Генеративная состязательная сеть (GAN)
Генеративные состязательные сети (GAN) - это мощный класс нейронных сетей, которые используются для обучения без учителя. Он был разработан и представлен Яном Дж. Гудфеллоу в 2014 году. Сети GAN в основном состоят из системы двух конкурирующих моделей нейронных сетей, которые конкурируют друг с другом и могут анализировать, фиксировать и копировать вариации в наборе данных.
Почему вообще были разработаны сети GAN?
Было замечено, что большинство распространенных нейронных сетей можно легко обмануть, ошибочно классифицируя вещи, добавив лишь небольшой шум в исходные данные. Удивительно, но модель после добавления шума имеет большую уверенность в неверном прогнозе, чем при правильном прогнозе. Причина такого врага в том, что большинство моделей машинного обучения обучаются на ограниченном объеме данных, что является огромным недостатком, поскольку они подвержены переобучению. Кроме того, отображение между входом и выходом почти линейное. Хотя может показаться, что границы разделения между различными классами линейны, но на самом деле они состоят из линейностей, и даже небольшое изменение точки в пространстве признаков может привести к неправильной классификации данных.
Как работает GAN?
Генеративные состязательные сети (GAN) можно разделить на три части:
- Генеративный: чтобы изучить генеративную модель, которая описывает, как данные генерируются в терминах вероятностной модели.
- Состязательный: обучение модели проводится в условиях состязательности.
- Сети: используйте глубокие нейронные сети в качестве алгоритмов искусственного интеллекта (ИИ) для целей обучения.
В GAN есть генератор и дискриминатор . Генератор генерирует поддельные образцы данных (будь то изображение, звук и т. Д.) И пытается обмануть Дискриминатор. Дискриминатор, с другой стороны, пытается отличить настоящие образцы от поддельных. Генератор и Дискриминатор являются нейронными сетями, и оба они конкурируют друг с другом на этапе обучения. Эти шаги повторяются несколько раз, и при этом генератор и дискриминатор становятся все лучше и лучше в своих соответствующих задачах после каждого повторения. Работу можно визуализировать с помощью схемы, представленной ниже: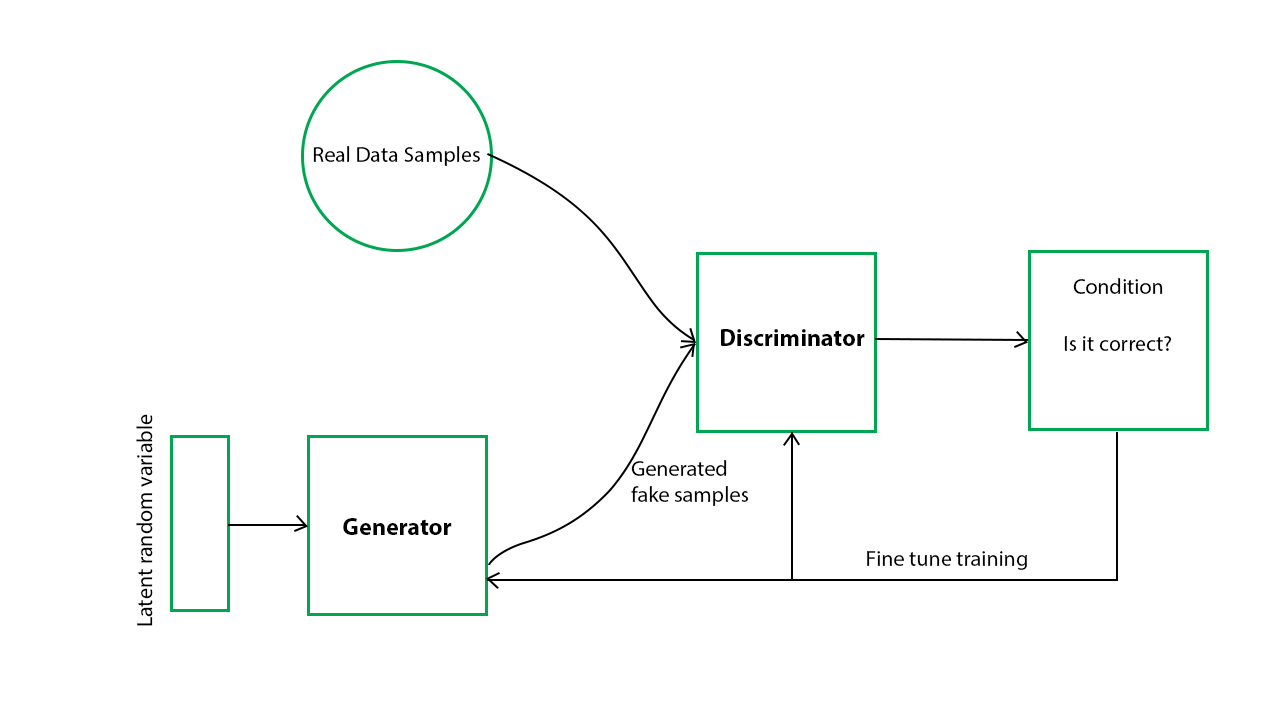
Здесь генеративная модель фиксирует распределение данных и обучается таким образом, что пытается максимизировать вероятность ошибки Дискриминатора. Дискриминатор, с другой стороны, основан на модели, которая оценивает вероятность того, что полученная им выборка получена из обучающих данных, а не из генератора.
