Hadoop - Архитектура
Как мы все знаем, Hadoop - это среда, написанная на Java, которая использует большой кластер стандартного оборудования для обслуживания и хранения данных большого размера. Hadoop работает над алгоритмом программирования MapReduce, представленным Google. Сегодня многие крупные компании используют Hadoop в своих организациях для работы с большими данными, например. Facebook, Yahoo, Netflix, eBay и т. Д. Архитектура Hadoop в основном состоит из 4 компонентов.
- Уменьшение карты
- HDFS (распределенная файловая система Hadoop)
- ПРЯЖА (еще одна структура ресурсов)
- Common Utilities или Hadoop Common
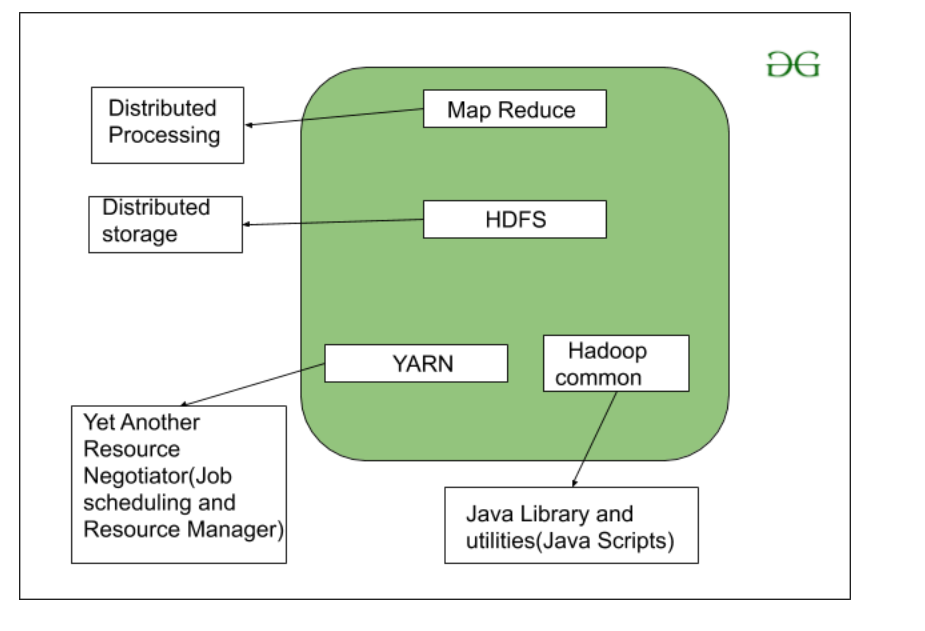
Давайте подробно разберемся в роли каждого из этих компонентов.
1. MapReduce
MapReduce не что иное, как алгоритм или структура данных, основанная на фреймворке YARN. Основная особенность MapReduce - параллельное выполнение распределенной обработки в кластере Hadoop, благодаря чему Hadoop работает так быстро. Когда вы имеете дело с большими данными, последовательная обработка больше не нужна. MapReduce имеет в основном 2 задачи, которые разделены по этапам:
- Задача карты
- Уменьшить задачу
На первом этапе используется Map, а на следующем этапе - Reduce .
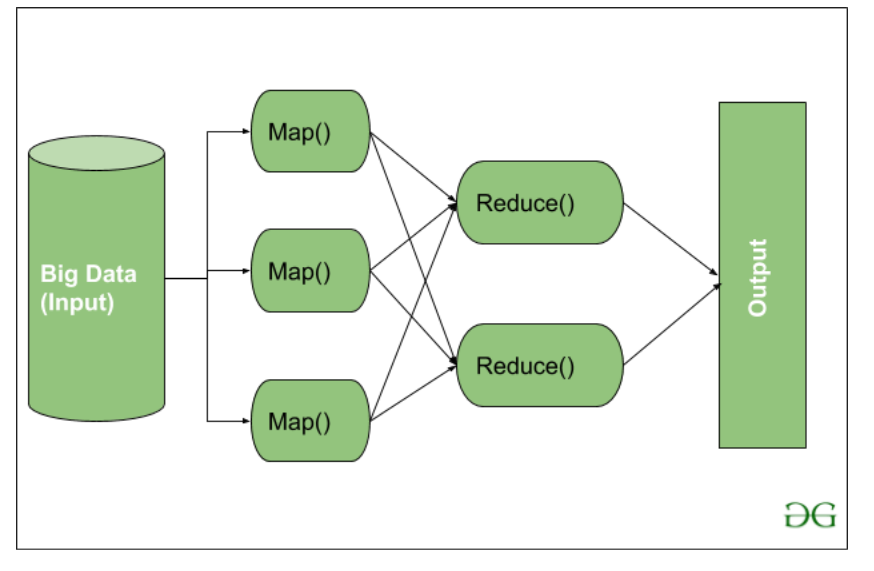
Здесь мы видим, что входные данные предоставляются функции Map (), затем их выходные данные используются в качестве входных данных для функции Reduce, и после этого мы получаем наш окончательный результат. Давайте разберемся, что делают эти Map () и Reduce ().
