Создание моделей в Cassandra
Предварительное условие - Введение в Cassandra, Обзор моделирования данных
В этой статье мы собираемся обсудить, как мы можем разработать модель в Cassandra. Моделирование дизайна - одна из ключевых составляющих любого приложения. Итак, давайте обсудим, как мы можем сделать лучшую модель для любого приложения на примере, мы увидим, как мы можем это сделать.
Как вы увидите, у Кассандры другой подход к моделированию данных, чем к моделированию РСУБД. Мы можем увидеть разницу при обсуждении моделирования данных. В СУБД мы можем выполнять СОЕДИНЕНИЯ при создании таблиц, а также мы можем избежать дублирования, используя внешний ключ в соответствующих таблицах.
В Cassandra мы можем сказать, что это не так, и Cassandra - это распределенная система, и мы можем денормализовать данные там, где это необходимо. В РСУБД мы можем извлекать и извлекать через JOIN, в то время как в Cassandra это может быть дорого, потому что мы можем извлекать данные с помощью ключей разделов, а в Cassandra данные распределены по узлам в Cassandra.
Цели, которые следует учитывать при разработке моделей -
- Равномерное распределение данных:
В кластере равномерное распределение данных является одной из ключевых целей, так что для одного столбца первичный ключ будет ключом разделения, а для составного первичного ключа ключ разделения будет ключом раздела и ключом кластера. У нас должен быть первичный ключ (PK) на основе уникальности, например, мы можем сказать, что ID, адрес электронной почты, имя пользователя должно быть выбрано в качестве PK, поэтому в этом случае кластер узлов будет полностью использован. - Минимизация количества чтений:
В Cassandra мы должны заранее знать запросы, которые потребуются в системе, а затем соответствующим образом проектировать модель. В Cassandra, если один запрос извлекает данные из нескольких разделов, это может повлиять на производительность системы, что замедлит ее работу. В РСУБД у нас есть такая свобода, что мы можем создать запрос после разработки схемы, которая показывает, чем она на самом деле отличается от нереляционной модели.
Пример использования:
Количество людей, посещающих веб-сайт, и руководство желает получить следующую информацию, указанную ниже. Давайте посмотрим.
- Список всех сотрудников
- Список всего домена.
- Список сотрудников по доменам
Теперь давайте создадим таблицу одну за другой. Сначала мы собираемся создать таблицу Domain.
СОЗДАТЬ ТАБЛИЦУ Домен ( D_id int, Текст D_name, Текст D_info, ПЕРВИЧНЫЙ КЛЮЧ (D_id) );
Теперь мы собираемся создать таблицу сотрудников.
СОЗДАТЬ ТАБЛИЦУ Сотрудник ( имя пользователя Варчар, E_name текст, E_age int, ПЕРВИЧНЫЙ КЛЮЧ (имя пользователя) );
Теперь мы собираемся вставить некоторые данные в таблицу домена.
INSERT INTO домен (D_id, D_name, D_info) ЗНАЧЕНИЯ (1, «база данных», «50 элементов»); INSERT INTO домен (D_id, D_name, D_info) ЦЕННОСТИ (2, «Менеджмент», «10 членов»); INSERT INTO домен (D_id, D_name, D_info) ЦЕННОСТИ (3, «Сеть», «15 участников»); INSERT INTO домен (D_id, D_name, D_info) ЗНАЧЕНИЯ (4, «программное обеспечение», «50 элементов»);
Теперь мы собираемся вставить некоторые данные в таблицу Employee.
ВСТАВИТЬ сотрудника (имя пользователя, E_name, E_age) ЦЕННОСТИ («Альфа007», «Ашиш», 23); ВСТАВИТЬ сотрудника (имя пользователя, E_name, E_age) ЗНАЧЕНИЯ («Алиса007», «Алиса», 23); ВСТАВИТЬ В сотрудника (имя пользователя, E_name, E_age) ЗНАЧЕНИЯ (Bob007, Bob, 23);
В случае РСУБД мы можем использовать Domain_id в качестве внешнего ключа в таблице сотрудников, и с помощью JOIN мы можем получить данные, но мы проектируем модель в Cassandra. Итак, в случае Cassandra мы должны создать другую таблицу, которая удовлетворит потребности в соответствии с требованиями.
СОЗДАТЬ ТАБЛИЦУ Employees_by_Domains ( имя пользователя varchar, E_name текст, Текст D_name, E_age int, ПЕРВИЧНЫЙ КЛЮЧ (D_name, E_age) );
В таблице «Сотрудники по доменам» первичный ключ состоит из двух частей: первая - это D_name, первичный ключ, а вторая - E_age, который является ключом кластера, а записи кластеризованы по E_age.
вставить в Employees_by_Domains (имя пользователя, E_name, D_name, E_age) ЗНАЧЕНИЯ («Ashish001», «Rana», «Программное обеспечение Er.», 23); вставить в Employees_by_Domains (имя пользователя, E_name, D_name, E_age) ЗНАЧЕНИЯ («Алиса007», «Алиса», «База данных», 25); вставить в Employees_by_Domains (имя пользователя, E_name, D_name, E_age) ЗНАЧЕНИЯ (Bob007, Bob, Networking, 26);
Теперь мы увидим результаты каждой таблицы и получим данные в соответствии с вариантом использования.
Давайте посмотрим.
Чтобы увидеть результат таблицы домена, используется следующий запрос CQL, приведенный ниже.
Выбирать * из домена;
Выход:
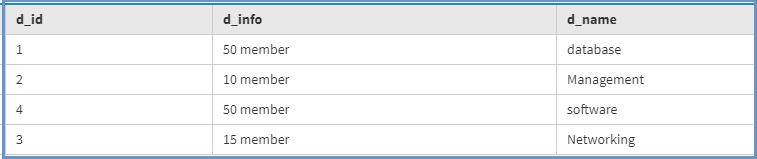
Чтобы увидеть результат таблицы Employee, используется следующий запрос CQL, приведенный ниже.
Выбирать * от Сотрудника;
Выход:

Чтобы увидеть результат таблицы Employees_by_Domains, используется следующий запрос CQL, приведенный ниже.
Выбирать * от Employees_by_Domains;
Выход:

Чтобы получить значение токена, используется следующий запрос CQL, приведенный ниже.
выберите токен (имя пользователя) от Сотрудника;
Выход:
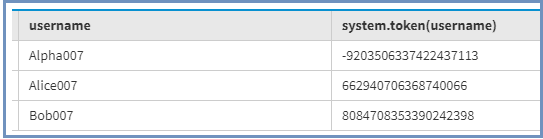
Значение каждого токена уникально для каждого имени пользователя, и токены будут распространяться по узлам. Когда мы выполним следующий запрос:
ВЫБРАТЬ * ОТ Сотрудника где имя пользователя = 'Alpha007'
Он вернет данные и выберет узел на основе этого (-9203506337422437113) значения токена.