Hadoop MapReduce - поток данных
Map-Reduce - это среда обработки, используемая для обработки данных на большом количестве машин. Hadoop использует Map-Reduce для обработки данных, распределенных в кластере Hadoop. Map-Reduce не похож на другие обычные среды обработки, такие как Hibernate, JDK, .NET и т. Д. Все эти предыдущие структуры предназначены для использования с традиционной системой, в которой данные хранятся в одном месте, например, сетевая файловая система, база данных Oracle. и т.д. Но когда мы обрабатываем большие данные, они размещаются на нескольких обычных машинах с помощью HDFS.
Поэтому, когда данные хранятся на нескольких узлах, нам нужна среда обработки, в которой она может копировать программу в место, где присутствуют данные. Это означает, что она копирует программу на все машины, на которых присутствуют данные. Здесь на сцену выходит Map-Reduce для обработки данных в Hadoop в распределенной системе. У Hadoop есть серьезный недостаток сетевого трафика между коммутаторами, который связан с огромным объемом данных. Map-Reduce имеет функцию Data-Locality . Локальность данных - это возможность приблизить вычисления к фактическому расположению данных на машинах.
Поскольку Hadoop предназначен для работы на стандартном оборудовании, он использует Map-Reduce, поскольку это широко приемлемо, что обеспечивает простой способ обработки данных на нескольких узлах. Map-Reduce - не единственная платформа для параллельной обработки. В настоящее время Spark также является популярным фреймворком, используемым для распределенных вычислений, например Map-Reduce. У нас также есть HAMA, тезисы MPI - это еще и другая структура распределенной обработки.
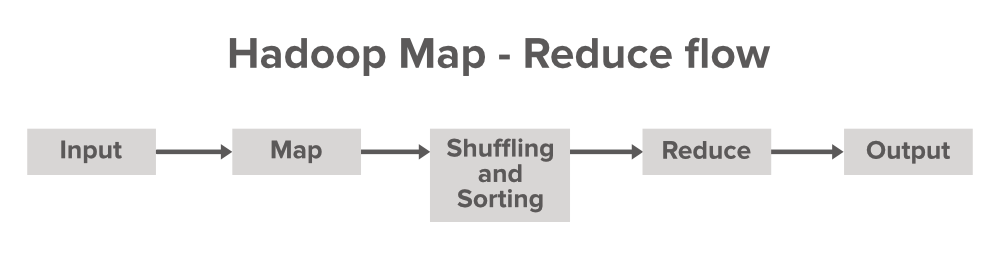
Давайте разберемся с потоком данных в Map-Reduce
Map Reduce - это терминология, которая используется в Map Phase и Reducer Phase . Карта используется для преобразования, а редуктор - для операции агрегирования. Терминология для Map и Reduce заимствована из некоторых функциональных языков программирования, таких как Lisp, Scala и т. Д. Программа обработки Map-Reduce состоит из трех основных компонентов, а именно: нашего кода драйвера , Mapper (для преобразования) и Reducer (для агрегирования).
Рассмотрим пример, в котором у вас есть файл размером 10 ТБ для обработки в Hadoop. 10 ТБ данных сначала распределяются между несколькими узлами Hadoop с HDFS. Теперь нам нужно обработать его, чтобы получить фреймворк Map-Reduce. Итак, для обработки этих данных с помощью Map-Reduce у нас есть код драйвера, который называется Job . Если мы используем язык программирования Java для обработки данных в HDFS, нам нужно инициировать этот класс Driver с помощью объекта Job. Предположим, у вас есть автомобиль, который является вашей структурой, а кнопка запуска, используемая для запуска автомобиля, похожа на этот код драйвера в структуре Map-Reduce. Нам нужно запустить код драйвера, чтобы использовать преимущества этой Map-Reduce Framework.
Эта структура также предоставляет классы Mapper и Reducer , которые предопределены и изменены разработчиками в соответствии с требованиями организации.
Краткая работа картографа
Mapper - это начальная строка кода, которая изначально взаимодействует с входным набором данных. Предположим, если у нас есть 100 блоков данных из набора данных, который мы анализируем, тогда в этом случае будет 100 программ или процессов Mapper, которые работают параллельно на машинах (узлах) и производят собственный вывод, известный как промежуточный вывод, который затем хранится на локальном диске, а не на HDFS. Выходные данные сопоставителя действуют как входные данные для Reducer, который выполняет некоторую операцию сортировки и агрегирования данных и выдает окончательный результат.
Краткая работа редуктора
Reducer - это вторая часть модели программирования Map-Reduce. Mapper производит вывод в виде пар ключ-значение, который работает как ввод для Reducer. Но перед отправкой этих промежуточных пар ключ-значение непосредственно в редуктор будет выполнен некоторый процесс, который перемешивает и сортирует пары ключ-значение в соответствии с его значениями ключей. Вывод, сгенерированный редуктором, будет окончательным выводом, который затем сохраняется в HDFS (распределенная файловая система Hadoop). Редуктор в основном выполняет некоторые вычислительные операции, такие как сложение, фильтрация и агрегация.
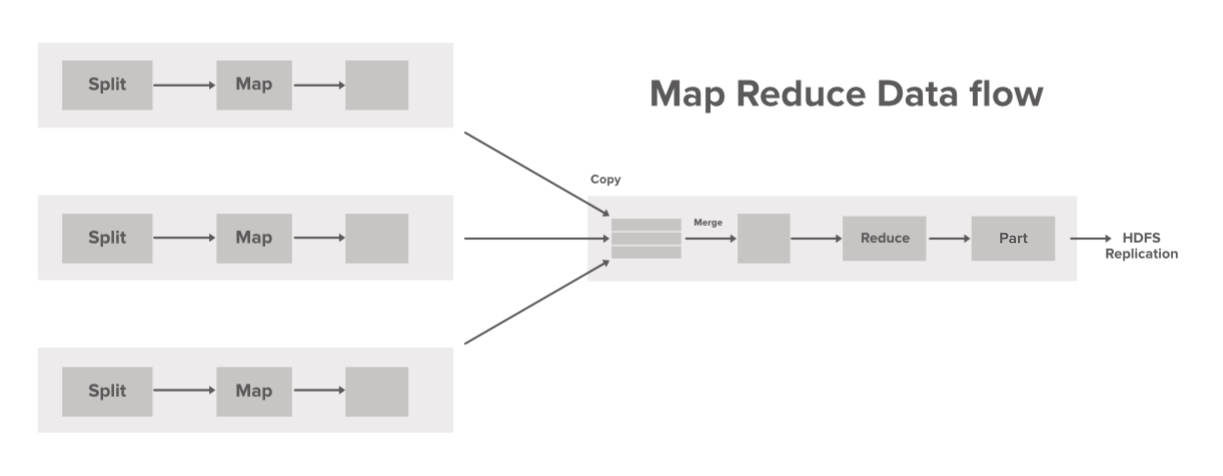
Шаги потока данных:
- Одновременно обрабатывается разделение одного входа. Mapper переопределяется разработчиком в соответствии с бизнес-логикой, и этот Mapper запускается параллельно на всех машинах в нашем кластере.
- Промежуточный вывод, сгенерированный Mapper, сохраняется на локальном диске и перетасовывается редуктору для сокращения задачи.
- Как только Mapper завершает свою задачу, выходные данные сортируются, объединяются и передаются в Reducer.
- Reducer выполняет некоторые задачи по сокращению, такие как агрегирование и другие композиционные операции, а окончательный результат сохраняется в HDFS в файле part-r-00000 (созданном по умолчанию).