Hadoop - HDFS (распределенная файловая система Hadoop)
Прежде чем перейти к изучению HDFS (распределенной файловой системы Hadoop), мы должны знать, что на самом деле представляет собой файловая система. Файловая система - это своего рода структура данных или метод, который мы используем в операционной системе для управления файлами на диске. Это означает, что он позволяет пользователю сохранять и извлекать данные с локального диска.
Примером файловой системы Windows является NTFS (файловая система новой технологии) и FAT32 (таблица размещения файлов 32). FAT32 используется в некоторых старых версиях Windows, но может использоваться во всех версиях Windows XP . Подобно Windows, у нас есть файловая система ext3, ext4 для ОС Linux.
Что такое DFS?
DFS означает распределенную файловую систему, это концепция хранения файла на нескольких узлах распределенным образом. DFS фактически предоставляет абстракцию для одной большой системы, объем хранилища которой равен сумме хранилищ других узлов в кластере.
Давайте разберемся в этом на примере. Предположим, у вас есть DFS, состоящая из 4 разных машин, каждая размером 10 ТБ, в этом случае вы можете хранить, скажем, 30 ТБ в этой DFS, поскольку она предоставляет вам комбинированную машину размером 40 ТБ. Данные размером 30 ТБ распределяются между этими узлами в виде блоков.
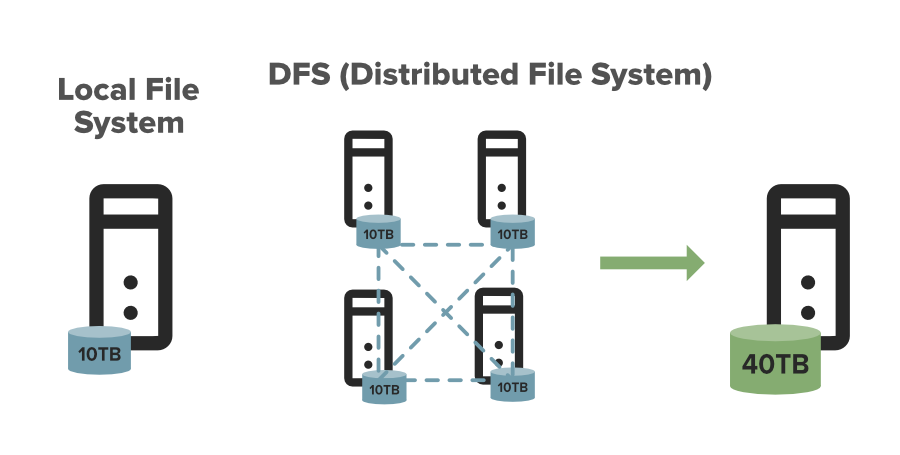
Зачем нам DFS?
Вы можете подумать, что мы можем хранить файл размером 30 ТБ в одной системе, тогда зачем нам эта DFS. Это связано с тем, что емкость диска в системе может увеличиваться только до некоторой степени. Если каким-то образом вы управляете данными в одной системе, вы столкнетесь с проблемой обработки, обработка больших наборов данных на одной машине неэффективна.
