Hadoop - Reducer в Map-Reduce
Map-Reduce - это модель программирования, которая в основном разделена на две фазы, то есть фазу карты и фазу сокращения. Он предназначен для параллельной обработки данных, которые разделяются на различных машинах (узлах). Javapрограммы Hadoop состоят из класса Mapper и класса Reducer, а также класса драйвера. Reducer - это вторая часть модели программирования Map-Reduce. Mapper производит вывод в виде пар ключ-значение, который работает как ввод для Reducer.
Но перед отправкой этих промежуточных пар ключ-значение непосредственно в редуктор будет выполнен некоторый процесс, который перемешает и отсортирует пары ключ-значение в соответствии с его значениями ключа, что означает, что значение ключа является основным решающим фактором для сортировки. Вывод, сгенерированный редуктором, будет окончательным выводом, который затем сохраняется в HDFS (распределенная файловая система Hadoop). Редуктор в основном выполняет некоторые вычислительные операции, такие как сложение, фильтрация и агрегация. По умолчанию количество редукторов, используемых для обработки вывода Mapper, равно 1, что является настраиваемым и может быть изменено пользователем в соответствии с требованиями.
Давайте разберемся с Reducer в Map-Reduce:
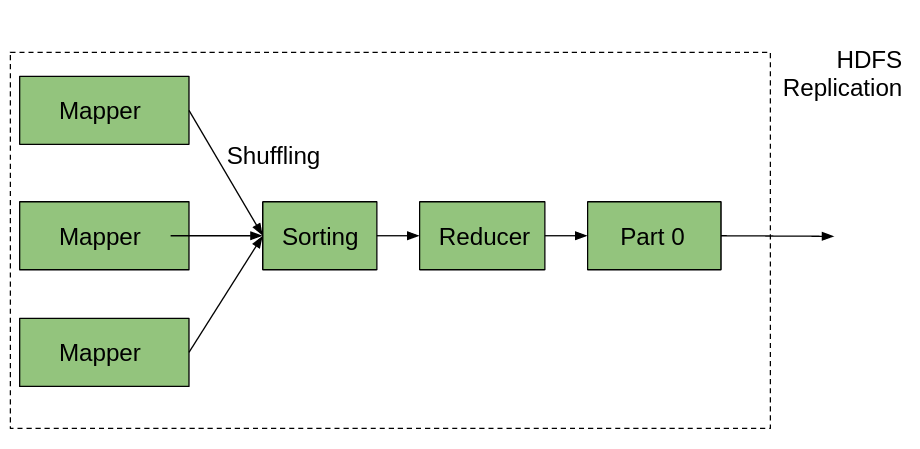
Здесь, на изображении выше, мы можем заметить, что существует несколько Mapper, которые генерируют пары ключ-значение в качестве вывода. Выходные данные каждого сопоставителя отправляются на сортировщик, который сортирует пары ключ-значение в соответствии со своим значением ключа. Перестановка также происходит во время процесса сортировки, и вывод будет отправлен в часть редуктора, и будет произведен окончательный результат.
Давайте рассмотрим пример, чтобы понять, как работает Reducer . Предположим, у нас есть данные обо всех факультетах колледжа, хранящиеся в файле CSV. Если мы хотим узнать сумму зарплат преподавателей по их кафедрам, то мы можем сделать их кафедру. титул как ключ и зарплата как ценность . Редуктор выполнит операцию суммирования этого набора данных и выдаст желаемый результат.
Количество редукторов в задаче Map-Reduce также влияет на следующие функции:
- Увеличиваются накладные расходы фреймворка.
- Стоимость отказа Снижается
- Увеличьте балансировку нагрузки.
Нам также нужно помнить, что между редукторами и ключами всегда будет однозначное соответствие. После завершения всего процесса Reducer выходные данные сохраняются в файле части (имя по умолчанию) в HDFS (распределенная файловая система Hadoop). В выходном каталоге HDFS Map-Reduce всегда создает файл _SUCCESS и файл part-r-00000 . Количество файлов деталей зависит от количества редукторов, если у нас 5 редукторов, тогда номер файла детали будет от part-r-00000 до part-r-00004. По умолчанию эти файлы имеют имя типа part-a-bbbbb . Его можно изменить вручную, все, что нам нужно сделать, это изменить указанное ниже свойство в коде нашего драйвера Map-Reduce.
// Здесь мы меняем имя выходного файла с part-r-00000 на GeeksForGeeks
job.getConfiguration (). set ("mapreduce.output.basename", "GeeksForGeeks")
Редуктор Map-Reduce состоит в основном из 3 процессов / фаз:
- Shuffle: Shuffle помогает переносить данные из Mapper в требуемый Reducer. С помощью HTTP структура требует соответствующего разделения вывода во всех Mappers.
- Сортировка: на этом этапе вывод сопоставителя, который фактически представляет собой пары ключ-значение, будет отсортирован на основе его значения ключа.
- Уменьшить: после того, как перетасовка и сортировка будут выполнены, Редуктор объединит полученный результат и выполнит операцию вычисления в соответствии с требованиями. Свойство OutputCollector.collect () используется для записи вывода в HDFS. Помните, что вывод редуктора не будет отсортирован.
Примечание. Перемешивание и сортировка выполняются параллельно.
Установка количества редукторов в Map-Reduce:
- С помощью командной строки: при выполнении нашей программы Map-Reduce мы можем вручную изменить количество Reducer с помощью контроллера mapred.reduce.tasks .
- С экземпляром JobConf: в нашем классе драйвера мы можем указать количество редукторов, используя экземпляр job.setNumReduceTasks (int) .
Например job.setNumReduceTasks (2), здесь у нас 2 редуктора. мы также можем сделать редукторы равными 0, если нам нужно только задание карты.
// В идеале количество редукторов в Map-Reduce должно быть установлено на: 0,95 или 1,75, умноженное на (<количество узлов> * <количество максимальных контейнеров на узел>)