Алгоритм априори в программировании на R
Алгоритм априори используется для поиска часто встречающихся наборов элементов в наборе данных для интеллектуального анализа правил ассоциации. Он называется Apriori, потому что он использует предварительные знания о часто используемых свойствах набора элементов. Мы применяем итерационный подход или поэтапный поиск, при котором k-частые наборы элементов используются для поиска k + 1 наборов элементов. Для повышения эффективности поэтапной генерации частых наборов элементов используется важное свойство, называемое свойством Apriori, которое помогает за счет сокращения пространства поиска. Этот алгоритм очень легко реализовать с помощью языка программирования R.
Apriori Property: All non-empty subsets of a frequent itemset must be frequent. Apriori assumes that all subsets of a frequent itemset must be frequent (Apriori property). If an itemset is infrequent, all its supersets will be infrequent.
По сути, алгоритм Apriori берет каждую часть большего набора данных и упорядоченным образом сравнивает ее с другими наборами. Полученные оценки используются для создания наборов, которые классифицируются как частые появления в большой базе данных для сбора агрегированных данных. В практическом смысле можно лучше понять алгоритм, посмотрев на такие приложения, как инструмент рыночной корзины, который помогает выяснить, какие товары покупаются вместе в рыночной корзине, или инструмент финансового анализа, который помогает показать, насколько разные акции движутся вместе. Алгоритм Apriori может использоваться в сочетании с другими алгоритмами для эффективной сортировки и сопоставления данных, чтобы показать гораздо лучшую картину того, как сложные системы отражают закономерности и тенденции.
Важный Терминологии
- Поддержка: Поддержка - это показатель того, как часто набор элементов появляется в наборе данных. Это количество записей, содержащих элемент «x», деленное на общее количество записей в базе данных.
- Уверенность: Уверенность - это такая мера времени, когда если покупается предмет «x», то предмет «y» также покупается вместе. Это количество поддержки, равное (x U y), деленное на количество поддержки, равное «x».
- Подъем: Подъем - это отношение наблюдаемой поддержки к ожидаемой, если бы «x» и «y» были независимыми. Это количество опор (x U y), деленное на произведение индивидуальных подсчетов опор «x» и «y».
Алгоритм
- Прочтите каждый элемент транзакции.
- Подсчитайте поддержку каждого элемента.
- Если поддержка меньше минимальной, выбросьте предмет. Или вставьте его в часто используемый набор элементов.
- Рассчитайте достоверность для каждого непустого подмножества.
- Если достоверность меньше минимальной достоверности, отбросьте подмножество. В противном случае это строгие правила.
Реализация априорного алгоритма в R
RStudio предоставляет популярное профессиональное программное обеспечение с открытым исходным кодом и готово для предприятий для среды статистических вычислений R. R - это язык, разработанный для поддержки статистических вычислений и графических вычислений / визуализаций. Он имеет встроенную библиотечную функцию под названием arules, которая реализует алгоритм Apriori для анализа рыночной корзины и вычисляет строгие правила посредством майнинга ассоциативных правил, как только мы указываем минимальную поддержку и минимальную уверенность в соответствии с нашими потребностями. Ниже приведены требуемый код и соответствующие выходные данные для алгоритма Apriori. Для этого использовался набор данных Groceries , который доступен в базе данных по умолчанию R. Он содержит 9835 транзакций / записей, каждая из которых содержит n товаров, которые были куплены вместе в продуктовом магазине.
Пример:
Шаг 1. Загрузите необходимую библиотеку
Пакет arules предоставляет инфраструктуру для представления, обработки и анализа данных и шаблонов транзакций.
библиотека (рулес)
Пакет arulesviz используется для визуализации правил связывания и часто встречающихся наборов элементов. Он расширяет пакет «arules» с помощью различных методов визуализации для ассоциативных правил и наборов элементов. Пакет также включает несколько интерактивных визуализаций для изучения правил.
библиотека (arulesViz)
RColorBrewer - это палитра ColorBrewer, которая предоставляет цветовые схемы для карт и другой графики.
библиотека (RColorBrewer)
Шаг 2. Импортируйте набор данных
Набор данных «Бакалея» предопределен в пакете R. Это набор из 9835 записей / транзакций, каждая из которых содержит n товаров, которые были куплены вместе в продуктовом магазине.
данные («Продовольственные товары»)
Шаг 3. Применение функции apriori ()
Функция apriori () встроена в R для поиска частых наборов элементов и правил ассоциации с использованием алгоритма Apriori. Здесь «Продовольственные товары» - это данные транзакции. «параметр» - это именованный список, который определяет минимальную поддержку и достоверность для поиска правил ассоциации. По умолчанию используются правила с минимальной поддержкой 0,1 и 0,8 в качестве минимальной достоверности. Здесь мы указали, что минимальная поддержка составляет 0,01, а минимальная достоверность - 0,2.
rules <- apriori(Groceries, parameter = list(supp = 0.01, conf = 0.2))
Шаг 4. Применение функции inspect ()
Функция inspect () печатает внутреннее представление объекта R или результат выражения. Здесь показаны первые 10 правил сильной ассоциации.
