Интеграция Hadoop и языка программирования R
Hadoop - это среда с открытым исходным кодом, представленная ASF - Apache Software Foundation . Hadoop - это самая важная платформа для работы с большими данными. Hadoop был написан на Java, и это не на основе OLAP (онлайн-аналитическая обработка). Лучшая часть этой платформы больших данных заключается в том, что она масштабируема и может быть развернута для любого типа данных в различных разновидностях, таких как структурированный, неструктурированный и полуструктурированный. Hadoop - это инструмент промежуточного программного обеспечения, который предоставляет нам платформу, которая управляет большим и сложным кластером компьютеров, который был разработан на Java, и хотя Java является основным языком программирования для Hadoop, другие языки могут использоваться для R, Python или Ruby.
Фреймворк Hadoop включает:
- Распределенная файловая система Hadoop (HDFS) - это файловая система, которая обеспечивает надежную распределенную файловую систему. У Hadoop есть структура, которая используется для планирования заданий и управления ресурсами кластера, имя которой - YARN.
- Hadoop MapReduce - это система для параллельной обработки больших наборов данных, реализующая модель распределенного программирования MapReduce.
Hadoop расширяет более простое распределенное хранилище с помощью HDFS и предоставляет систему анализа через MapReduce. Он имеет хорошо спроектированную архитектуру для увеличения или уменьшения размеров серверов в соответствии с требованиями пользователя от одного до сотен или тысяч компьютеров с высокой степенью отказоустойчивости. Hadoop доказал свою безупречную потребность и стандарты в обработке больших данных и эффективном управлении хранилищем, он обеспечивает неограниченную масштабируемость и поддерживается основными поставщиками программного обеспечения.
Поскольку мы знаем, что данные - это драгоценная вещь, которая имеет наибольшее значение для организации, и не будет преувеличением, если мы скажем, что данные являются самым ценным активом. Но для того, чтобы иметь дело с этой огромной структурой и неструктурированной, нам нужен эффективный инструмент, который мог бы эффективно проводить анализ данных, поэтому мы получаем этот инструмент, объединив функции как языка R, так и фреймворка Hadoop для анализа больших данных. масштабируемость. Следовательно, нам нужно интегрировать и то, и другое, только тогда мы сможем найти более точную информацию и результат на основе данных. Вскоре мы рассмотрим различные методологии, которые помогут интегрировать эти две.
R - это язык программирования с открытым исходным кодом, который широко используется для статистического и графического анализа. R поддерживает большое количество статистико-математических библиотек (линейное и нелинейное моделирование, классические статистические тесты, анализ временных рядов, классификация данных, кластеризация данных и т. Д.) И графических методов для эффективной обработки данных.
Одним из основных качеств R является то, что он с большей легкостью создает хорошо продуманные качественные графики, включая математические символы и формулы, где это необходимо. Если вы находитесь в кризисе сильных функций анализа данных и визуализации, то объединение этого языка R с Hadoop в вашу задачу будет для вас последним выбором, позволяющим снизить сложность. Это очень расширяемый объектно-ориентированный язык программирования с сильными графическими возможностями.
Некоторые причины, по которым R считается наиболее подходящим для анализа данных:
- Надежный набор пакетов
- Мощные методы визуализации данных
- Похвальные функции статистического и графического программирования
- Объектно-ориентированный язык программирования
- Имеет широкий интеллектуальный набор операторов для вычисления массивов, отдельных матриц и т. Д.
- Возможность графического представления на дисплее или на бумажном носителе.
Основной мотив интеграции R и Hadoop:
Нет никаких подозрений, что R является наиболее популярным языком программирования для статистических вычислений, графического анализа данных, анализа данных и визуализации данных. С другой стороны, Hadoop - это мощный фреймворк Bigdata, способный обрабатывать большие объемы данных. Во всей обработке и анализе данных распределенная файловая система (HDFS) Hadoop играет жизненно важную роль.Она применяет подход обработки сокращения карты во время обработки данных (предоставляется пакетом rmr R Hadoop), что делает процесс анализа данных более эффективным. эффективно и проще.
Что произойдет, если оба будут сотрудничать друг с другом? Очевидно, что эффективность процесса управления и анализа данных многократно возрастет. Итак, чтобы добиться эффективности в процессе анализа данных и визуализации, мы должны объединить R с Hadoop.
После объединения этих двух технологий статистические вычислительные мощности R увеличиваются, после чего мы получаем возможность:
- Используйте Hadoop для выполнения кодов R.
- Используйте R для доступа к данным, хранящимся в Hadoop.