GAN сформулированы как минимаксная игра, в которой Дискриминатор пытается минимизировать свою награду V (D, G), а Генератор пытается минимизировать вознаграждение Дискриминатора или, другими словами, максимизировать свои потери. Математически это можно описать следующей формулой:
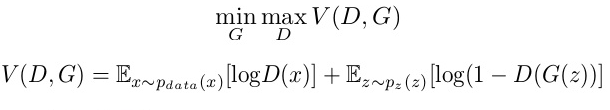
где,
G = Генератор
D = Дискриминатор
Pdata (x) = распределение реальных данных
P (z) = распределение генератора
x = образец из Pdata (x)
z = образец из P (z)
D (x) = Дискриминаторная сеть
G (z) = сеть генератора
Итак, в основном обучение GAN состоит из двух частей:
- Часть 1: Дискриминатор обучается, пока Генератор не используется. На этом этапе сеть распространяется только в прямом направлении, а обратное распространение не выполняется. Дискриминатор обучается на реальных данных за n эпох и проверяет, может ли он правильно предсказать их как реальные. Кроме того, на этом этапе Дискриминатор также обучается на поддельных данных, сгенерированных Генератором, и проверяет, сможет ли он правильно предсказать их как поддельные.
- Часть 2: Генератор обучается, пока дискриминатор бездействует. После того, как Дискриминатор обучен сгенерированными фальшивыми данными Генератора, мы можем получить его прогнозы и использовать результаты для обучения Генератора и улучшить предыдущее состояние, чтобы попытаться обмануть Дискриминатор.
Вышеупомянутый метод повторяется в течение нескольких эпох, а затем вручную проверяет поддельные данные, если они кажутся подлинными. Если это кажется приемлемым, то обучение прекращается, в противном случае его можно продолжить еще несколько эпох.
Различные типы GAN:
В настоящее время GAN являются очень активной темой исследований, и существует много различных типов реализации GAN. Некоторые из наиболее важных из них, которые активно используются в настоящее время, описаны ниже:- Vanilla GAN: это простейший тип GAN. Здесь Генератор и Дискриминатор - простые многослойные перцептроны. В ванильном GAN алгоритм действительно прост, он пытается оптимизировать математическое уравнение, используя стохастический градиентный спуск.
- Условный GAN (CGAN): CGAN можно описать как метод глубокого обучения, в котором используются некоторые условные параметры. В CGAN к генератору добавляется дополнительный параметр «y» для генерации соответствующих данных. Метки также помещаются на вход дискриминатора, чтобы дискриминатор помог отличить реальные данные от поддельных сгенерированных данных.
- Глубокая сверточная GAN (DCGAN): DCGAN - одна из самых популярных и наиболее успешных реализаций GAN. Он состоит из ConvNets вместо многослойных перцептронов. ConvNets реализованы без максимального объединения, которое фактически заменено сверточным шагом. Кроме того, слои не полностью связаны.
- Пирамида Лапласа GAN (LAPGAN): пирамида Лапласа - это линейное обратимое представление изображения, состоящее из набора полосовых изображений, разнесенных на октаву друг от друга, плюс низкочастотный остаток. В этом подходе используется несколько сетей генераторов и дискриминаторов, а также разные уровни пирамиды Лапласа. Этот подход используется в основном потому, что он дает очень качественные изображения. Изображение сначала подвергается понижающей дискретизации на каждом слое пирамиды, а затем оно снова масштабируется на каждом слое при обратном проходе, когда изображение приобретает некоторый шум от условной GAN на этих уровнях, пока не достигнет своего исходного размера.
- GAN со сверхвысоким разрешением (SRGAN): SRGAN, как следует из названия, представляет собой способ разработки GAN, в котором глубокая нейронная сеть используется вместе с враждебной сетью для создания изображений с более высоким разрешением. Этот тип GAN особенно полезен для оптимального масштабирования собственных изображений с низким разрешением, чтобы улучшить их детали, минимизируя при этом ошибки.