осмотреть (правила [1:10])
Шаг 5: Применение функции itemFrequencyPlot ()
itemFrequencyPlot () создает гистограмму для частот / поддержки элементов. Он создает гистограмму частоты элементов для проверки распределения объектов на основе транзакций. Элементы расположены в порядке убывания опоры. Здесь «topN = 20» означает, что будут отображены 20 элементов с наивысшей частотой / ростом количества элементов.
arules :: itemFrequencyPlot (Продовольственные товары, topN = 20,
col = brewer.pal (8, 'Пастель2'),
main = 'График относительной частоты товара',
type = "относительный",
ylab = "Частота товара (относительная)")The complete R code is given below.
R
# Loding Librarieslibrary(arules)library(arulesViz)library(RColorBrewer) # import datasetdata("Groceries") # using apriori() functionrules <- apriori(Groceries, parameter = list(supp = 0.01, conf = 0.2)) # using inspect() functioninspect(rules[1:10]) # using itemFrequencyPlot() functionarules::itemFrequencyPlot(Groceries, topN = 20, col = brewer.pal(8, "Pastel2"), main = "Relative Item Frequency Plot", type = "relative", ylab = "Item Frequency (Relative)") |
Выход:
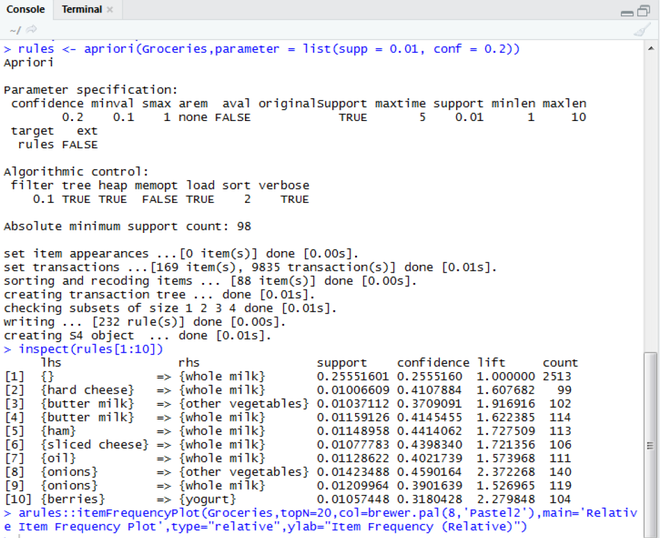
Сильные правила:
Сильные правила, полученные после применения алгоритма априори, следующие.
После выполнения приведенного выше кода для алгоритма Apriori мы можем увидеть следующий результат, в котором указаны первые 10 самых сильных правил ассоциации на основе поддержки (минимальная поддержка 0,01), уверенности (минимальная достоверность 0,2) и подъема, а также упоминания количество раз, когда продукты встречаются вместе в транзакциях.
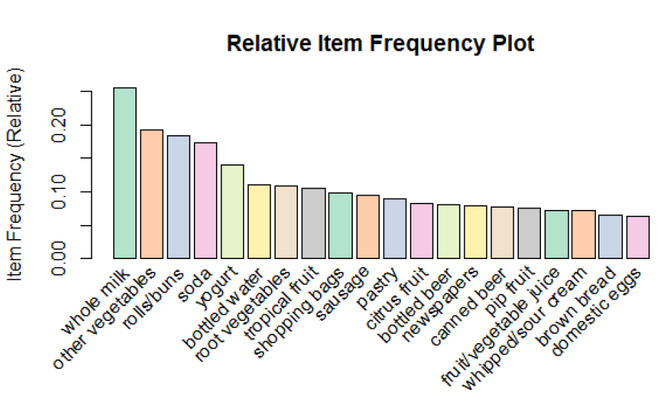
Визуализация:
Коробчатая диаграмма 20 товаров с наибольшей частотой (относительной) с использованием роста в качестве параметра
Заключение
Мы использовали набор данных «Бакалея », который содержит около 9835 транзакций, включающих «n» товаров, которые были куплены вместе в магазине. При запуске алгоритма Apriori над набором данных с минимальным значением поддержки 0,01 и минимальной достоверностью 0,2 мы отфильтровали строгие правила ассоциации в транзакции. Мы перечислили первые 10 транзакций выше, а также диаграмму 20 лучших элементов, имеющих наивысшую относительную частоту. Некоторые правила ассоциации, которые мы можем заключить из этой программы:
- Если покупается твердый сыр, то покупается и цельное молоко.
- Если пахта покупается, то на нее покупается и цельное молоко.
- Если покупается пахта, то вместе покупаются и другие овощи.
- Кроме того, цельное молоко имеет высокую поддержку и ценность.
Следовательно, будет выгодно класть «цельное молоко» на видимую и доступную полку, поскольку это один из наиболее часто покупаемых товаров. Кроме того, рядом с полкой, на которую кладется «пахта», должны быть полки для «цельного молока» и «других овощей», поскольку их достоверность довольно высока. Так что вероятность купить их вместе с пахтой выше. Таким образом, подобными действиями мы можем стремиться к увеличению продаж и прибыли продуктового магазина, анализируя модели покупок пользователей.