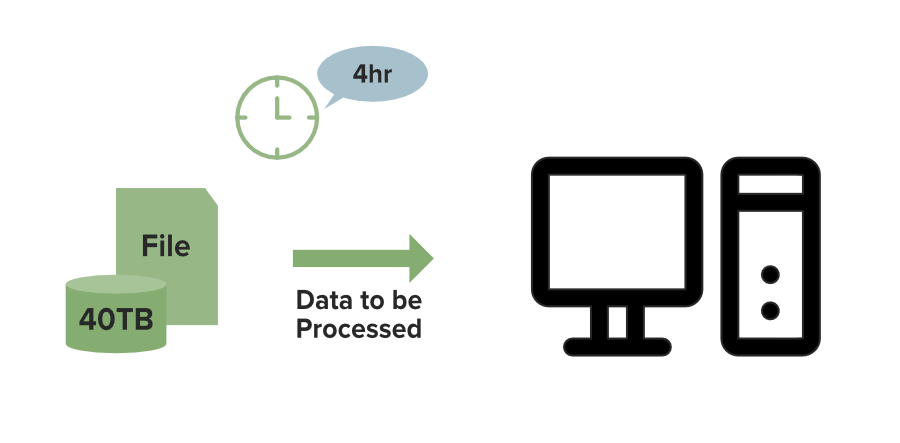
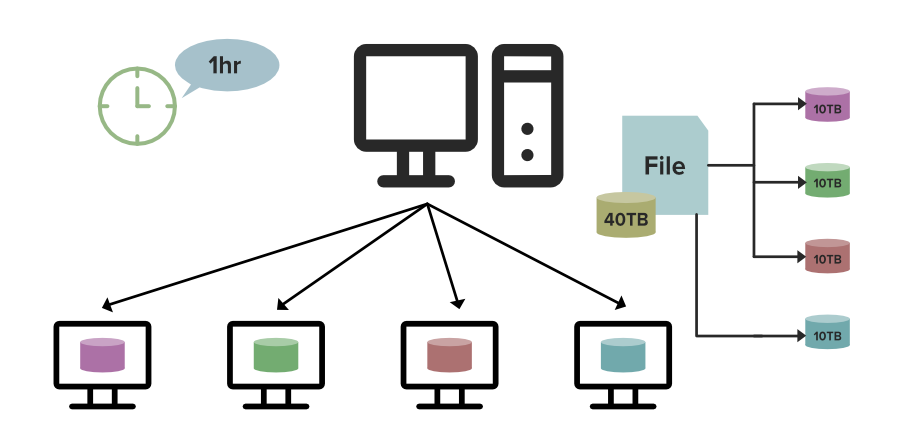
Давайте разберемся в этом на примере. Предположим, у вас есть файл размером 40 ТБ для обработки. Предположим, что на одной машине это займет 4 часа, но что делать, если вы используете DFS (распределенную файловую систему). В этом случае, как вы можете видеть на изображении ниже, файл размером 40 ТБ распределяется между 4 узлами в кластере, каждый узел хранит 10 ТБ файла. Поскольку все эти узлы работают одновременно, для их полной обработки потребуется всего 1 час, что является самым быстрым, поэтому нам нужна DFS.
Обработка локальной файловой системы:
Обработка распределенной файловой системы:
Обзор - HDFS
Теперь мы думаем, что вы познакомились с термином файловая система, поэтому давайте начнем с HDFS. HDFS (распределенная файловая система Hadoop) используется для разрешения хранилища в кластере Hadoop. Он в основном предназначен для работы с обычными аппаратными устройствами (недорогими устройствами), работая над распределенной файловой системой. HDFS спроектирована таким образом, что больше полагается на хранение данных в большом фрагменте блоков, а не на хранение небольших блоков данных. HDFS в Hadoop обеспечивает отказоустойчивость и высокую доступность для уровня хранения и других устройств, присутствующих в этом кластере Hadoop.
HDFS способна обрабатывать данные большего размера с высокой скоростью передачи данных, а разнообразие делает работу Hadoop более эффективной и надежной благодаря легкому доступу ко всем ее компонентам. HDFS хранит данные в виде блока, где размер каждого блока данных составляет 128 МБ, что позволяет настраивать его, что означает, что вы можете изменить его в соответствии с вашими требованиями в файле hdfs-site.xml в каталоге Hadoop.
Некоторые важные особенности HDFS (распределенная файловая система Hadoop)
- Легко получить доступ к файлам, хранящимся в HDFS.
- HDFS также обеспечивает высокую доступность и отказоустойчивость.
- Обеспечивает масштабируемость для масштабирования или масштабирования узлов в соответствии с нашими требованиями.
- Данные хранятся распределенным образом, то есть за хранение данных отвечают различные датаноды.
- HDFS обеспечивает репликацию, из-за которой не боятся потери данных.
- HDFS обеспечивает высокую надежность, поскольку может хранить данные в большом диапазоне петабайт .
- HDFS имеет встроенные серверы в узле имени и узле данных, что помогает им легко извлекать информацию о кластере.
- Обеспечивает высокую пропускную способность.