Пример кода Python, реализующего генеративную состязательную сеть:
Сети GAN очень дороги в вычислительном отношении. Для получения хороших результатов им требуются мощные графические процессоры и много времени (большое количество эпох). В нашем примере мы будем использовать знаменитый набор данных MNIST и использовать его для создания клона случайной цифры.# importing the necessary libraries and the MNIST datasetimporttensorflow as tfimportnumpy as npimportmatplotlib.pyplot as pltfromtensorflow.examples.tutorials.mnistimportinput_datamnist=input_data.read_data_sets("MNIST_data")# defining functions for the two networks.# Both the networks have two hidden layers# and an output layer which are densely or# fully connected layers defining the# Generator network functiondefgenerator(z, reuse=None):with tf.variable_scope('gen', reuse=reuse):hidden1=tf.layers.dense(inputs=z, units=128,activation=tf.nn.leaky_relu)hidden2=tf.layers.dense(inputs=hidden1,units=128, activation=tf.nn.leaky_relu)output=tf.layers.dense(inputs=hidden2,units=784, activation=tf.nn.tanh)returnoutput# defining the Discriminator network functiondefdiscriminator(X, reuse=None):with tf.variable_scope('dis', reuse=reuse):hidden1=tf.layers.dense(inputs=X, units=128,activation=tf.nn.leaky_relu)hidden2=tf.layers.dense(inputs=hidden1,units=128, activation=tf.nn.leaky_relu)logits=tf.layers.dense(hidden2, units=1)output=tf.sigmoid(logits)returnoutput, logits# creating placeholders for the outputstf.reset_default_graph()real_images=tf.placeholder(tf.float32, shape=[None,784])z=tf.placeholder(tf.float32, shape=[None,100])G=generator(z)D_output_real, D_logits_real=discriminator(real_images)D_output_fake, D_logits_fake=discriminator(G, reuse=True)# defining the loss functiondefloss_func(logits_in, labels_in):returntf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=logits_in, labels=labels_in))# Smoothing for generalizationD_real_loss=loss_func(D_logits_real, tf.ones_like(D_logits_real)*0.9)D_fake_loss=loss_func(D_logits_fake, tf.zeros_like(D_logits_real))D_loss=D_real_loss+D_fake_lossG_loss=loss_func(D_logits_fake, tf.ones_like(D_logits_fake))# defining the learning rate, batch size,# number of epochs and using the Adam optimizerlr=0.001# learning rate# Do this when multiple networks# interact with each other# returns all variables created(the two# variable scopes) and makes trainable truetvars=tf.trainable_variables()d_vars=[varforvarintvarsif'dis'invar.name]g_vars=[varforvarintvarsif'gen'invar.name]D_trainer=tf.train.AdamOptimizer(lr).minimize(D_loss, var_list=d_vars)G_trainer=tf.train.AdamOptimizer(lr).minimize(G_loss, var_list=g_vars)batch_size=100# batch sizeepochs=500# number of epochs. The higher the better the resultinit=tf.global_variables_initializer()# creating a session to train the networkssamples=[]# generator exampleswith tf.Session() as sess:sess.run(init)forepochinrange(epochs):num_batches=mnist.train.num_examples//batch_sizeforiinrange(num_batches):batch=mnist.train.next_batch(batch_size)batch_images=batch[0].reshape((batch_size,784))batch_images=batch_images*2-1batch_z=np.random.uniform(-1,1, size=(batch_size,100))_=sess.run(D_trainer, feed_dict={real_images:batch_images, z:batch_z})_=sess.run(G_trainer, feed_dict={z:batch_z})print("on epoch{}".format(epoch))sample_z=np.random.uniform(-1,1, size=(1,100))gen_sample=sess.run(generator(z, reuse=True),feed_dict={z:sample_z})samples.append(gen_sample)# result after 0th epochplt.imshow(samples[0].reshape(28,28))# result after 499th epochplt.imshow(samples[49].reshape(28,28))Выход:
на эпоху0 на эпоху1 ... ... ... на эпоху498 на эпоху499
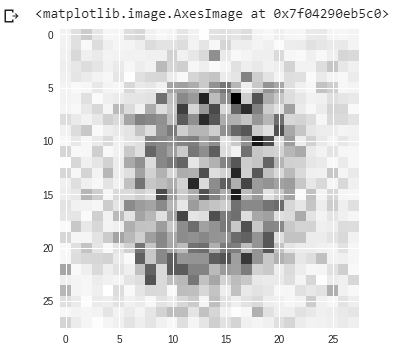
Результат после 0-й эпохи:
Ресулр после 499-й эпохи: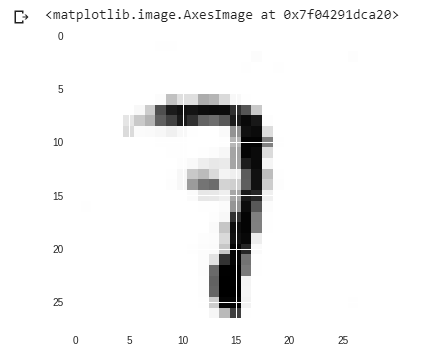
Итак, из приведенного выше примера мы видим, что на первом изображении после 0-й эпохи пиксели разбросаны повсюду, и мы не могли ничего понять из этого.
Но из второго изображения мы могли видеть, что пиксели более систематизированы, и мы могли выяснить, что это цифра «7», которую код произвольно выбрал, и сеть попыталась сделать ее клон. В нашем примере мы приняли 500 как количество эпох. Но вы можете увеличить это число, чтобы улучшить свой результат.Внимание компьютерщик! Укрепите свои основы с помощью базового курса программирования Python и изучите основы.
Для начала подготовьтесь к собеседованию. Расширьте свои концепции структур данных с помощью курса Python DS. А чтобы начать свое путешествие по машинному обучению, присоединяйтесь к курсу Машинное обучение - базовый уровень.