Функция WIDTH_BUCKET() в Oracle
WIDTH_BUCKET() — это математическая функция, используемая в Oracle и PostgreSQL. Как следует из названия, width_bucket означает разделение гистограммы на сегменты одинаковой ширины, то есть каждый сегмент имеет одинаковый размер/интервал. Эта функция принимает четыре входа: выражение, нижнюю границу, верхнюю границу выражения и количество групп, на которые мы хотим разделить гистограмму. Таким образом, после обработки выражения возвращается номер корзины, содержащий требуемое значение. Таким образом, используя функцию width_bucket, мы получаем гистограмму одинаковой ширины, но с разной высотой.
Функция width_bucket — очень полезная функция группировки.
Синтаксис:
WIDTH_BUCKET(expression, hist_min_value, hist_max_value, num_buckets)
Параметры:
- выражение: числовое выражение, которое должно быть сгруппировано с различными интервалами. Это выражение должно вычислять числовое значение или значение даты и времени либо значение, которое может быть неявно преобразовано в числовое значение или значение даты и времени. Значение должно находиться в диапазоне от -(2^53 – 1) до 2^53 – 1 (включительно).
- hist_min_value: числовое выражение или выражение значения даты и времени, которое предоставляет нижнюю границу/минимальное значение корзины.
- hist_max_value: числовое выражение или выражение значения даты и времени, которое предоставляет верхнюю границу/максимальное значение корзины.
- num_buckets: выражение INTEGER больше 0 указывает количество сегментов, на которые мы хотим разделить наше выражение.
ПРИМЕЧАНИЕ. MySQL и SQL Server не поддерживают WIDTH_BUCKET, но Oracle и PostgreSQL поддерживают синтаксис ANSI SQL для WIDTH_BUCKET.
Теперь возьмем пример, чтобы создать гистограмму с четырьмя баксами в столбце зарплаты сотрудников с зарплатами в диапазоне от 10 000 до 1 00 000 рупий. Функция возвращает номер корзины как – ГРУППА ПРОДАЖ для каждого значения в наборе.
Шаг 1: Создаем таблицу. Мы создали таблицу, которая состоит из 3 столбцов — идентификатора сотрудника, имени сотрудника и зарплаты сотрудника. Для этого мы используем приведенную ниже команду для создания таблицы с именем GeeksforGeeks_demo.
Запрос:
create table geeksforgeeks_demo(employee_id number, employee_name varchar(20),employee_salary number);
Выход:
Шаг 2: Это запрос на вставку строк в таблицу.
Запрос:
insert into GeeksforGeeks_demo values(1, "Chandler", 75000); insert into GeeksforGeeks_demo values(2, "Erica", 12500); insert into GeeksforGeeks_demo values(3, "Ron", 71000); insert into GeeksforGeeks_demo values(4, "Lucy", 52000); insert into GeeksforGeeks_demo values(5, "Adam", 22000); insert into GeeksforGeeks_demo values(6, "Steve", 48500); insert into GeeksforGeeks_demo values(7, "Monica", 84800); insert into GeeksforGeeks_demo values(8, "Rachel", 65000); insert into GeeksforGeeks_demo values(9, "Joey", 91500); insert into GeeksforGeeks_demo values(10, "Phoebe", 36000); insert into GeeksforGeeks_demo values(11, "Mike", 18000); insert into GeeksforGeeks_demo values(12, "Liam", 46000);
Выход:
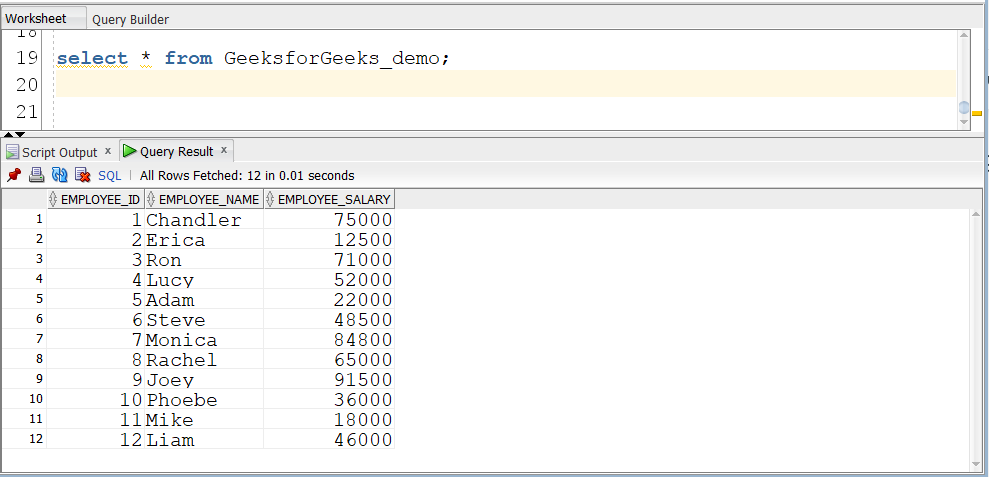
Шаг 3: Просмотр вставленных данных
Запрос:
select * from GeeksforGeeks_demo;
Выход:
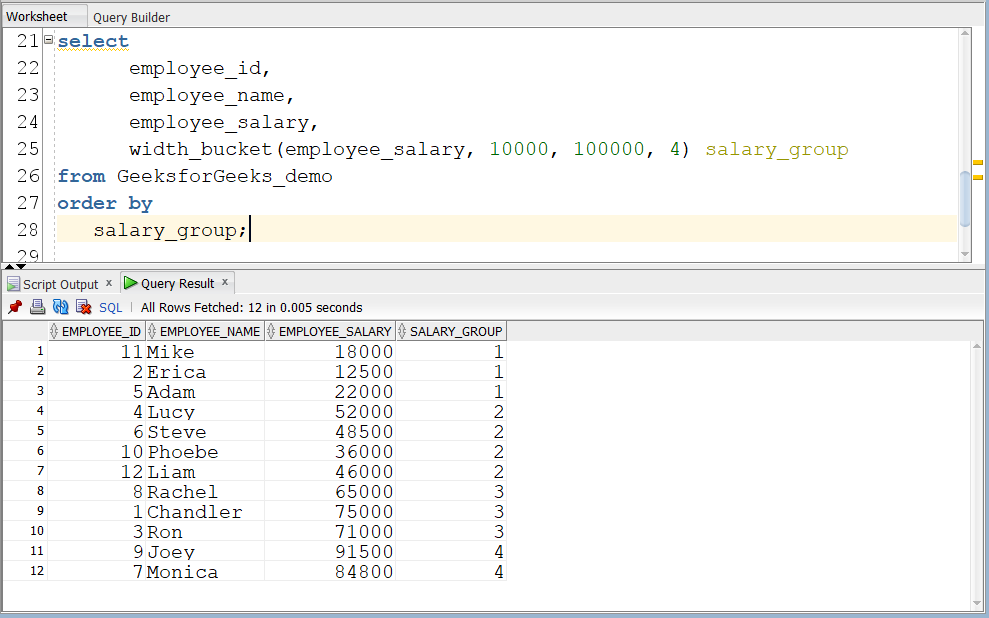
Шаг 4: Запросите таблицу, вызвав WIDTH_BUCKET():
Запрос:
select
employee_id,
employee_name,
employee_salary,
width_bucket(employee_salary,
10000, 100000, 4) salary_group
from GeeksforGeeks_demo
order by salary_group;Выход: