Системный дизайн приложения Uber - Архитектура системы Uber
Очень легко просто нажать кнопку на нашем мобильном телефоне, и такси будет доступно в течение нескольких минут, когда и где мы захотим.
Uber / Ola / Lyft … использовать эти приложения и получить беспроблемную транспортную услугу действительно просто, но так ли просто создать эти гигантские приложения, над которыми в течение десяти лет работали сотни инженеров-программистов…? точно нет. Эти системы имеют гораздо более сложную архитектуру, и есть много компонентов, объединенных внутри, чтобы предоставлять услуги катания по всему миру. Разработка Uber (или OLA, или Lyft) - довольно частый вопрос в ходе собеседований при проектировании системы. Многие кандидаты боятся этого раунда больше, чем раунда кодирования, потому что они не понимают, какие темы и компромиссы им следует охватить в течение этого ограниченного периода времени. Во-первых, помните, что раунд разработки системы является чрезвычайно открытым и не существует такого понятия, как стандартный ответ. Даже по одному и тому же вопросу у вас будет совершенно другое обсуждение с разными интервьюерами.

В этом блоге мы обсудим, как разработать сервисы вызова пассажиров, такие как Uber / Ola / Lyft, но прежде чем мы продолжим, мы хотим, чтобы вы прочитали статью «Как взломать систему проектирования раунда во время собеседований?». Это даст вам представление о том, как выглядит этот раунд, что вы должны будете делать и каких ошибок следует избегать перед интервьюером.
Архитектура системы Uber
Все мы знакомы с услугами Uber. Пользователь может запросить поездку через приложение, и в течение нескольких минут водитель прибудет рядом с его / ее местоположением, чтобы отвезти их к месту назначения. Ранее Uber строился по модели « монолитной » архитектуры программного обеспечения. У них была внутренняя служба, внешняя служба и единая база данных. Они использовали Python и его фреймворки и SQLAlchemy в качестве уровня ORM для базы данных. Эта архитектура подходила для небольшого количества поездок в нескольких городах, но когда услуга начала расширяться в других городах, команда Uber столкнулась с проблемой с приложением. После 2014 года команда Uber решила перейти на « сервис-ориентированную архитектуру », и теперь Uber также занимается доставкой еды и грузов.
1. Расскажите о проблемах
Одна из основных задач в сервисе Uber - подобрать для водителя такси, что означает, что нам нужны два разных сервиса в нашей архитектуре, т. Е.
- Служба снабжения (для кабин)
- Сервис по запросу (для райдеров)
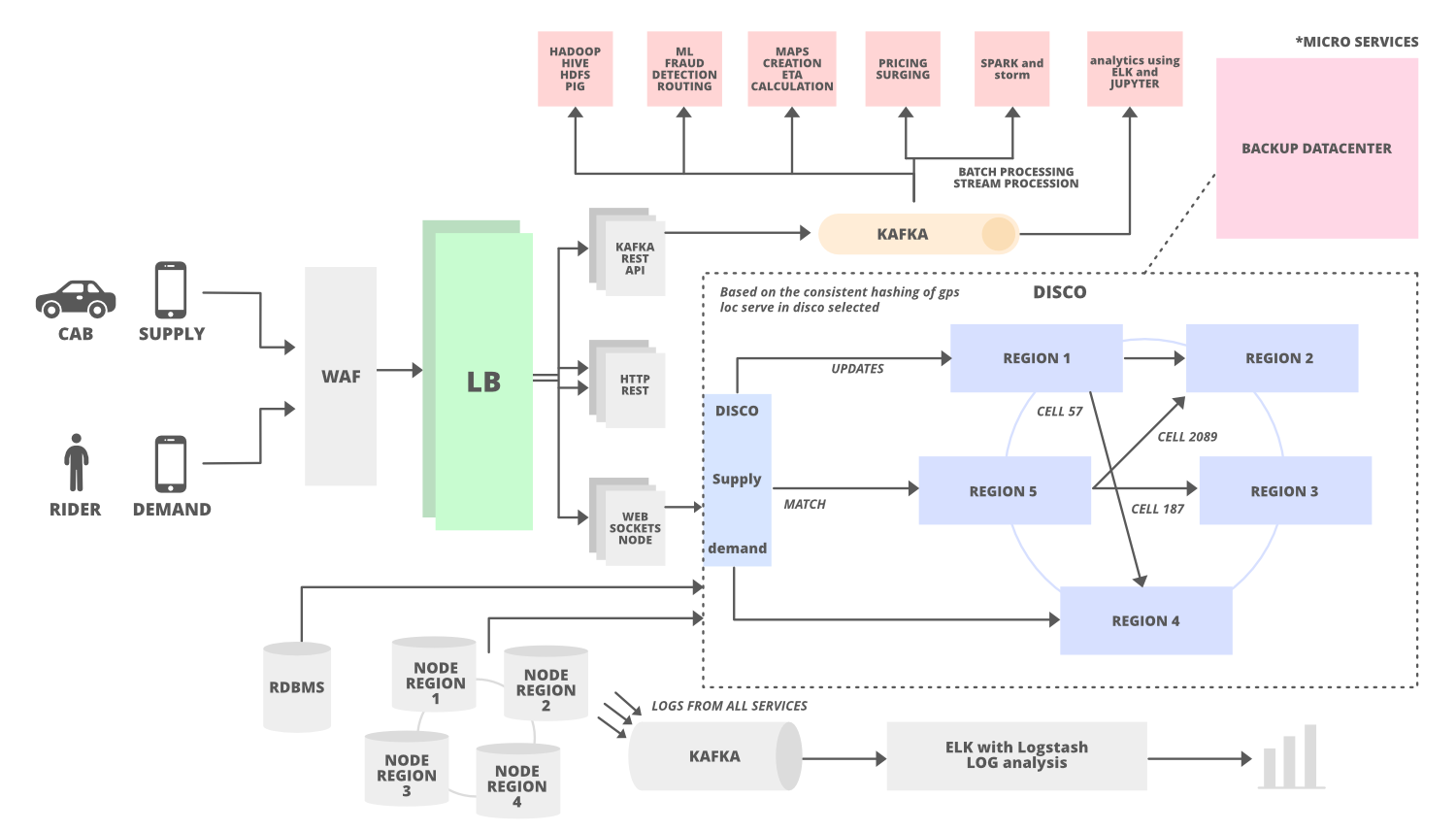
У Uber есть система диспетчеризации (оптимизация диспетчеризации / DISCO) в своей архитектуре, чтобы обеспечить соответствие предложения потребностям. Эта система диспетчеризации использует мобильные телефоны и берет на себя ответственность подбирать водителей и пассажиров (предложение к спросу).
2. Как работает система диспетчеризации?
У DISCO должны быть эти цели ...
- Уменьшите лишнее вождение.
- Минимальное время ожидания
- Минимальное общее время прибытия
Система диспетчеризации полностью работает с картами и данными о местоположении / GPS, поэтому первое, что важно, - это смоделировать наши карты и данные о местоположении.
- Земля имеет сферическую форму, поэтому сложно сделать обобщение и приближение, используя широту и долготу. Для решения этой проблемы Uber использует библиотеку Google S2 . Эта библиотека делит данные карты на крошечные ячейки (например, 3 км) и присваивает каждой ячейке уникальный идентификатор. Это простой способ распространять данные в распределенной системе и легко их хранить.
- Библиотека S2 легко обеспечивает покрытие любой заданной формы. Предположим, вы хотите выяснить все припасы, доступные в радиусе 3 км от города. Используя библиотеки S2, вы можете нарисовать круг радиусом 3 км, и он отфильтрует все ячейки с идентификаторами, лежащими в этом конкретном круге. Таким образом, вы можете легко сопоставить водителя с водителем и легко узнать количество автомобилей (запасных), доступных в конкретном регионе.
3. Служба снабжения и как она работает?
- В нашем случае такси - это службы снабжения, и они будут отслеживаться по геолокации (широте и долготе). Все активные кабины продолжают отправлять данные о местоположении на сервер каждые 4 секунды через брандмауэр веб-приложений и балансировщик нагрузки. Точное местоположение GPS отправляется в центр обработки данных через API-интерфейсы Kafka Rest после прохождения через балансировщик нагрузки. Здесь мы используем Apache Kafka в качестве концентратора данных.
- Как только последнее местоположение обновляется Kafka, оно медленно проходит через основную память соответствующих рабочих заметок.
- Также копия местоположения (конечный автомат / последнее местоположение такси) будет отправлена в базу данных и для оптимизации отправки, чтобы обновлять последнее местоположение.
- Нам также нужно отслеживать еще несколько вещей, таких как количество мест, наличие автокресла для детей, тип транспортного средства, может ли инвалидная коляска поместиться, и распределение (например, в кабине может быть четыре места, но два из них заняты. .)
4. Сервис по запросу и как он работает?
- Сервис Demand получает запрос кабины через веб-разъем и отслеживает местоположение пользователя по GPS. К нему также предъявляются другие требования, такие как количество сидений, тип автомобиля или вагон для пула.
- Спрос дает местоположение (идентификатор ячейки) и требования пользователя для предоставления и отправки запросов на кабины.
5. Как диспетчерская система подбирает водителей и гонщиков?
- Мы обсуждали, что DISCO делит карту на крошечные ячейки с уникальным идентификатором. Этот идентификатор используется в качестве ключа сегментирования в DISCO. Когда поставка получает запрос от спроса, местоположение обновляется с использованием идентификатора ячейки в качестве ключа осколка. Обязанности этих крошечных ячеек будут разделены на разные серверы, расположенные в нескольких регионах (согласованное хеширование). Например, мы можем распределить ответственность 12 крошечных ячеек между 6 разными серверами (по 2 ячейки на каждый сервер), расположенными в 6 разных регионах.
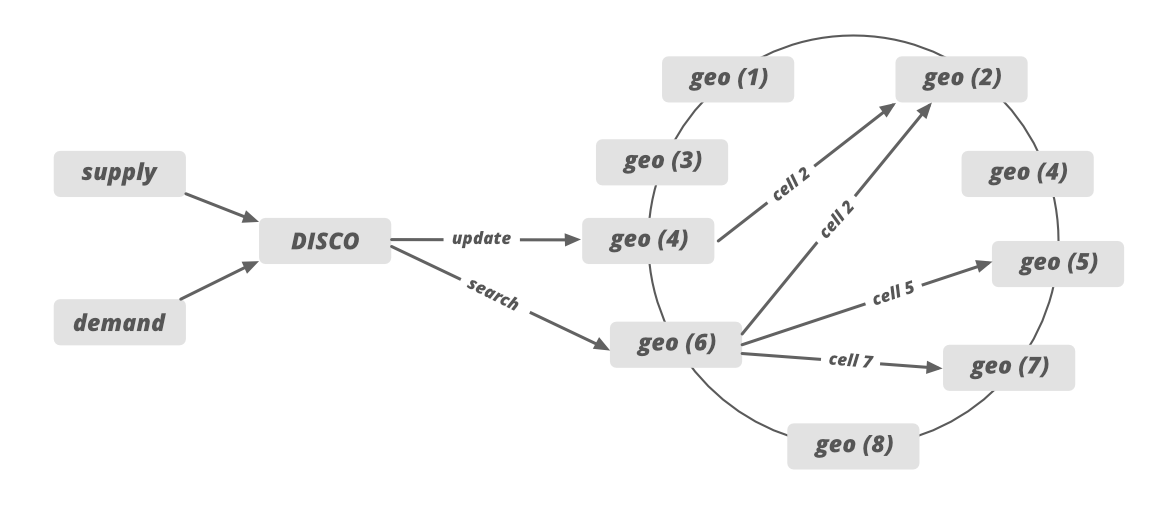
- Supply отправляет запрос на конкретный сервер на основе данных о местоположении GPS. После этого система рисует круг и отфильтровывает все близлежащие кабины, которые соответствуют требованиям водителя.
- После этого список кабин отправляется в ETA для расчета расстояния между водителем и кабиной не географически, а по системе дорог.
- Отсортированное ETA затем отправляется обратно в систему снабжения, чтобы предложить его водителю.
Если нам нужно обрабатывать трафик для нового добавленного города, мы можем увеличить количество серверов и распределить обязанности по идентификаторам ячеек недавно добавленных городов на эти серверы.
6. Как масштабировать диспетчерскую систему?
- Система диспетчеризации (включая спрос, предложение и веб-сокет) построена на NodeJS . NodeJS - это асинхронная среда, основанная на событиях, которая позволяет отправлять и получать сообщения через WebSockets в любое время.
- Uber использует кольцо с открытым исходным кодом, чтобы сделать приложение совместимым и масштабируемым для интенсивного трафика. Ring pop состоит в основном из трех частей и выполняет описанную ниже операцию для масштабирования системы диспетчеризации.
- Он поддерживает согласованное хеширование, чтобы распределить работу между рабочими. Это помогает в сегментировании приложения масштабируемым и отказоустойчивым способом.
- Ringpop использует протокол RPC (удаленный вызов процедур) для выполнения вызовов с одного сервера на другой.
- Ringpop также использует протокол членства в SWIM / протокол сплетен, который позволяет независимым работникам узнавать об ответственности друг друга. Таким образом, каждый сервер / узел знает ответственность и работу других узлов.
- Ringpop обнаруживает новые добавленные узлы в кластер и узел, который удаляется из кластера. Он равномерно распределяет нагрузки при добавлении или удалении узла.
7. Как Uber определяет регион карты?
Прежде чем начать новую операцию в новом районе, Uber включил новый регион в стек картографических технологий. В этой области карты мы определяем различные подобласти, помеченные градациями A, B, AB и C.
Уровень A: Этот субрегион отвечает за городские центры и пригородные районы. Около 90% трафика Uber покрывается в этом субрегионе, поэтому важно создать карту самого высокого качества для субрегиона A.
Уровень B: этот субрегион охватывает сельские и пригородные районы, которые менее населены и менее посещаемы клиентами Uber.
Уровень AB: объединение субрегионов уровня A и B.
Уровень C: охватывает множество коридоров автомагистралей, соединяющих различные территории Uber.
8. Как Uber строит карту?
Uber использует стороннего поставщика картографических услуг для построения карты в своем приложении. Раньше Uber использовал сервисы Mapbox, но позже Uber перешел на Google Maps API для отслеживания местоположения и расчета ETA.
1. Покрытие трассировкой: Покрытие трассировкой определяет недостающие сегменты дороги или неправильную геометрию дороги. Расчет покрытия трассировки основан на двух входных данных: тестируемых данных карты и исторических данных GPS всех поездок Uber, совершенных за определенный период времени. Он наносит эти GPS-следы на карту, сравнивая и сопоставляя их с участками дороги. Если мы обнаруживаем недостающие участки дороги (дорога не отображается) на следах GPS, мы предпринимаем некоторые шаги, чтобы исправить этот недостаток.
2. Точность предпочтительной точки доступа (посадки): мы указываем точку посадки в нашем приложении, когда бронируем такси в Uber. Пункты встречи действительно важны в Uber, особенно для крупных объектов, таких как аэропорты, университетские городки, стадионы, фабрики или компании. Мы рассчитываем расстояние между фактическим местоположением и всеми пунктами посадки и высадки, используемыми водителями.
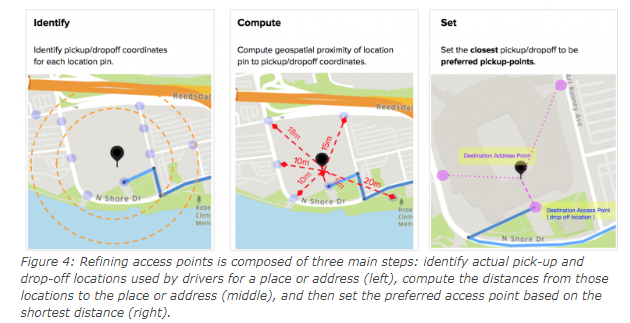
Источник изображения: https://eng.uber.com/maps-metrics-computation/
Затем рассчитывается кратчайшее расстояние (ближайшая точка посадки), и мы устанавливаем булавку на это место в качестве предпочтительной точки доступа на карте. Когда водитель запрашивает местоположение, указанное булавкой на карте, карта направляет водителя к предпочтительной точке доступа. Расчет продолжается с учетом последних фактических мест посадки и высадки, чтобы гарантировать актуальность и точность предлагаемых предпочтительных точек доступа. Uber использует машинное обучение и различные алгоритмы для определения предпочтительной точки доступа.
9. Как рассчитывается ETA?
Расчетное время прибытия - чрезвычайно важный показатель для Uber, поскольку он напрямую влияет на подбор пассажиров и прибыль. ETA рассчитывается на основе дорожной системы (не географически), и есть много факторов, участвующих в вычислении ETA (например, интенсивное движение или строительство дороги). Когда водитель запрашивает такси из какого-либо места, приложение не только определяет свободные / незанятые кабины, но также включает кабины, которые собираются закончить поездку. Возможно, что одна из кабин, которые вот-вот закончат поездку, более близка к потребностям, чем кабина, которая находится далеко от пользователя. Так много uber-автомобилей на дороге отправляют GPS-координаты каждые 4 секунды, поэтому для прогнозирования трафика мы можем использовать данные GPS-местоположения приложения водителя.
Мы можем представить всю дорожную сеть на графике для расчета расчетного времени прибытия. Мы можем использовать алгоритмы, имитирующие искусственный интеллект, или простой алгоритм Дейкстры, чтобы найти лучший маршрут на этом графике. На этом графике узлы представляют собой перекрестки (доступные кабины), а края - сегменты дороги. Мы представляем расстояние сегмента дороги или время прохождения через вес края. Мы также представляем и моделируем некоторые дополнительные факторы на нашем графике, такие как улицы с односторонним движением, стоимость поворота, ограничения поворота и ограничения скорости.
Как только структура данных определена, мы можем найти лучший маршрут, используя алгоритм поиска Дейкстры, который на сегодняшний день является одним из лучших современных алгоритмов маршрутизации. Для повышения производительности нам также необходимо использовать OSRM (Open Source Routing Machine), которая основана на иерархиях сжатия. Системам, основанным на иерархиях сжатия, требуется всего несколько миллисекунд для вычисления маршрута - путем предварительной обработки графа маршрутизации.
10. Базы данных
Uber пришлось учесть некоторые требования к базе данных для лучшего обслуживания клиентов. Эти требования…
- База данных должна быть масштабируемой по горизонтали. Вы можете линейно увеличивать емкость, добавляя больше серверов.
- Он должен иметь возможность обрабатывать много операций чтения и записи, потому что каждые 4 секунды кабины будут отправлять местоположение GPS, и это местоположение будет обновлено в базе данных.
- Система никогда не должна давать простоя для выполнения какой-либо операции. Он должен быть высокодоступным независимо от того, какую операцию вы выполняете (расширение хранилища, резервное копирование, добавление новых узлов и т. Д.).
Раньше Uber использовал СУБД PostgreSQL, но из-за проблем с масштабируемостью Uber переключился на различные базы данных. Uber использует базу данных NoSQL (без схемы), построенную поверх базы данных MySQL.
- Redis как для кеширования, так и для постановки в очередь. Некоторые из них находятся за Twemproxy (обеспечивает масштабируемость уровня кеширования). Некоторые из них находятся за специальной системой кластеризации.
- Uber использует schemaless (встроенный в MySQL), Riak и Cassandra. Schemaless - для длительного хранения данных. Riak и Cassandra удовлетворяют требованиям высокой доступности и малой задержки.
- База данных MySQL.
- Uber создает собственное распределенное хранилище столбцов, которое управляет множеством экземпляров MySQL.
11. Аналитика
Чтобы оптимизировать систему, свести к минимуму эксплуатационные расходы и улучшить качество обслуживания клиентов, uber выполняет сбор и анализ журналов. Uber использует разные инструменты и фреймворки для аналитики. Для анализа журналов Uber использует несколько кластеров Kafka. Kafka берет исторические данные вместе с данными в реальном времени. Данные архивируются в Hadoop до истечения срока их хранения в Kafka. Данные также индексируются в стеке поиска Elastic для поиска и визуализации. Эластичный поиск выполняет некоторый анализ журналов с помощью Kibana / Graphana. Некоторые из анализов, выполненных Uber с использованием различных инструментов и фреймворков,…
- Отслеживайте HTTP API
- Управлять профилем
- Собирайте отзывы и оценки
- Акции и купоны и т. Д.
- Обнаружение мошенничества
- Платежное мошенничество
- Поощрение злоупотребления со стороны водителя
- Взломанные хакерами учетные записи. Uber использует исторические данные о клиенте и некоторые методы машинного обучения для решения этой проблемы.
12. Как справиться с отказом центра обработки данных?
Отказ центра обработки данных случается не очень часто, но Uber по-прежнему поддерживает резервный центр обработки данных, чтобы обеспечить бесперебойную работу. Этот центр обработки данных включает в себя все компоненты, но Uber никогда не копирует существующие данные в резервный центр обработки данных.
Тогда как Uber справляется с отказом центра обработки данных?
Фактически он использует телефоны водителя в качестве источника данных о поездках для решения проблемы отказа центра обработки данных.
Когда приложение телефона водителя связывается с системой диспетчеризации или между ними происходит вызов API, система диспетчеризации отправляет зашифрованный дайджест состояния (для отслеживания последней информации / данных) в приложение телефона водителя. Каждый раз этот дайджест состояния будет приходить в приложение телефона водителя. В случае отказа центра обработки данных, резервный центр обработки данных (резервная DISCO) ничего не знает о поездке, поэтому он запрашивает дайджест состояния из приложения телефона водителя и обновляется с помощью информации дайджеста состояния, полученной на телефоне водителя. приложение.
Ссылка: Uber Engineering
Вниманию читателя! Не переставай учиться сейчас. Получите все важные концепции системного дизайна с отраслевыми экспертами. Присоединяйтесь к курсу проектирования систем, чтобы посещать живые занятия.