Как создать таблицу в Hive?
В Apache Hive мы можем создавать таблицы для хранения структурированных данных, чтобы позже мы могли их обработать. Таблица в улье состоит из нескольких столбцов и записей. Таблица, которую мы создаем в любой базе данных, будет храниться в подкаталоге этой базы данных. По умолчанию база данных хранится в HDFS / user / hive / inventory. Способ создания таблиц в улье очень похож на способ создания таблиц в SQL. Мы можем выполнять различные операции с этими таблицами, такие как объединения, фильтрация и т. Д.
Чтобы выполнить описанную ниже операцию, убедитесь, что ваш улей работает. Ниже приведены инструкции по запуску куста в вашей локальной системе.
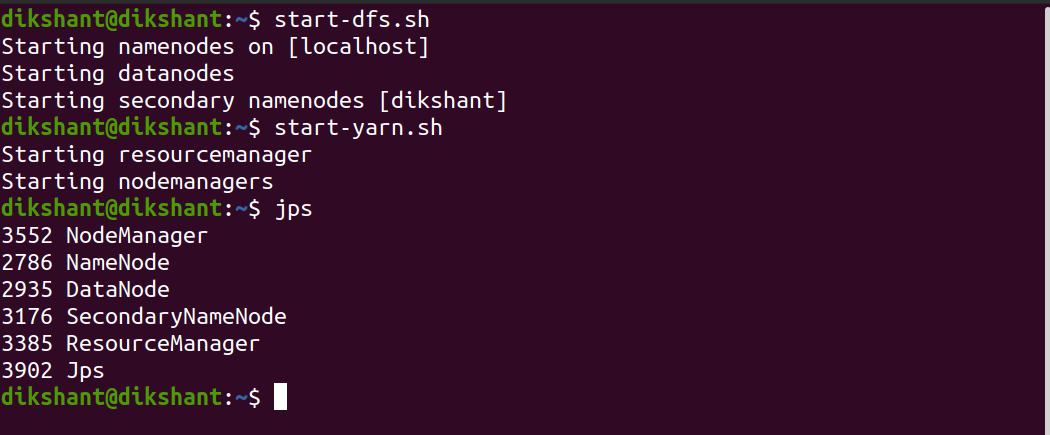
Шаг 1. Запустите все свои Hadoop Daemon
start-dfs.sh # это запустит namenode, datanode и вторичный namenode start-yarn.sh # это запустит диспетчер узлов и диспетчер ресурсов jps # Чтобы проверить запущенные демоны
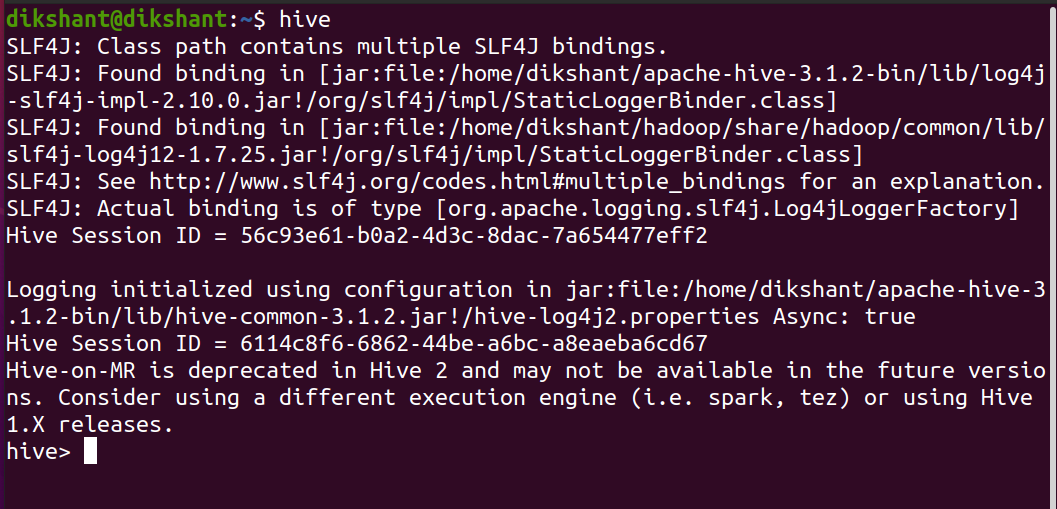
Шаг 2. Запустите куст с терминала
hive
Создание таблицы в Hive
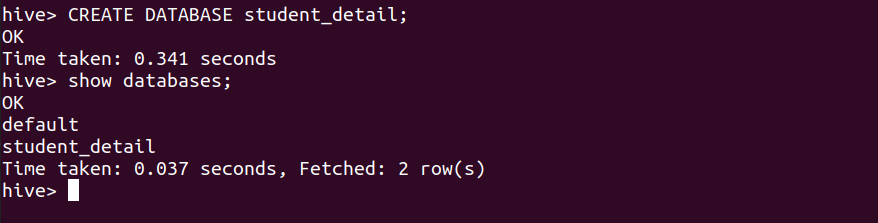
Давайте сначала создадим базу данных, чтобы мы могли создавать внутри нее таблицы. Команда для создания базы данных показана ниже.
Синтаксис для создания базы данных:
СОЗДАТЬ БАЗУ ДАННЫХ <имя-базы-данных>;
Команда:
СОЗДАТЬ БАЗУ ДАННЫХ student_detail; # это создаст базу данных student_detail ПОКАЗАТЬ БАЗЫ ДАННЫХ; # перечислить все доступные базы данных
Теперь, чтобы иметь доступ к этой базе данных, мы должны ее использовать.
Синтаксис:
ИСПОЛЬЗУЙТЕ <имя-базы-данных>;
Команда:
USE student_detail;

Синтаксис для создания таблицы в Hive
СОЗДАТЬ ТАБЛИЦУ [ЕСЛИ НЕ СУЩЕСТВУЕТ] <имя-таблицы> ( <имя-столбца> <тип-данных>, <имя-столбца> <тип-данных> КОММЕНТАРИЙ "Ваш комментарий", <имя-столбца> <тип-данных>, . . . <имя-столбца> <тип-данных> ) КОММЕНТАРИЙ "Добавьте, если хотите" МЕСТО "Расположение на HDFS" ФОРМАТ СТРОКИ УДАЛЕН ПОЛЯ, ЗАКОНЧЕННЫЕ ',';
Примечание:
1. Мы можем добавить комментарий как к таблице, так и к каждому отдельному столбцу.
2. ФОРМАТ СТРОКИ УДАЛЕН показывает, что всякий раз, когда встречается новая строка, начинается запись новой записи.
3. FIELDS TERMINATED BY ',' показывает, что мы используем разделитель ',' для разделения каждого столбца.
4. Мы также можем изменить расположение базы данных по умолчанию с помощью параметра LOCATION.
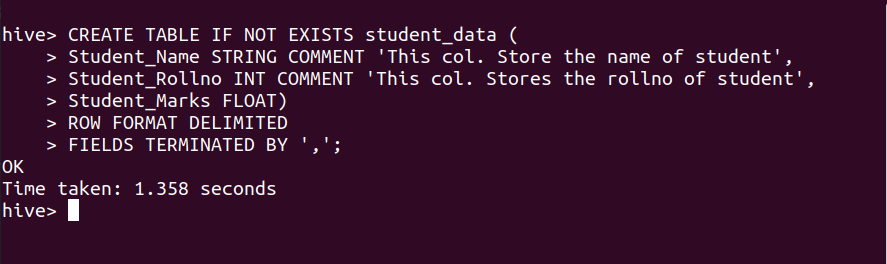
Итак, давайте создадим таблицу student_data в нашей базе данных student_detail с помощью команды, показанной ниже.
СОЗДАТЬ ТАБЛИЦУ, ЕСЛИ НЕ СУЩЕСТВУЕТ student_data ( Student_Name STRING КОММЕНТАРИЙ 'Это col. Сохраните имя студента », Student_Rollno INT КОММЕНТАРИЙ 'This col. Хранит ролл студента », Student_Marks FLOAT) ФОРМАТ СТРОКИ УДАЛЕН ПОЛЯ, ЗАКОНЧЕННЫЕ ',';
Мы успешно создали таблицу student_data в нашей базе данных student_detail с 3 различными полями Student_Name, Student_Rollno, Student_Marks как STRING, INT, FLOAT соответственно.
Мы можем перечислить таблицу, доступную в нашей базе данных, с помощью команды, описанной ниже.
Синтаксис:
ПОКАЗАТЬ ТАБЛИЦЫ [В <database_name>];
Команда:
ПОКАЗАТЬ ТАБЛИЦЫ В student_detail;

Теперь, наконец, давайте проверим местоположение на HDFS , где производится наша student_detail базы данных и student_data таблицы. Переместитесь на localhost: 50070 / для Hadoop 2 и на localhost: 9870 / для Hadoop 3. Затем Utilities -> Просмотрите файловую систему и перейдите в / user / hive / хранилище, где по умолчанию создаются базы данных кустов.
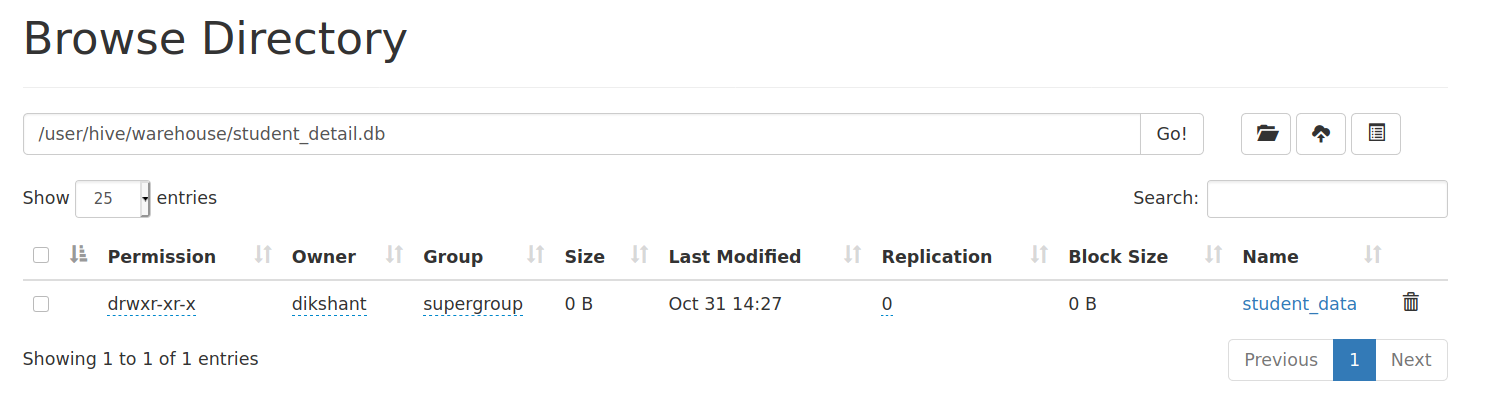
На изображении выше мы видим, что таблица student_data доступна в HDFS внутри student_detail.db .