Удаление стоп-слов с помощью NLTK в Python
Процесс преобразования данных во что-то, что может понять компьютер, называется предварительной обработкой. Одна из основных форм предварительной обработки - отфильтровывать бесполезные данные. При обработке естественного языка бесполезные слова (данные) называются стоп-словами.
Что такое стоп-слова?
Стоп-слова: стоп-слово - это часто используемое слово (например, «the», «a», «an», «in»), которое поисковая система запрограммирована игнорировать, как при индексировании записей для поиска, так и при их извлечении. в результате поискового запроса.
Мы бы не хотели, чтобы эти слова занимали место в нашей базе данных или драгоценное время обработки. Для этого мы можем легко удалить их, сохранив список слов, которые вы считаете стоп-словами. NLTK (Natural Language Toolkit) в python имеет список стоп-слов, хранящихся на 16 разных языках. Вы можете найти их в каталоге nltk_data. home / pratima / nltk_data / corpora / stopwords - это адрес каталога. (не забудьте изменить имя домашнего каталога) 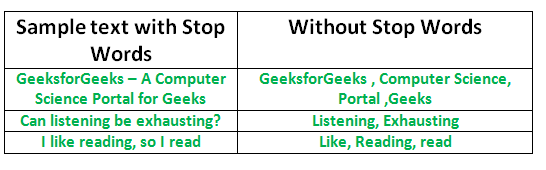
Чтобы проверить список игнорируемых слов, вы можете ввести следующие команды в оболочке python.
импортировать nltk
из nltk.corpus импортировать стоп-слова
print (stopwords.words ('английский')){'мы', 'ее', 'между', 'ты', 'но', 'снова', 'там', 'примерно', 'однажды', 'во время', 'вне', 'очень', ' имея ',' с ',' они ',' владеть ',' ан ',' быть ',' какой-то ',' для ',' делать ',' свой ',' твой ',' такой ',' в ' , 'из', 'большинство', 'сам', 'другой', 'выкл', 'есть', 's', 'am', 'или', 'who', 'as', 'from', ' он ',' каждый ',' тот ',' себя ',' до ',' ниже ',' есть ',' мы ',' эти ',' твой ',' его ',' через ',' не ' , 'ни', 'я', 'были', 'она', 'больше', 'сам', 'это', 'вниз', 'должен', 'наш', 'их', 'пока', ' выше ',' оба ',' вверх ',' к ',' наш ',' имел ',' она ',' все ',' нет ',' когда ',' в ',' любой ',' до ' , 'они', 'такой же', 'и', 'был', 'иметь', 'в', 'будет', 'на', 'делает', 'себя', 'то', 'тот', ' потому что ',' что ',' больше ',' почему ',' так ',' могу ',' сделал ',' не ',' сейчас ',' под ',' он ',' ты ',' сама ' , 'имеет', 'просто', 'где', 'тоже', 'только', 'я', 'который', 'те', 'я', 'после', 'несколько', 'кого', ' т ',' быть ',' если ',' их ',' мой ',' против ',' а ',' по ',' делаю ',' это ',' как ',' дальше ',' было ' , 'здесь', 'та n '}
Примечание. Вы даже можете изменить список, добавив слова по вашему выбору в английский .txt. файл в каталоге игнорируемых слов.
Удаление стоп-слов с помощью NLTK
Следующая программа удаляет стоп-слова из фрагмента текста:
from nltk.corpus import stopwordsfrom nltk.tokenize import word_tokenize example_sent = """This is a sample sentence, showing off the stop words filtration.""" stop_words = set (stopwords.words( 'english' )) word_tokens = word_tokenize(example_sent) filtered_sentence = [w for w in word_tokens , not w in stop_words] if not w in stop_words] filtered_sentence = [] for w in word_tokens: if w not in stop_words: filtered_sentence.append(w) print (word_tokens)print (filtered_sentence) |
Выход:
['Это', 'есть', 'a', 'образец', 'предложение', ',', 'показ', 'выкл', 'в', 'стоп', 'слова', 'фильтрация', '.'] ['Это', 'образец', 'предложение', ',', 'показ', 'стоп', 'слова', 'фильтрация', '.']
Выполнение операций Stopwords в файле
В приведенном ниже коде text.txt - это исходный входной файл, из которого нужно удалить стоп-слова. filtertext.txt - это выходной файл. Это можно сделать с помощью следующего кода:
import iofrom nltk.corpus import stopwordsfrom nltk.tokenize import word_tokenize # word_tokenize accepts# a string as an input, not a file.stop_words = set (stopwords.words( 'english' ))file1 = open ( "text.txt" ) # Use this to read file content as a stream:line = file1.read()words = line.split()for r in words: if not r in stop_words: appendFile = open ( 'filteredtext.txt' , 'a' ) appendFile.write( " " + r) appendFile.close() |
Таким образом мы делаем наш обрабатываемый контент более эффективным, удаляя слова, которые не влияют на какие-либо будущие операции.
Эта статья предоставлена Пратимой Упадхьяй . Если вам нравится GeeksforGeeks, и вы хотели бы внести свой вклад, вы также можете написать статью с помощью provide.geeksforgeeks.org или отправить ее по электронной почте на deposit@geeksforgeeks.org. Посмотрите, как ваша статья появляется на главной странице GeeksforGeeks, и помогите другим гикам.
Пожалуйста, напишите комментарии, если вы обнаружите что-то неправильное, или вы хотите поделиться дополнительной информацией по теме, обсужденной выше.
Внимание компьютерщик! Укрепите свои основы с помощью базового курса программирования Python и изучите основы.
Для начала подготовьтесь к собеседованию. Расширьте свои концепции структур данных с помощью курса Python DS. А чтобы начать свое путешествие по машинному обучению, присоединяйтесь к курсу Машинное обучение - базовый уровень.