Веб-парсинг с использованием языка R
Одна из самых важных вещей в области науки о данных - это умение получать правильные данные для проблемы, которую вы хотите решить. Специалисты по анализу данных не всегда имеют подготовленную базу данных для работы, а скорее должны извлекать данные из правильных источников. Для этого используются API и веб-парсинг.
- API (интерфейс прикладных программ) : API - это набор методов и инструментов, позволяющих запрашивать и извлекать данные динамически. Reddit, Spotify, Twitter, Facebook и многие другие компании предоставляют бесплатные API-интерфейсы, которые позволяют разработчикам получать доступ к информации, которую они хранят на своих серверах; другие взимают плату за доступ к своим API.
- Веб-парсинг : многие данные недоступны через наборы данных или API-интерфейсы, а существуют в Интернете в виде веб-страниц. Таким образом, с помощью веб-скрейпинга можно получить доступ к данным, не дожидаясь, пока поставщик создаст API.
Что такое парсинг веб-страниц?
Веб-скрапинг - это метод получения данных с веб-сайтов. Во время серфинга в Интернете многие веб-сайты не позволяют пользователю сохранять данные для личного использования. Один из способов - вручную скопировать и вставить данные, что утомительно и требует много времени. Веб-парсинг - это автоматический процесс извлечения данных с веб-сайтов. Этот процесс выполняется с помощью программного обеспечения для очистки веб-страниц, известного как веб-парсеры. Они автоматически загружают и извлекают данные с веб-сайтов в зависимости от требований пользователя. Они могут быть настроены для работы с одним сайтом или могут быть настроены для работы с любым сайтом.
Реализация парсинга веб-страниц с использованием R
Есть несколько инструментов для парсинга веб-страниц для выполнения этой задачи и на разных языках, а также библиотеки, поддерживающие парсинг веб-страниц. Среди всех этих языков R считается одним из языков программирования для веб-парсинга из-за таких функций, как богатая библиотека, простота в использовании, динамически типизированная и т. Д. Наиболее часто используемыми инструментами веб- парсинга для R являются rvest.
Предпосылки :
- Установите пакет rvest в свою R Studio, используя следующий код.
install.packages ('rvest') - Знание HTML и CSS будет дополнительным преимуществом. Замечено, что большинство специалистов по данным не очень хорошо знакомы с техническими знаниями HTML и CSS. Поэтому давайте воспользуемся программным обеспечением с открытым исходным кодом под названием Selector Gadget, которого будет более чем достаточно для любого, чтобы выполнять парсинг веб-страниц. Здесь можно получить доступ к расширению Selector Gadget и загрузить его. Учтите, что это расширение установлено, следуя инструкциям с веб-сайта. Также рассмотрите возможность использования Google Chrome, и он / она может получить доступ к расширению на панели расширений в правом верхнем углу.
Шаги, связанные с веб-парсингом :
- Шаг 1. Перед началом написания кода импортируйте библиотеки Rvest в свою R Studio.
library(rvest) - Шаг 2. Прочтите HTML-код с веб-страницы. Рассмотрим эту веб-страницу.
- Шаг 3 : Теперь давайте начнем с очистки поля заголовка. Для этого используйте гаджет селектора, чтобы получить определенные селекторы CSS, которые включают заголовок. Можно щелкнуть расширение в своем браузере и выбрать поле заголовка курсором.