Несколько способов, с помощью которых можно интегрировать как R, так и Hadoop:
Наиболее популярные и часто используемые методы показаны ниже, но есть и другие методы RODBC / RJDBC, которые можно использовать, но они не так популярны, как методы ниже. Общая архитектура инструментов аналитики, интегрированных с Hadoop, показана ниже вместе с их различной многоуровневой структурой.
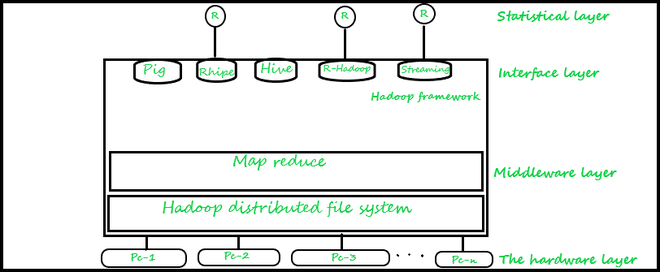
Первый уровень: это аппаратный уровень - он состоит из кластера компьютерных систем,
Второй слой: это уровень промежуточного программного обеспечения Hadoop. Этот уровень также обеспечивает безупречное распределение файлов за счет использования HDFS и функций задания MapReduce.
Третий уровень: это интерфейсный уровень, который обеспечивает интерфейс для анализа данных. На этом уровне мы можем использовать эффективный инструмент, такой как Pig, который предоставляет нам платформу высокого уровня для создания программ MapReduce с использованием языка, который мы назвали Pig-Latin. Мы также можем использовать Hive, инфраструктуру хранилища данных, разработанную Apache и построенную на основе Hadoop. Hive предоставляет нам ряд средств для выполнения сложных запросов и помогает анализировать данные с помощью SQL-подобного языка под названием HiveQL, а также расширяет поддержку для реализации задач MapReduce.
Помимо использования Hive и Pig, мы также можем использовать библиотеки Rhipe или Rhadoop, которые создают интерфейс для обеспечения интеграции между Hadoop и R и позволяют пользователям получать доступ к данным из файловой системы Hadoop и позволяют писать собственный сценарий для реализации заданий Map и Reduce. , или мы также можем использовать Hadoop-streaming, технологию, которая используется для интеграции Hadoop.
a) R Hadoop: метод R Hadoop включает четыре следующих пакета:
- Пакет rmr - пакет rmr предоставляет функциональные возможности Hadoop MapReduce в R. Итак, программисту R достаточно просто разделить логику и идею своего приложения на карту и сократить количество связанных фаз и просто отправить их с помощью методов rmr. После этого пакет rmr выполняет вызов потоковой передачи Hadoop и API MapReduce через несколько параметров задания, таких как входной каталог, выходной каталог, редуктор, преобразователь и т. Д., Чтобы выполнить задание R MapReduce в кластере Hadoop (большинство компонентов аналогичны потоковой передаче Hadoop).
- Пакет rhbase - позволяет разработчику R подключать Hadoop HBASE к R с помощью Thrift Server. Он также предлагает такие функции, как (чтение, запись и изменение таблиц, хранящихся в HBase, из R).
Скрипт, использующий функциональность RHаdoop, выглядит как на рисунке ниже.
библиотека (rmr)
map <-функция (k, v) {...}
уменьшить <-функцию (k, vv) {...}
уменьшение карты(
input = "data.txt",
output = "вывод",
textinputformat = rawtextinputformat,
карта = карта,
уменьшить = уменьшить
)- Пакет rhdfs - обеспечивает управление файлами HDFS в R, поскольку сами данные хранятся в файловой системе Hadoop . Функции этого пакета следующие. Манипуляции с файлами - (hdfs.delete, hdfs.rm, hdfs.del, hdfs.chown, hdfs.put, hdfs.get и т. Д.), Чтение / запись файлов - (hdfs.flush, hdfs.read, hdfs.seek, hdfs. tell, hdfs.line.reader и т. д.), каталог -hdfs.dircreate, hdfs.mkdir, инициализация: hdfs.init, hdfs.defaults.
- Пакет plyrmr - он предоставляет такие функции, как манипулирование данными, сводки выходных результатов, выполнение операций над наборами (объединение, пересечение, вычитание, слияние, уникальность).
б) RHIPE: Райп используется в R для выполнения сложного анализа большого набора наборов данных с помощью Hadoop - это интегрированный инструмент среды программирования, предоставляемый компанией Divide and Recombine (D&R) для анализа огромного количества данных.
RHIPE = R и интегрированная среда программирования Hadoop
RHIPE - это пакет R, который позволяет использовать API в Hadoop. Таким образом, мы можем читать, сохранять полные данные, созданные с помощью RHIPE MapReduce. RHIPE имеет множество функций, которые помогают нам эффективно взаимодействовать с HDFS. Человек также может использовать различные языки, такие как Perl, Java или Python, для чтения наборов данных в RHIPE. Общая структура сценария R , использующего Rhipe , показана ниже.