Как мы видим, теперь для Map () предоставляется Input, поскольку мы используем большие данные. Вход - это набор данных. Здесь функция Map () разбивает эти блоки данных на кортежи, которые представляют собой не что иное, как пару "ключ-значение". Эти пары "ключ-значение" теперь отправляются в качестве входных данных в функцию Reduce (). Затем функция Reduce () объединяет эти разбитые кортежи или пару ключ-значение на основе значения ключа и формирует набор кортежей и выполняет некоторые операции, такие как сортировка, задание типа суммирования и т. Д., Которые затем отправляются в конечный узел вывода. Наконец, результат получен.
Обработка данных всегда выполняется в Reducer в зависимости от бизнес-требований данной отрасли. Вот как сначала используются сначала Map (), а затем Reduce.
Давайте подробно разберемся с Map Taks и Reduce Task.
Задача карты:
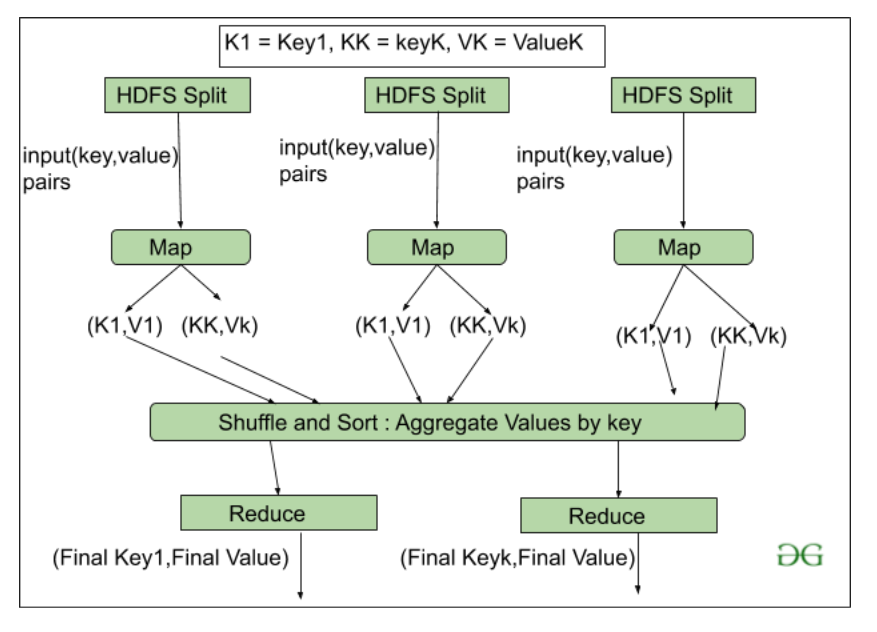
- RecordReader Цель recoredreader - побить рекорды. Он отвечает за предоставление пар ключ-значение в функции Map (). Ключ на самом деле - это его местонахождение, а ценность - это данные, связанные с ним.
- Карта: карта - это не что иное, как определяемая пользователем функция, работа которой заключается в обработке кортежей, полученных от программы чтения записей. Функция Map () либо не генерирует пары ключ-значение, либо генерирует несколько пар этих кортежей.
- Объединитель: Объединитель используется для группировки данных в рабочем процессе карты. Он похож на локальный редуктор. Промежуточные пары "ключ-значение", которые генерируются на карте, комбинируются с помощью этого комбайнера. Использование комбайнера не обязательно, так как это необязательно.
- Partitionar: Partitional отвечает за выборку пар ключ-значение, сгенерированных на этапах сопоставления. Разделитель генерирует сегменты, соответствующие каждому редуктору. Этот раздел также получает хэш-код каждого ключа. Затем разделитель выполняет модуль (Hashcode) с количеством редукторов ( key.hashcode ()% (количество редукторов)).
Уменьшить задачу
- Перемешивание и сортировка: задача Reducer начинается с этого шага, процесс, в котором Mapper генерирует промежуточное значение ключа и передает их в задачу Reducer, известен как Shuffling . Используя процесс Shuffling, система может сортировать данные, используя их значение ключа.
После выполнения некоторых задач сопоставления начинается перемешивание, поэтому это более быстрый процесс и не дожидается завершения задачи, выполняемой сопоставителем.
- Reduce: основная функция или задача Reduce - собрать кортеж, сгенерированный из Map, а затем выполнить некоторый процесс сортировки и агрегирования для этих значений ключа в зависимости от его ключевого элемента.
- OutputFormat: после выполнения всех операций пары ключ-значение записываются в файл с помощью средства записи, каждая запись в новой строке, а ключ и значение - через пробел.
2. HDFS
HDFS (распределенная файловая система Hadoop) используется для разрешения хранилища в кластере Hadoop. Он в основном предназначен для работы на обычных аппаратных устройствах (недорогих устройствах), работающих над распределенной файловой системой. HDFS спроектирована таким образом, что больше полагается на хранение данных в большом фрагменте блоков, а не на хранение небольших блоков данных.
HDFS в Hadoop обеспечивает отказоустойчивость и высокую доступность для уровня хранения и других устройств, присутствующих в этом кластере Hadoop. Узлы хранения данных в HDFS.
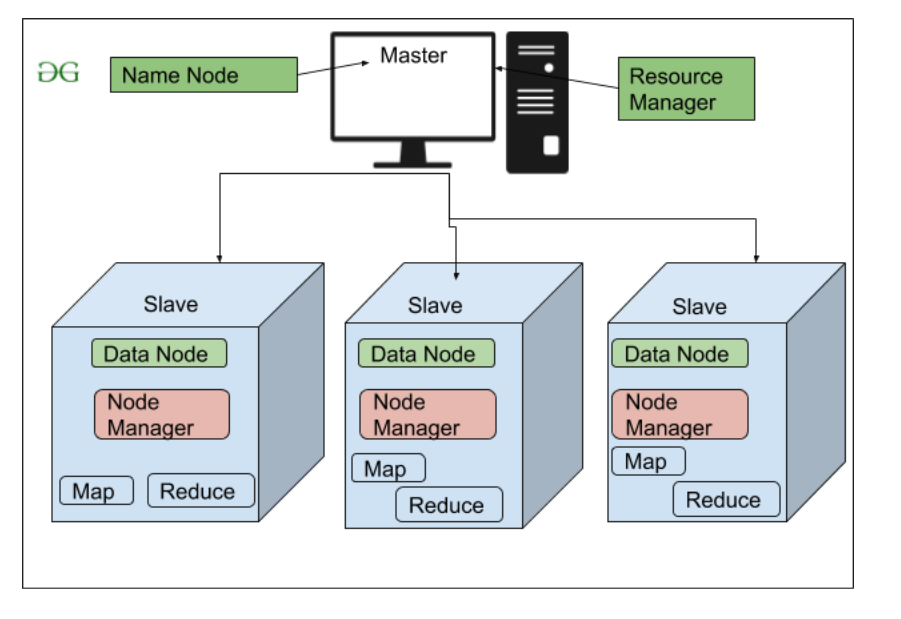
- NameNode (Мастер)
- DataNode (подчиненный)
NameNode: NameNode работает как мастер в кластере Hadoop, который управляет Datanode (подчиненными). Namenode в основном используется для хранения метаданных, то есть данных о данных. Метаданные могут быть журналами транзакций, которые отслеживают активность пользователя в кластере Hadoop.
Метаданные также могут быть именем файла, размером и информацией о местоположении (номер блока, идентификаторы блоков) Datanode, которые Namenode хранит, чтобы найти ближайший узел данных для более быстрой связи. Namenode инструктирует DataNodes о таких операциях, как удаление, создание, репликация и т. Д.
DataNode: DataNodes работает как Slave DataNodes в основном используются для хранения данных в кластере Hadoop, количество DataNodes может быть от 1 до 500 или даже больше. Чем больше количество DataNode, тем больше данных в кластере Hadoop. Поэтому рекомендуется, чтобы DataNode имел высокую емкость для хранения большого количества файловых блоков.
Архитектура высокого уровня Hadoop
Файловый блок в HDFS: данные в HDFS всегда хранятся в виде блоков. Таким образом, единый блок данных делится на несколько блоков размером 128 МБ, который используется по умолчанию, и вы также можете изменить его вручную.
Давайте разберемся с этой концепцией разбивки файла на блоки на примере. Предположим, вы загрузили файл размером 400 МБ в HDFS, тогда происходит то, что этот файл разделен на блоки размером 128 МБ + 128 МБ + 128 МБ + 16 МБ = 400 МБ. Означает, что создается 4 блока по 128 МБ каждый, кроме последнего. Hadoop не знает или не заботится о том, какие данные хранятся в этих блоках, поэтому он рассматривает окончательные блоки файла как частичную запись, поскольку не имеет об этом никакого представления. В файловой системе Linux размер файлового блока составляет около 4 КБ, что намного меньше размера файловых блоков по умолчанию в файловой системе Hadoop. Как мы все знаем, Hadoop в основном сконфигурирован для хранения данных большого размера в петабайтах, это то, что отличает файловую систему Hadoop от других файловых систем, поскольку ее можно масштабировать, в настоящее время в Hadoop рассматриваются файловые блоки размером от 128 до 256 МБ.
Репликация в HDFS Репликация обеспечивает доступность данных. Репликация - это создание копии чего-либо, и количество раз, когда вы копируете эту конкретную вещь, можно выразить как фактор репликации. Как мы видели в блоках файлов, HDFS хранит данные в форме различных блоков, в то время как Hadoop также настроен на создание копий этих блоков файлов.
По умолчанию коэффициент репликации для Hadoop установлен на 3, который можно настроить, это означает, что вы можете изменить его вручную в соответствии с вашими требованиями, как в приведенном выше примере, мы создали 4 файловых блока, что означает, что создается 3 реплики или копия каждого файлового блока, что означает всего для резервного копирования сделано 4 × 3 = 12 блоков.
Это связано с тем, что для работы Hadoop мы используем обычное оборудование (недорогое системное оборудование), которое может выйти из строя в любой момент. Мы не используем суперкомпьютер для нашей установки Hadoop. Вот почему нам нужна такая функция в HDFS, которая может делать копии этих файловых блоков для целей резервного копирования, это известно как отказоустойчивость.
Нам также нужно заметить, что после создания такого количества реплик наших файловых блоков мы тратим впустую так много нашего хранилища, но для крупной торговой организации данные очень важны, чем хранилище, поэтому никому нет дела до этого дополнительного хранилища. Вы можете настроить коэффициент репликации в файле hdfs-site.xml .
Осведомленность о стойке Стойка - это не что иное, как физическая совокупность узлов в нашем кластере Hadoop (может быть, от 30 до 40). Большой кластер Hadoop состоит из множества стоек. с помощью этой информации о стойках Namenode выбирает ближайший Datanode для достижения максимальной производительности при выполнении чтения / записи информации, что снижает сетевой трафик.
Архитектура HDFS

3. ПРЯЖА (еще один переговорщик ресурсов)
YARN - это фреймворк, на котором работает MapReduce. YARN выполняет 2 операции: планирование заданий и управление ресурсами. Назначение расписания заданий - разделить большую задачу на небольшие задания, чтобы каждое задание можно было назначить различным ведомым устройствам в кластере Hadoop, а обработку можно было максимизировать. Планировщик заданий также отслеживает, какое задание важно, какое задание имеет больший приоритет, зависимости между заданиями и всю другую информацию, такую как время задания и т. Д. А использование диспетчера ресурсов заключается в управлении всеми ресурсами, доступными для выполнения. кластер Hadoop.
Особенности ПРЯЖИ
- Мульти аренды
- Масштабируемость
- Использование кластера
- Совместимость
4. Общие или общие служебные программы Hadoop.
Общие или Общие утилиты Hadoop - это не что иное, как наша библиотека java и файлы java, или мы можем сказать сценарии java, которые нам нужны для всех других компонентов, присутствующих в кластере Hadoop. эти утилиты используются HDFS, YARN и MapReduce для запуска кластера. Hadoop Common проверяет, что аппаратный сбой в кластере Hadoop является обычным явлением, поэтому его необходимо автоматически решать с помощью программного обеспечения с помощью Hadoop Framework.