Шаг 21: Теперь мы настроим hdfs-site.xml для открытия этого файла с помощью приведенной ниже команды.
sudo gedit /usr/local/hadoop/etc/hadoop/hdfs-site.xml

Once the file opens copy the below text inside the configuration tag
<!-- <property><name>dfs.replication</name><value>1</value></property><property><name>dfs.namenode.name.dir</name><value>file:/usr/local/hadoop_tmp/hdfs/namenode</value></property><property><name>dfs.datanode.data.dir</name><value>file:/usr/local/hadoop_tmp/hdfs/datanode</value></property> --> |
См. Изображение ниже для лучшего понимания:
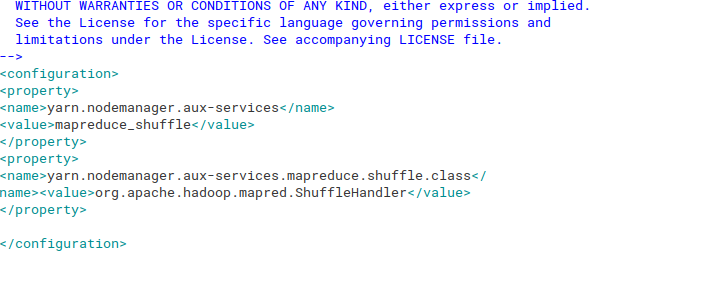
Шаг 22: Теперь мы настроим yarn-site.xml, который отвечает за выполнение файла в среде Hadoop. Для этого откройте этот файл, используя команду ниже:
sudo gedit /usr/local/hadoop/etc/hadoop/yarn-site.xml

once the file opens copy the below text inside the configuration tag
<!-- <property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name><value>org.apache.hadoop.mapred.ShuffleHandler</value></property> --> |
См. Изображение ниже для лучшего понимания:
Шаг 23. Теперь последний файл для настройки - mapred-site.xml. Для этого у нас есть mapred-site.xml.template, поэтому нам нужно найти этот файл, затем скопировать его в это место и затем переименовать .
Итак, чтобы найти файл, нам нужно перейти в папку / usr / local / hadoop / etc / hadoop /, чтобы скопировать этот файл, а также переименовать файл в single, используйте следующую команду
sudo cp /usr/local/hadoop/etc/hadoop/mapred-site.xml.template /usr/local/hadoop/etc/hadoop/mapred-site.xml

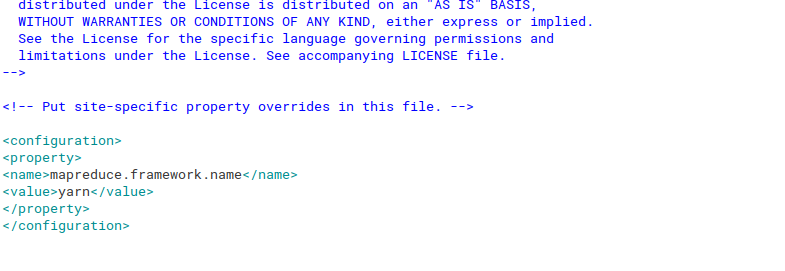
как только файл будет скопирован или переименован, откройте этот файл, используя следующую команду:
sudo gedit /usr/local/hadoop/etc/hadoop/mapred-site.xml

And then place the below content inside its configuration tag.
<!-- <property><name>mapreduce.framework.name</name><value>yarn</value></property> --> |
См. Изображение ниже для лучшего понимания:
Шаг 24: Теперь мы успешно настроили все файлы. Итак, пришло время проверить нашу установку. Как мы знаем, в архитектуре Hadoop у нас есть узел имени и другие блоки, поэтому нам нужно создать один каталог, то есть hadoop_space. Внутри этого каталога мы создаем еще один каталог, то есть hdfs, namenode и datanode. Команда для создания каталога приведена ниже:
sudo mkdir -p / usr / local / hadoop_space sudo mkdir -p / usr / local / hadoop_space / hdfs / namenode sudo mkdir -p / usr / local / hadoop_space / hdfs / datanode
Теперь нам нужно дать разрешение на следующие команды:
sudo chown -R hadoopusr / usr / local / hadoop_space

Запуск Hadoop
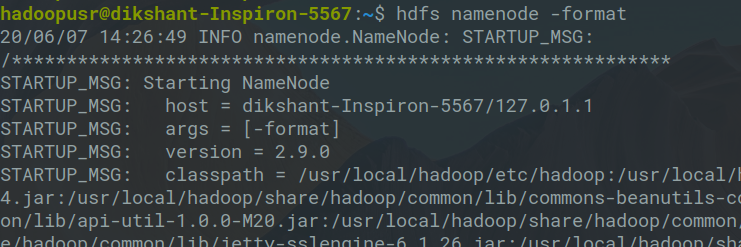
1. Во-первых, нам нужно отформатировать namenode, затем вам нужно запустить приведенную ниже команду в первый раз, когда вы запускаете кластер, если вы используете его снова, тогда все ваши метаданные будут удалены.
hdfs namenode -format
2. Теперь нам нужно запустить DFS, то есть распределенную файловую систему.
start-dfs.sh

3. Теперь последнее, что вам нужно начать, это пряжа.
start-yarn.sh

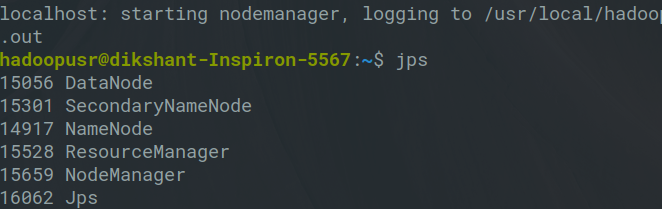
4. Теперь используйте следующую команду:
jps
Теперь вы сможете увидеть SecondaryNameNode, NodeManager, ResourceManager, NameNode, jpd и DataNode, что означает, что вы успешно установили Hadoop.
5. Вы успешно установили hadoop в своей системе. Теперь, чтобы проверить всю информацию о кластере, вы можете использовать localhost: 50070 в своем браузере. Интерфейс будет выглядеть так: