Анатомия чтения и записи файлов в HDFS
Большие данные - это не что иное, как набор больших, сложных наборов данных, которые сложно хранить и обрабатывать с помощью доступных инструментов управления данными или традиционных приложений для обработки данных. Hadoop - это платформа (с открытым исходным кодом) для параллельной и распределенной записи, запуска, хранения и обработки больших наборов данных. Это решение, которое используется для преодоления проблем, с которыми сталкиваются большие данные.
Hadoop состоит из двух компонентов:
- HDFS (Распределенная файловая система Hadoop)
- ПРЯЖА (еще один переговорщик ресурсов)
В этой статье мы сосредоточимся на одном из компонентов Hadoop, то есть на HDFS, и на анатомии чтения и записи файлов в HDFS. HDFS - это файловая система, предназначенная для хранения очень больших файлов (файлов размером в сотни мегабайт, гигабайт или терабайт) с потоковым доступом к данным, работающей на кластерах стандартного оборудования (обычно доступное оборудование, которое можно получить от различных поставщиков). Проще говоря, хранилище Hadoop называется HDFS.
Некоторые характеристики HDFS:
- Отказоустойчивость
- Масштабируемость
- Распределенное хранилище
- Надежность
- Высокая доступность
- Экономически эффективным
- Высокая пропускная способность
Строительные блоки Hadoop:
- Имя узла
- Узел данных
- Узел вторичного имени (SNN)
- Трекер вакансий
- Трекер задач
Анатомия чтения файлов в HDFS
Давайте с помощью диаграммы получим представление о том, как потоки данных между клиентом, взаимодействующим с HDFS, узлом имени и узлами данных. Рассмотрим фигуру:
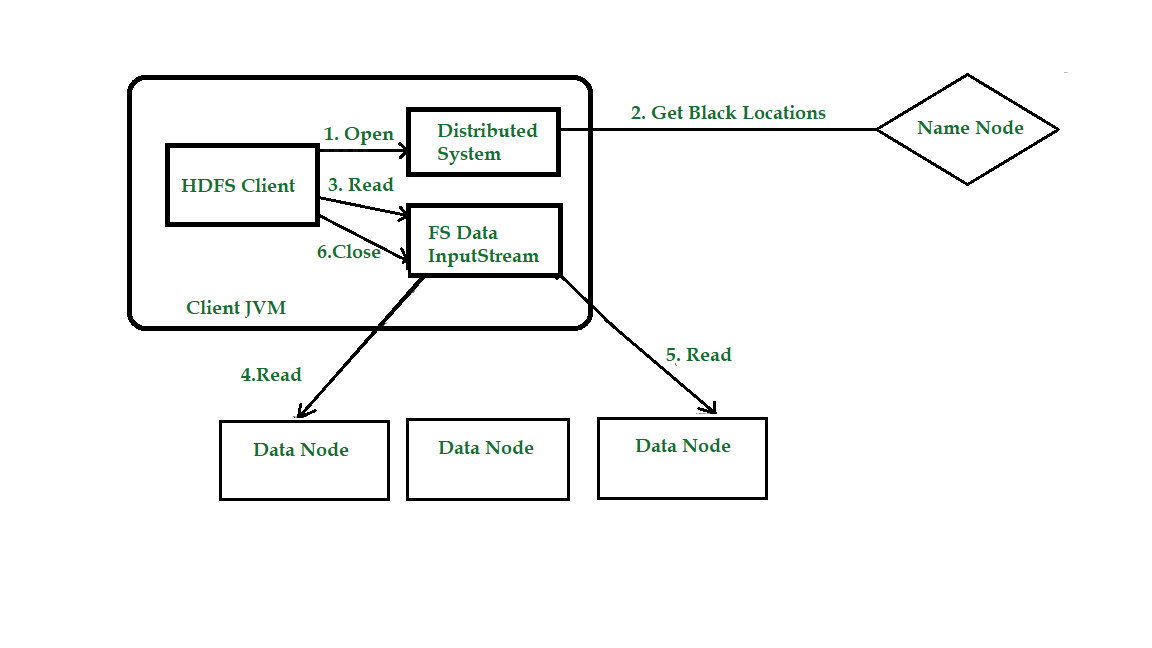
Шаг 1. Клиент открывает файл, который он хочет прочитать, вызывая open () для объекта файловой системы (который для HDFS является экземпляром распределенной файловой системы).
Шаг 2: Распределенная файловая система (DFS) вызывает узел имени, используя удаленные вызовы процедур (RPC), чтобы определить расположение первых нескольких блоков в файле. Для каждого блока узел имени возвращает адреса узлов данных, у которых есть копия этого блока. DFS возвращает клиенту FSDataInputStream, из которого он может считывать данные. FSDataInputStream, в свою очередь, является оболочкой для DFSInputStream, который управляет узлом данных и вводом-выводом узла имен.
Шаг 3. Затем клиент вызывает read () в потоке. DFSInputStream, в котором хранятся адреса информационных узлов для нескольких первичных блоков в файле, затем подключается к первичному (ближайшему) узлу данных для первичного блока в файле.
Шаг 4: данные передаются из узла данных обратно клиенту, который многократно вызывает read () в потоке.
