Архитектура MapReduce
MapReduce и HDFS - два основных компонента Hadoop, которые делают его настолько мощным и эффективным в использовании. MapReduce - это модель программирования, используемая для эффективной параллельной обработки больших наборов данных распределенным образом. Данные сначала разделяются, а затем объединяются для получения окончательного результата. Библиотеки для MapReduce написаны на очень многих языках программирования с различными оптимизациями. Назначение MapReduce в Hadoop - сопоставить каждое из заданий, а затем сократить его до эквивалентных задач для уменьшения накладных расходов в сети кластера и уменьшения вычислительной мощности. Задача MapReduce в основном разделена на две фазы: «Фаза карты» и «Фаза сокращения».
Архитектура MapReduce:
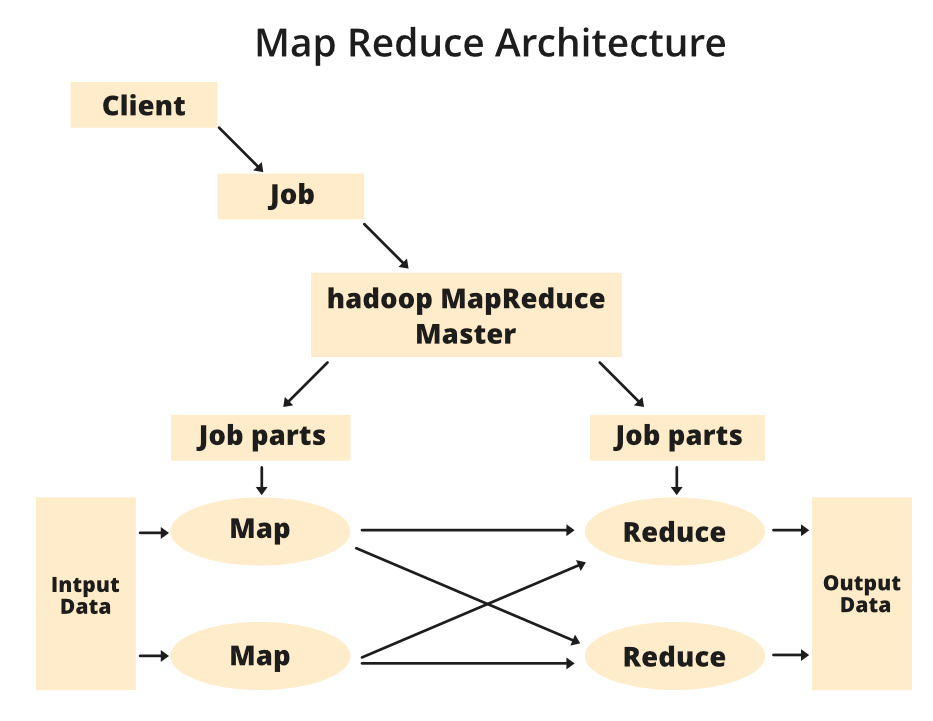
Компоненты архитектуры MapReduce:
- Клиент: Клиент MapReduce - это тот, кто передает задание в MapReduce для обработки. Может быть доступно несколько клиентов, которые непрерывно отправляют задания на обработку в Hadoop MapReduce Manager.
- Задание: задание MapReduce - это реальная работа, которую хотел выполнить клиент, которая состоит из множества более мелких задач, которые клиент хочет обработать или выполнить.
- Hadoop MapReduce Master: он разделяет конкретное задание на последующие части.
- Задания-части: задание или подзадачи, которые получаются после разделения основного задания. Результат объединения всех частей работы для получения окончательного результата.
- Входные данные: набор данных, который подается в MapReduce для обработки.
- Выходные данные: Окончательный результат получается после обработки.
В MapReduce у нас есть клиент. Клиент отправляет задание определенного размера мастеру Hadoop MapReduce. Теперь мастер MapReduce разделит это задание на другие эквивалентные части. Эти части задания затем становятся доступными для задачи сопоставления и сокращения. Эта задача Map and Reduce будет содержать программу в соответствии с требованиями варианта использования, который решает конкретная компания. Разработчик пишет свою логику для выполнения требований отрасли. Используемые нами входные данные затем передаются в задачу карты, и карта генерирует промежуточную пару ключ-значение в качестве вывода. Выходные данные Map, то есть эти пары ключ-значение, затем передаются в Reducer, а окончательный результат сохраняется в HDFS. В соответствии с требованиями для обработки данных может быть доступно n задач Map и Reduce. Алгоритм Map and Reduce сделан очень оптимизированным способом, так что временная сложность или пространственная сложность минимальны.
Давайте обсудим этапы MapReduce, чтобы лучше понять его архитектуру:
Задача MapReduce в основном разделена на 2 фазы: этап отображения и этап сокращения.
- Карта: как следует из названия, его основное использование - отображение входных данных в парах "ключ-значение". Входом в карту может быть пара «ключ-значение», где ключ может быть идентификатором какого-либо адреса, а значение - фактическим значением, которое он хранит. Функция Map () будет выполняться в своем хранилище памяти для каждой из этих входных пар ключ-значение и генерирует промежуточную пару ключ-значение, которая работает в качестве входных данных для функции Reducer или Reduce () .
- Reduce: промежуточные пары ключ-значение, которые работают в качестве входных данных для Reducer, перемешиваются, сортируются и отправляются в функцию Reduce (). Редуктор объединяет или группирует данные на основе пары ключ-значение в соответствии с алгоритмом редуктора, написанным разработчиком.
Как трекер заданий и трекер задач работают с MapReduce:
- Трекер заданий: работа трекера заданий заключается в управлении всеми ресурсами и всеми заданиями в кластере, а также в планировании каждой карты в диспетчере задач, работающей на одном и том же узле данных, поскольку в кластере могут быть сотни узлов данных.
- Трекер задач: Трекер задач можно рассматривать как фактических подчиненных устройств, которые работают по инструкции, данной Трекером заданий. Это средство отслеживания задач развертывается на каждом из узлов, доступных в кластере, который выполняет задачу сопоставления и сокращения в соответствии с инструкциями средства отслеживания заданий.
Существует также один важный компонент архитектуры MapReduce, известный как сервер истории заданий . Сервер истории заданий - это процесс-демон, который сохраняет и хранит историческую информацию о задаче или приложении, например, журналы, которые создаются во время или после выполнения задания, хранятся на сервере истории заданий.