Интеллектуальный анализ текста в интеллектуальном анализе данных
Быстрое увеличение компьютеризированной или цифровой информации привело к появлению огромного объема информации и данных. Значительная часть доступной информации хранится в текстовых базах данных, которые состоят из больших коллекций документов из различных источников. Текстовые базы данных быстро растут из-за увеличения объема информации, доступной в электронной форме. Более 80% настоящей информации представлено в виде неструктурированных или полуорганизованных данных. Традиционные методы поиска информации становятся неадекватными для постоянно растущего объема текстовых данных. Таким образом, интеллектуальный анализ текста становится все более популярной и важной частью интеллектуального анализа данных. Обнаружение правильных шаблонов и анализ текстового документа из огромного объема данных является серьезной проблемой в реальных прикладных областях.
“Extraction of interesting information or patterns from data in large databases is known as data mining.”
Интеллектуальный анализ текста — это процесс извлечения полезной информации и нетривиальных шаблонов из большого объема текстовых баз данных. Существуют различные стратегии и устройства для анализа текста и поиска важных данных для процесса прогнозирования и принятия решений. Выбор правильной и точной процедуры анализа текста помогает повысить скорость и временную сложность. В этой статье кратко обсуждается и анализируется интеллектуальный анализ текста и его приложения в различных областях.
“Text Mining is the procedure of synthesizing information, by analyzing relations, patterns, and rules among textual data.”
Как мы уже говорили выше, объем информации увеличивается экспоненциально. Сегодня все институты, компании, различные организации и коммерческие предприятия хранят свою информацию в электронном виде. Огромная коллекция данных, доступных в Интернете и хранящихся в цифровых библиотеках, репозиториях баз данных и других текстовых данных, таких как веб-сайты, блоги, социальные сети и электронные письма. Трудно определить подходящие закономерности и тенденции для извлечения знаний из этого большого объема данных. Интеллектуальный анализ текста является частью интеллектуального анализа данных для извлечения ценной текстовой информации из репозитория текстовой базы данных. Анализ текста — это междисциплинарная область, основанная на восстановлении данных, анализе данных, искусственном интеллекте, статистике, машинном обучении и компьютерной лингвистике.
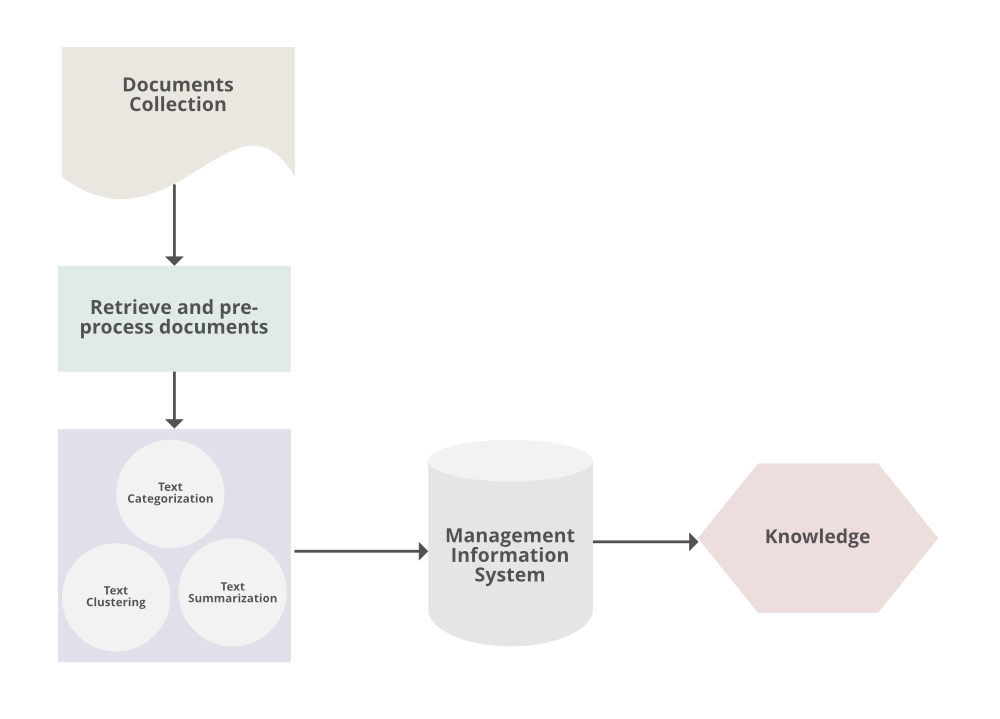
Обычный процесс интеллектуального анализа текста выглядит следующим образом:
- Сбор неструктурированной информации из различных источников, доступных в различных организациях документов, например, обычный текст, веб-страницы, записи в формате PDF и т. д.
- Задачи предварительной обработки и очистки данных выполняются для выявления и устранения несогласованности данных. Процесс очистки данных гарантирует захват подлинного текста и выполняется для устранения образования стоп-слов (процесс определения корня определенного слова и индексации данных.
- Задачи обработки и контроля применяются для просмотра и дальнейшей очистки набора данных.
- Анализ закономерностей реализован в Информационной системе управления.
- Информация, обработанная на вышеуказанных этапах, используется для извлечения важных и применимых данных для эффективного и удобного процесса принятия решений и анализа тенденций.
Процедуры анализа Text Mining:
- Суммирование текста: для автоматического извлечения частичного содержимого, отражающего все его содержимое.
- Категоризация текста: чтобы назначить категорию тексту среди категорий, предварительно определенных пользователями.
- Кластеризация текста: сегментация текстов на несколько кластеров в зависимости от существенной релевантности.
Методы интеллектуального анализа текста:
- Извлечение информации : это процесс извлечения значимых слов из документов.
- Поиск информации : это процесс извлечения релевантных и связанных шаблонов в соответствии с заданным набором слов или текстовых документов.
- Обработка естественного языка: речь идет об автоматической обработке и анализе неструктурированной текстовой информации.
- Кластеризация: это неконтролируемый процесс обучения, который группирует текст в соответствии с их схожими характеристиками.
- Суммирование текста: для автоматического извлечения частичного отражения содержимого всего содержимого.
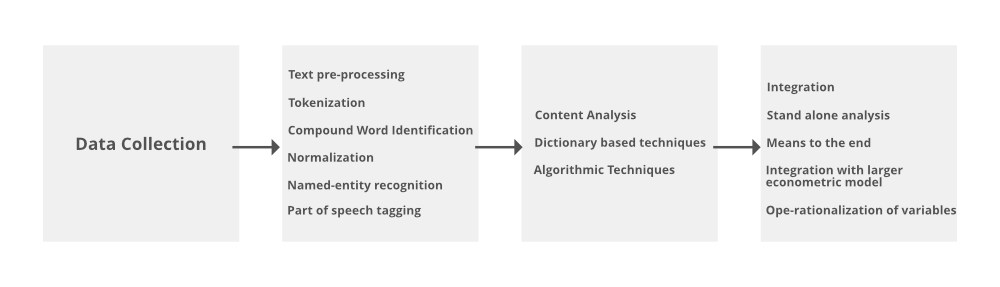
Обзор методов анализа текста
Фаза процесса интеллектуального анализа текста | Алгоритм | Выбранный вопрос | Мотив | Техники | |
|---|---|---|---|---|---|
| 1. Этап предварительной обработки текста | Токенизация | Как преобразовать текст в слова или текстовый формат? | Перенос строк в единый текстовый токен. | Разделение белого пространства. | |
| Идентификация сложного слова | Как определить слова, имеющие общее значение? | Выявление слов с общим значением, которое теряется | п-грамм | ||
| Нормализация и шумоподавление | Как я могу справиться со слишком большим количеством переменных в моей Document-Term-Matrix? | Уменьшение размерности Document-Term-Matrix | Стемминг, лемматизация, удаление стоп-слов. нечастый срок. | ||
| Лингвистический анализ | Как определить слова с особым значением или грамматической функцией? | Тегирование слов | Распознавание именованных объектов, маркировка частей речи | ||
| 2. Контент-анализ | на основе словаря | Как определить, насколько скрытые социологические или психологические черты и состояния отражаются в естественном языке? | Измерение контекстуальных, психологических, лингвистических или семантических понятий и конструкций | предопределенные словари Индивидуальные словари | |
| Алгоритмические методы | Как я могу назначить тексты предопределенным классам? | Классификация текстовых объектов по предопределенным категориям | Методы контролируемого обучения, такие как бинарные или многоклассовые классификаторы | ||
| Как сгруппировать похожие документы? | Кластеризация текстовых объектов в ранее неопределенные и неизвестные | Неконтролируемые методы обучения, такие как LDA, k-средние или неотрицательные |
Область применения интеллектуального анализа текста
1. Электронная библиотека
Различные стратегии и инструменты интеллектуального анализа текста используются для получения шаблонов и тенденций из журналов и материалов, которые хранятся в репозиториях текстовых баз данных. Эти ресурсы информации помогают в области исследования области. Библиотеки являются хорошим источником текстовых данных в цифровой форме. Это дает новую технику для получения полезных данных таким образом, что делает возможным доступ к миллионам записей в Интернете. Международная цифровая библиотека Green Stone, поддерживающая многочисленные языки и многоязычные интерфейсы, обеспечивает удобный способ извлечения отчетов, которые обрабатывают различные форматы, например, Microsoft Word, PDF, Postscript, HTML, языки сценариев и электронную почту. Он дополнительно поддерживает извлечение аудиовизуальных форматов и форматов изображений вместе с текстовыми документами. Процессы интеллектуального анализа текста выполняют различные действия, такие как сбор документов, определение, улучшение, удаление данных и обработка веществ, а также создание сводки. Существуют различные типы инструментов для интеллектуального анализа текста в цифровых библиотеках, а именно: GATE, Net Owl и Aylien, которые используются для интеллектуального анализа текста.
2. Академическая и исследовательская область
В сфере образования используются различные инструменты и стратегии анализа текста для изучения поучительных шаблонов в конкретном регионе/области исследования. Основная цель использования интеллектуального анализа текста в области исследований — помочь найти и упорядочить исследовательские работы и соответствующие материалы из различных областей на одной платформе. Для этого мы используем кластеризацию k-средних, и различные стратегии помогают различать свойства значимых данных. Кроме того, можно получить доступ к успеваемости учащихся по различным предметам и тому, как различные качества влияют на выбор предметов, оцениваемых этим анализом.
3. Наука о жизни
Отрасли медико-биологической науки и здравоохранения производят огромный объем текстовых и математических данных, касающихся историй болезни, болезней, лекарств, симптомов и методов лечения заболеваний и т. д. Фильтрация данных и релевантного текста для принятия решений на основе биологического анализа является серьезной проблемой. хранилище данных. Клинические записи содержат переменные данные, которые непредсказуемы, длинны. Интеллектуальный анализ текста может помочь в управлении такими данными. Использование интеллектуального анализа текста для раскрытия информации о биомаркерах, фармацевтической промышленности, клиническом анализе торговли, клинических исследованиях, патентной конкурентной разведке.
4. Социальные сети
Интеллектуальный анализ текста доступен для анализа веб-приложений мультимедиа для мониторинга и исследования онлайн-контента, такого как обычный текст из интернет-новостей, веб-журналов, электронной почты, блогов и т. д. Устройства для анализа текста помогают различать и исследовать количество сообщений, лайков и подписчиков в сети Интернет-СМИ. Этот вид анализа показывает реакцию людей на различные посты, новости и то, как они распространяются. Он показывает поведение людей, принадлежащих к определенной возрастной группе, и различия в лайках и просмотрах одного и того же поста.
5. Бизнес-аналитика
Интеллектуальный анализ текста играет важную роль в бизнес-аналитике, которая помогает различным организациям и предприятиям анализировать своих клиентов и конкурентов для принятия более эффективных решений. Он дает точное представление о бизнесе и дает данные о том, как повысить удовлетворенность потребителей и получить конкурентные преимущества. Устройства для анализа текста, такие как текстовая аналитика IBM.
GATE помогает принять решение об организации, которая выдает предупреждения о хороших и плохих показателях, о смене рынка, которая помогает предпринять необходимые действия. Этот майнинг можно использовать в телекоммуникационном секторе, коммерции, системе управления цепочками клиентов.
Проблемы в анализе текста
В процессе интеллектуального анализа текста возникает множество проблем:
1. Оперативность и результативность принятия решений.
2. Неопределенная проблема может возникнуть на промежуточном этапе анализа текста. На этапе предварительной обработки описываются различные правила и рекомендации для нормализации текста, что делает процесс интеллектуального анализа текста эффективным. Перед применением анализа шаблонов к документу необходимо преобразовать неструктурированные данные в умеренную структуру.
3. Иногда исходное сообщение или смысл могут быть изменены из-за переделки.
4. Еще одна проблема интеллектуального анализа текста заключается в том, что многие алгоритмы и методы поддерживают многоязычный текст. Это может создать двусмысленность в значении текста. Эта проблема может привести к ложноположительным результатам.
5. Использование синонимов, полисемий и антонимов в тексте документа создает проблемы для инструментов анализа текста, которые используют и то, и другое в одинаковых условиях. Трудно классифицировать такие виды текста/слов.