Шаг 5: Когда будет достигнут конец блока, DFSInputStream закроет соединение с узлом данных, а затем найдет лучший узел данных для следующего блока. Это происходит прозрачно для клиента, который, с его точки зрения, просто читает бесконечный поток. Блоки читаются как, а DFSInputStream открывает новые соединения с узлами данных, поскольку клиент читает поток. Он также будет вызывать узел имени для извлечения местоположения узлов данных для следующего пакета блоков по мере необходимости.
Шаг 6: Когда клиент закончит чтение файла, вызывается функция close () для FSDataInputStream.
Анатомия записи файлов в HDFS
Далее мы проверим, как файлы записываются в HDFS. Рассмотрите рисунок 1.2, чтобы лучше понять концепцию.
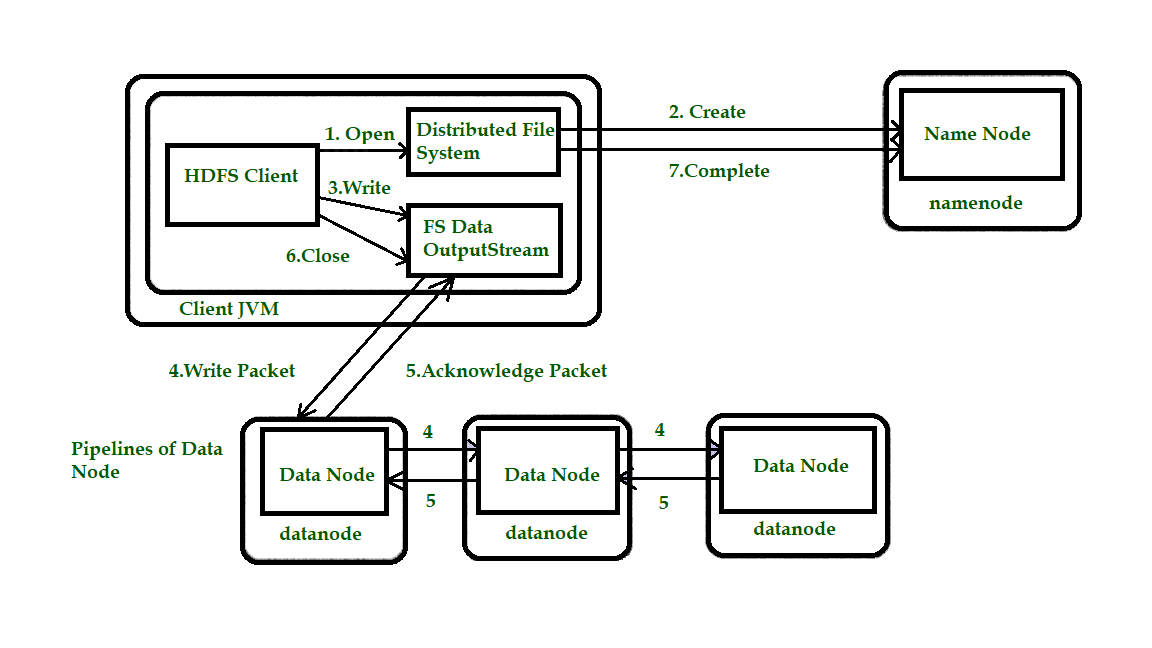
Шаг 1. Клиент создает файл, вызывая create () в DistributedFileSystem (DFS).
Шаг 2: DFS выполняет вызов RPC к узлу имени, чтобы создать новый файл в пространстве имен файловой системы без связанных с ним блоков. Узел имени выполняет различные проверки, чтобы убедиться, что файл еще не существует и что у клиента есть права на создание файла. Если эти проверки пройдены, узел имени подготавливает запись нового файла; в противном случае файл не может быть создан, и поэтому клиент выдает ошибку, то есть IOException. DFS возвращает FSDataOutputStream, чтобы клиент начал запись данных.
Шаг 3. Поскольку клиент записывает данные, DFSOutputStream разбивает их на пакеты, которые записываются во внутреннюю очередь, называемую информационной очередью. Очередь данных используется DataStreamer, который отвечает за запрос узла имени о выделении новых блоков путем выбора списка подходящих узлов данных для хранения реплик. Список узлов данных образует конвейер, и здесь мы предположим, что уровень репликации равен трем, поэтому в конвейере есть три узла. DataStreamer передает пакеты в основной узел данных в конвейере, который сохраняет каждый пакет и пересылает его второму узлу данных в конвейере.
Шаг 4. Точно так же второй узел данных сохраняет пакет и пересылает его третьему (и последнему) узлу данных в конвейере.
Шаг 5: DFSOutputStream поддерживает внутреннюю очередь пакетов, ожидающих подтверждения от узлов данных, называемую «очередью подтверждения».
Шаг 6: Это действие отправляет все оставшиеся пакеты в конвейер узла данных и ожидает подтверждения перед подключением к узлу имени, чтобы сообщить, завершен файл или нет.
HDFS следует за моделями Write Once Read Many. Итак, мы не можем редактировать файлы, которые уже хранятся в HDFS, но мы можем включить их, снова открыв файл. Такая конструкция позволяет масштабировать HDFS для большого количества одновременно работающих клиентов, поскольку трафик данных распределяется по всем узлам данных в кластере. Таким образом, увеличивается доступность, масштабируемость и пропускная способность системы.