Тест Шапиро – Уилка в программировании на R
Тест Шапиро-Уилка или тест Шапиро - это тест на нормальность в частотной статистике. Нулевая гипотеза теста Шапиро состоит в том, что популяция распределена нормально. Это один из трех тестов на нормальность, предназначенных для обнаружения всех видов отклонений от нормы. Если значение p равно или меньше 0,05, то гипотеза о нормальности будет отклонена тестом Шапиро. В случае неудачи тест может констатировать, что данные не будут соответствовать нормальному распределению с достоверностью 95%. Однако при прохождении теста можно констатировать, что существенного отклонения от нормы не существует. Этот тест можно очень легко выполнить в программировании на R.
Формула теста Шапиро-Уилка
Предположим, что образец, скажем x 1 , x 2 …… .x n , был получен из нормально распределенной совокупности. Тогда согласно тестам Шапиро-Уилка проверка нулевой гипотезы
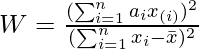
where,
- x(i) : it is the ith smallest number in the given sample.
- mean(x) : ( x1+x2+……+xn) / n i.e the sample mean.
- ai : coefficient that can be calculated as (a1,a2,….,an) = (mT V-1)/C . Here V is the covariance matrix, m and C are the vector norms that can be calculated as C= || V-1 m || and m = (m1, m2,……, mn ).
Реализация в R
Для выполнения теста Шапиро Уилка R предоставляет функцию shapiro.test () .
Syntax:
shapiro.test(x)
Parameter:
x : a numeric vector containing the data values. It allows missing values but the number of missing values should be of the range 3 to 5000.
Давайте посмотрим, как выполнить тест Шапиро Уилка шаг за шагом.
- Шаг 1: Сначала установите необходимые пакеты . Для выполнения теста необходимы два пакета: dplyr . Пакет dplyr необходим для эффективного управления данными. Установить пакеты из консоли R можно следующим образом:
install.packages ("dplyr")
- Шаг 2: Теперь загрузите установленные пакеты в сценарий R. Это можно сделать с помощью функции library () следующим образом.
р
# loading the packagelibrary (dplyr) |
- Шаг 3: Самая важная задача - выбрать правильный набор данных . Здесь давайте поработаем с набором данных ToothGrowth. Это встроенный набор данных в библиотеке R.
р
# loading the packagelibrary ( "dplyr" ) # Using the ToothGrowth data set# loading the data setmy_data <- ToothGrowth |
Также можно создать собственный набор данных. Для этого сначала подготовьте данные, затем сохраните файл и затем импортируйте набор данных в сценарий. Файл может включать в себя, используя следующий синтаксис:
data <- read.delim (file.choose ()), если формат файла .txt data <- read.csv (file.choose ()), если формат файла .csv
- Шаг 4: Теперь выберите случайное число с помощью функции set.seed () . После чего мы начинаем отображать выходной образец из 10 строк, выбранных случайным образом с помощью функции sample_n () пакета dplyr. Вот как мы проверяем наши данные.
р
# loading the packagelibrary ( "dplyr" ) # Using the ToothGrowth package# loading the data setmy_data <- ToothGrowth # Using the set.seed() for# random number generationset.seed (1234) # Using the sample_n() for# random sample of 10 rowsdplyr:: sample_n (my_data, 10) |
Выход:
лен суп доза 1 11,2 VC 0,5 2 8,2 ОДж 0,5 3 10,0 ОДж 0,5 4 27,3 OJ 2,0 5 14,5 ОДж 1,0 6 26,4 OJ 2,0 7 4,2 VC 0,5 8 15,2 ВК 1.0 9 14,5 ОДж 0,5 10 26,7 ВК 2,0
- Шаг 5: Наконец выполните тест Шапиро Уилка с помощью функции shapiro.test () .
р
# loading the packagelibrary ( "dplyr" ) # Using the ToothGrowth package# loading the data setmy_data <- ToothGrowth # Using the set.seed()# for random number generationset.seed (1234) # Using the sample_n()# for random sample of 10 rowsdplyr:: sample_n (my_data, 10) # Using the shapiro.test() to check# for normality based# on the len parametershapiro.test (my_data$len) |
Выход:
> dplyr :: sample_n (мои_данные, 10)
лен суп доза
1 11,2 VC 0,5
2 8,2 ОДж 0,5
3 10,0 ОДж 0,5
4 27,3 OJ 2,0
5 14,5 ОДж 1,0
6 26,4 OJ 2,0
7 4,2 VC 0,5
8 15,2 ВК 1.0
9 14,5 ОДж 0,5
10 26,7 ВК 2,0
> shapiro.test (my_data $ len)
Тест Шапиро-Уилка на нормальность
данные: my_data $ len
W = 0,96743, значение p = 0,1091
Исходя из полученного результата, можно предположить нормальность. Значение p больше 0,05. Следовательно, распределение данных данных существенно не отличается от нормального распределения.