Демон хранилища HDFS
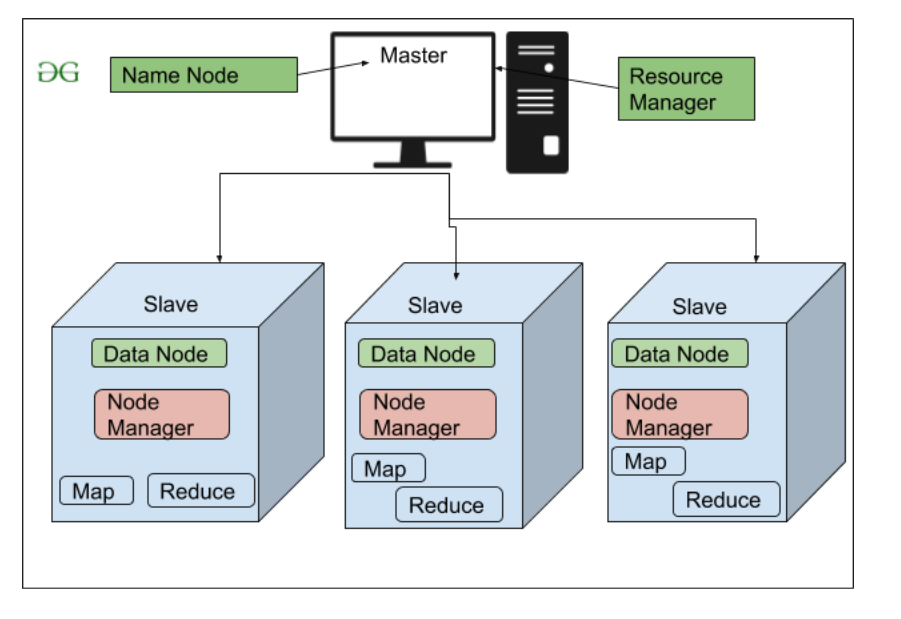
Как мы все знаем, Hadoop работает по алгоритму MapReduce, который представляет собой архитектуру главный-подчиненный, у HDFS есть NameNode и DataNode, которые работают по аналогичной схеме.
1. NameNode (главный)
2. DataNode (ведомый)
1. NameNode: NameNode работает как мастер в кластере Hadoop, который управляет Datanode (подчиненными). Namenode в основном используется для хранения метаданных, то есть ничего, кроме данных о данных. Метаданные могут быть журналами транзакций, которые отслеживают активность пользователя в кластере Hadoop.
Метаданные также могут быть именем файла, размером и информацией о местоположении (номер блока, идентификаторы блоков) Datanode, которые Namenode хранит, чтобы найти ближайший узел данных для более быстрой связи. Namenode инструктирует DataNodes о таких операциях, как удаление, создание, репликация и т. Д.
Поскольку наш NameNode работает как главный, он должен иметь высокую оперативную память или вычислительную мощность, чтобы поддерживать или направлять все подчиненные устройства в кластере Hadoop. Namenode принимает контрольные сигналы и блокирует отчеты от всех ведомых устройств, то есть DataNodes.
2. DataNode: DataNodes работает как Slave DataNodes в основном используются для хранения данных в кластере Hadoop, количество DataNodes может быть от 1 до 500 или даже больше, чем большее количество DataNode имеет ваш кластер Hadoop, может быть больше данных. храниться. поэтому рекомендуется, чтобы DataNode имел высокую емкость для хранения большого количества файловых блоков. Datanode выполняет такие операции, как создание, удаление и т. Д., В соответствии с инструкциями, предоставленными NameNode.
Цели и предположения HDFS
1. Отказ системы. Поскольку кластер Hadoop состоит из множества узлов с обычным оборудованием, возможен сбой узла, поэтому основная цель HDFS - выявить эту проблему сбоя и восстановить ее.
2. Поддержка большого набора данных. Поскольку HDFS обрабатывает файлы размером от ГБ до ПБ, HDFS должна быть достаточно крутой, чтобы обрабатывать эти очень большие наборы данных в одном кластере.
3. Перемещение данных обходится дороже, чем перемещение вычислений: если вычислительная операция выполняется рядом с местом, где присутствуют данные, то она выполняется намного быстрее, и общая пропускная способность системы может быть увеличена вместе с минимизацией перегрузки сети, что является хорошим предположение.
4. Переносимость на различных платформах: HDFS обладает переносимостью, которая позволяет переключаться между различными аппаратными и программными платформами.
5. Простая модель когерентности. Распределенной файловой системе Hadoop требуется модель, позволяющая писать один раз для чтения и иметь большой доступ к файлам. Записанный и закрытый файл не должен изменяться, могут быть добавлены только данные. Это предположение помогает нам минимизировать проблему согласованности данных. MapReduce отлично подходит для такой файловой модели.