библиотека (Райп)
rhint (ИСТИНА, ИСТИНА);
карта <-выражение ({lapply (map.values, function (mapper) ...)})
уменьшить <-выражение (
pre = {...},
уменьшить = {...},
post = {...},}
х <- rhmr (
карта = карта, уменьшить = уменьшить,
ifolder = inputPath,
ofolder = outputPath,
inout = c ('текст', 'текст'),
jobname = 'название вакансии'))
rhex (z)Rhipe позволяет пользователю R создавать задания MapReduce (пакет rmr также помогает выполнить эту работу), которые полностью работают в среде R с использованием выражений R. Эта функциональность MapReduce: позволяет аналитику быстро определять карты и сокращения, используя всю мощь, гибкость и выразительность интерпретируемого языка R.
c) Коннектор Oracle R для Hadoop (ORCH):
Orch - это набор пакетов R, которые предоставляют следующие функции.
- Различные привлекательные интерфейсы для работы с данными, хранящимися в таблицах Hive, способные использовать вычислительную инфраструктуру на основе Apache Hadoop, а также предоставляют локальную среду R и таблицы базы данных Oracle.
- Используем метод прогнозной аналитики, написанный на R или Java как задания Hadoop MapReduce, который можно применять к данным, хранящимся в файлах HDFS.
После установки этого пакета в R вы сможете выполнять следующие различные функции.
- Возможность упростить доступ и преобразовать данные HDFS с помощью слоя прозрачности с поддержкой Hive для общего использования,
- Мы даем возможность эффективно использовать язык R для написания мапперов и редукторов,
- Копирование данных из памяти R в локальную файловую систему, в HDFS, в Hive и в базы данных Oracle,
- Возможность легко планировать программы R, чтобы выполнять программу как задания Hadoop MapReduce и возвращать результаты в любое из этих соответствующих мест и т. Д.
Oracle R Connector для Hadoop обеспечивает доступ с локального клиента R к Apache Hadoop, используя следующие префиксы функций:
- Hadoop - определяет функции, которые предоставляют интерфейс для Hadoop MapReduce.
- hdfs - определяет функции, обеспечивающие интерфейс для HDFS.
- Орч - определяет множество функций; orch - это общий префикс для функций ORCH.
- Ore - определяет функции, обеспечивающие интерфейс для хранилища данных Hive.
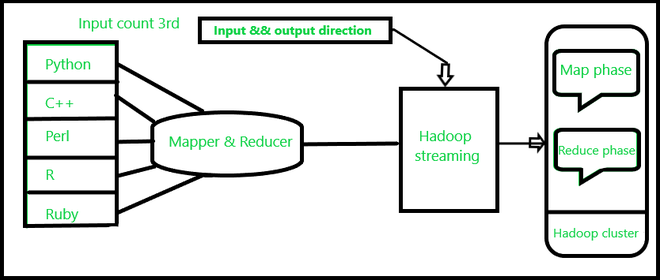
d) Потоковая передача Hadoop : потоковая передача Hadoop - это утилита Hadoop для запуска задания Hadoop MapReduce с исполняемыми скриптами, такими как Mapper и Reducer. Скрипт доступен как часть пакета R на CRAN. И его цель - сделать R более доступным для приложений на основе потоковой передачи Hadoop.
Это просто соответствует работе конвейера в Linux. При этом текстовый входной файл печатается в потоке (stdin), который предоставляется в качестве входных данных для Mapper, а выход (stdout) Mapper предоставляется в качестве входных данных для Reducer; наконец, Reducer записывает вывод в каталог HDFS.
Командная строка с задачами mаp и reduce, реализованная как R-скрипт, будет выглядеть следующим образом.
$ $ {HADOOP_HOME} / bin / Hadoop jar
$ {HADOOP_HOME} / contrib / streaming / *. Jar
-inputformat org.apache.hadoop.mapred.TextInputFormat
-ввод input_data.txt
-выход выход
-mapper /home/tst/src/map.R
-reducer /home/tst/src/reduce.R
-файл /home/ts/src/map.R
-файл /home/tst/src/reduce.RОсновным преимуществом потоковой передачи Hadoop является возможность выполнения как Java, так и запрограммированных заданий MapReduce, не основанных на Java, в кластерах Hadoop. Потоковая передача Hadoop эффективно поддерживает различные языки, такие как Perl, Python, PHP, R и C ++, а также другие языки программирования. Различный компоненты задания MapReduce потоковой передачи Hadoop.