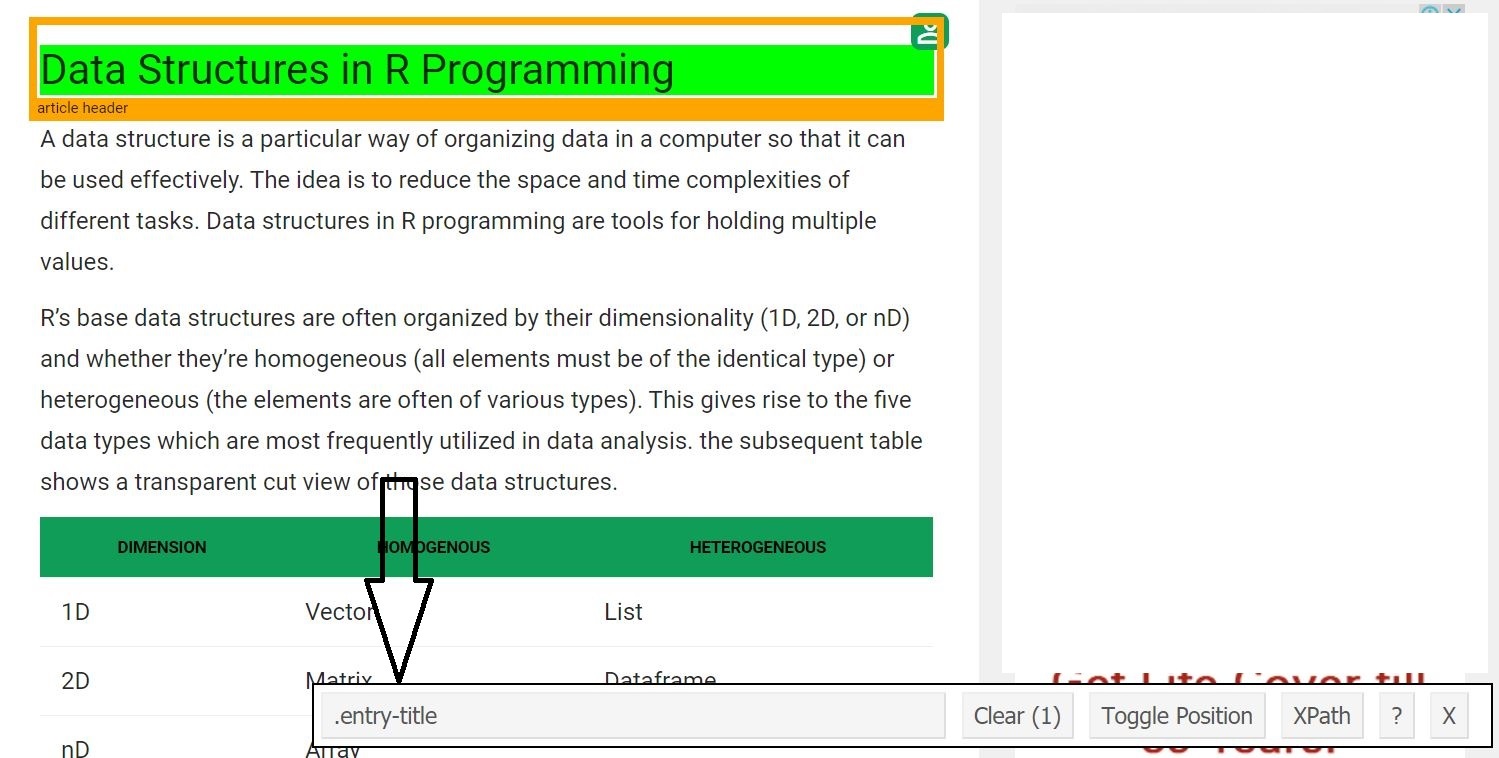
Как только кто-то знает селектор CSS, содержащий заголовок, он / она может использовать этот простой код R для получения заголовка.
# Using CSS selectors to scrape the heading sectionheading=html_node(webpage,'.entry-title')# Converting the heading data to texttext=html_text(heading)print(text)Выход:
[1] "Структуры данных в программировании на R"
- Шаг 4 : Теперь давайте очистим все поля абзаца. Для этого проделали ту же процедуру, что и раньше.
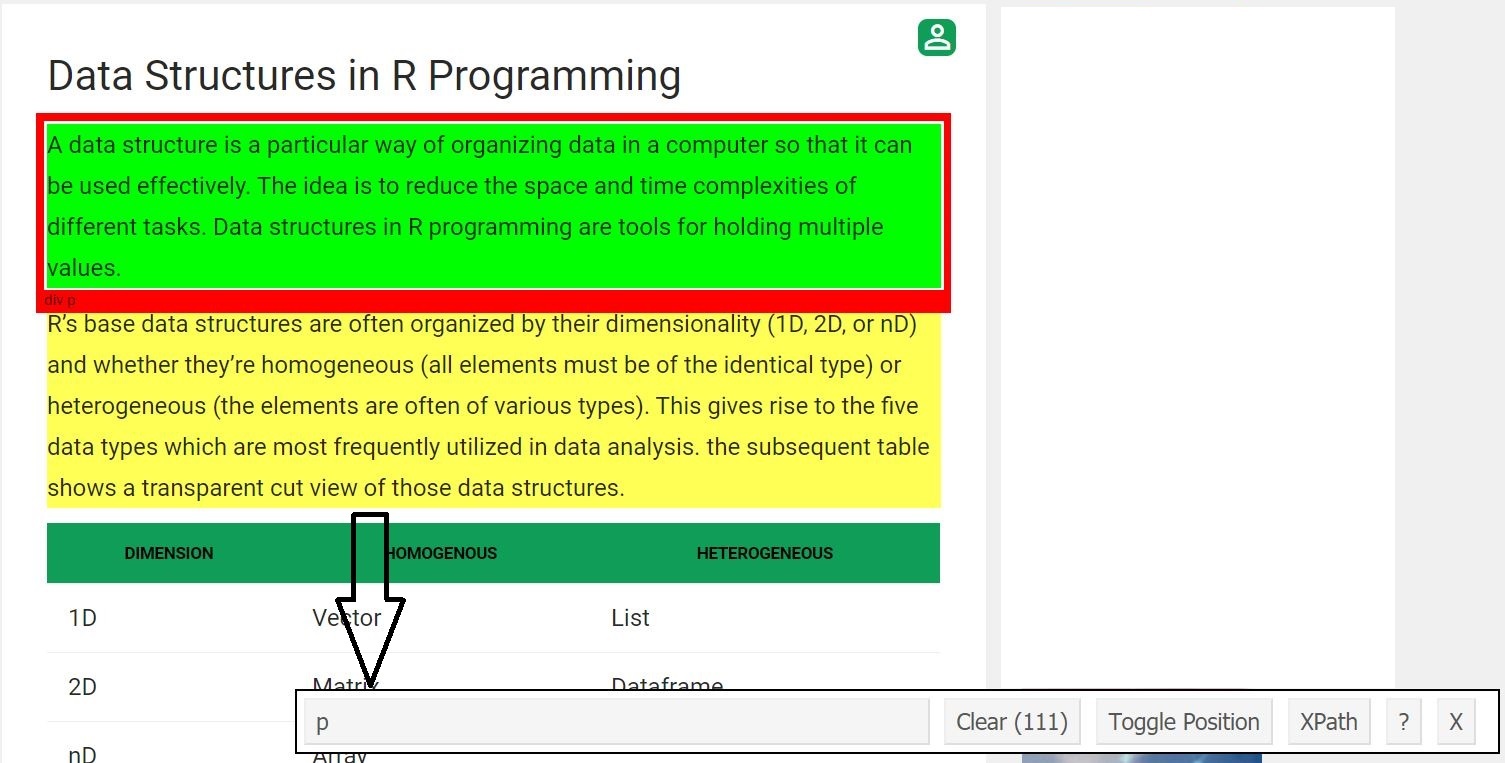
Как только кто-то знает селектор CSS, который содержит абзацы, он / она может использовать этот простой код R, чтобы получить все абзацы.
# Using CSS selectors to scrape# all the paragraph section# Note that we use html_nodes() hereparagraph=html_nodes(webpage,'p')# Converting the heading data to textpText=html_text(paragraph)# Print the top 6 dataprint(head(pText))Выход:
[1] “A data structure is a particular way of organizing data in a computer so that it can be used effectively. The idea is to reduce the space and time complexities of different tasks. Data structures in R programming are tools for holding multiple values. ”
[2] “R’s base data structures are often organized by their dimensionality (1D, 2D, or nD) and whether they’re homogeneous (all elements must be of the identical type) or heterogeneous (the elements are often of various types). This gives rise to the five data types which are most frequently utilized in data analysis. the subsequent table shows a transparent cut view of those data structures.”
[3] “The most essential data structures used in R include:”
[4] “”
[5] “A vector is an ordered collection of basic data types of a given length. The only key thing here is all the elements of a vector must be of the identical data type e.g homogenous data structures. Vectors are one-dimensional data structures.”
[6] “Example:”
Полный код R приведен ниже.
# R program to illustrate# Web Scraping # Import rvest librarylibrary(rvest) # Reading the HTML code from the website # Using CSS selectors to scrape the heading sectionheading = html_node(webpage, '.entry-title' ) # Converting the heading data to texttext = html_text(heading)print (text) # Using CSS selectors to scrape# all the paragraph section# Note that we use html_nodes() hereparagraph = html_nodes(webpage, 'p' ) # Converting the heading data to textpText = html_text(paragraph) # Print the top 6 dataprint (head(pText)) |