Маршрутизация запросов через Load Balancer
Что такое балансировщики нагрузки?
В случае наличия нескольких серверов входящий запрос, поступающий в систему, должен быть направлен на один из нескольких серверов. Мы должны убедиться, что каждый сервер получает одинаковое количество запросов. Запросы должны равномерно распределяться по всем серверам. Компонент, который отвечает за равномерное распределение этих входящих запросов по серверам, известен как Load Balancer . Балансировщик нагрузки действует как слой между входящими запросами, поступающими от пользователя, и несколькими серверами, присутствующими в системе.

Мы должны избегать сценариев, когда один сервер получает большую часть запросов, а остальные бездействуют. Существуют различные алгоритмы балансировки нагрузки, которые обеспечивают равномерное распределение запросов по серверам.
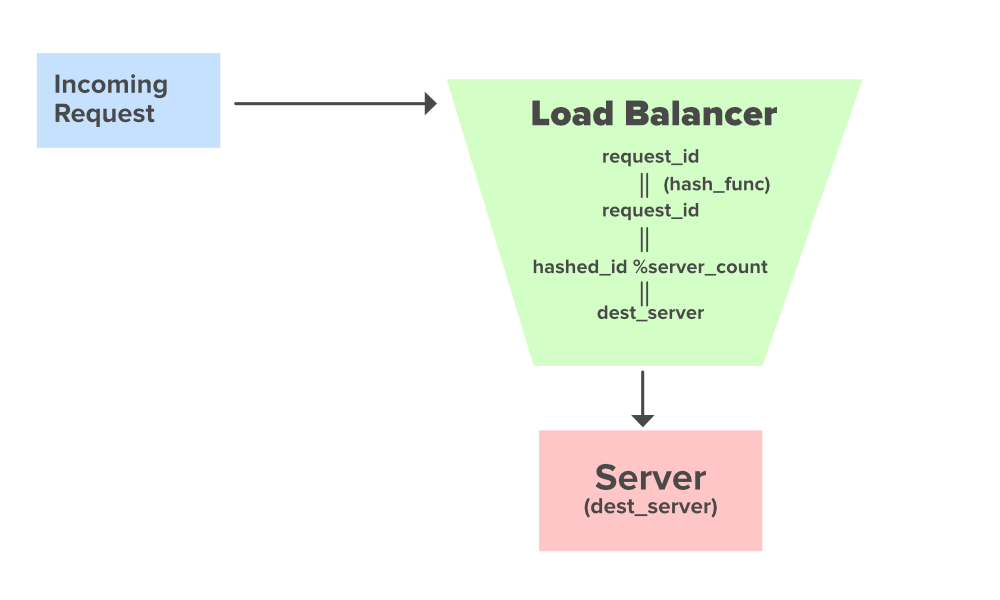
Подход к хешированию для прямых запросов от балансировщика нагрузки
Мы будем обсуждать подход к хешированию для единообразного направления запросов на несколько серверов.
Предположим, у нас есть server_count как общее количество серверов, присутствующих в системе, и load_balancer для распределения запросов между этими серверами. Запрос с идентификатором request_id поступает в систему. Перед достижением целевого сервера он направляется на load_balancer, откуда он далее направляется на свой целевой сервер.
When the request reaches the load balancer the hashing approach will provide us with the destination server where the request is to be directed.
Discussing the Approach :
- request_id : Request ID coming to get served
- hash_func : Evenly distributed Hash Function
- hashed_id : Hashed Request ID
- server_count : Number of Servers
class GFG { public static int hash_func(int request_id) { // Computing the hash request id int hashed_id = 112; return hashed_id; } public static void route_request_to_server(int dest_server) { System.out.println("Routing request to the Server ID : " + dest_server); } public static int request_id = 23; // Incoming Request ID public static int server_count = 10; // Total Number of Servers public static void main(String args[]) { int hashed_id = hash_func(request_id); // Hashing the incoming request id int dest_server = hashed_id % server_count; // Computing the destination server id route_request_to_server(dest_server); }} |
Вычисление адреса целевого сервера:
Если значение server_count равно 10, то есть у нас есть десять серверов со следующими идентификаторами серверов server_id_0, server_id_1, ………, server_id_9 .
Предположим, что значение request_id равно 23
Когда этот запрос достигает балансировщика нагрузки, хэш-функция hash_func хэширует значение идентификатора входящего запроса.
- hash_func (request_d) = hash_func (23)
Предположим, что после хеширования request_id случайным образом хешируется до определенного значения.
- hashed_id = 112
Чтобы вывести хэшированный идентификатор в диапазон количества серверов, мы можем выполнить по модулю хэшированного идентификатора количество серверов.
- dest_server = hashed_id % server_count
- dest_server = 112% 10
- dest_server = 2
Таким образом, мы можем направить этот запрос на сервер server_id_2
Таким образом, мы можем равномерно распределять все запросы, поступающие на наш балансировщик нагрузки, на все серверы. Но оптимален ли это? Да, он распределяет запросы равномерно, но что, если нам нужно увеличить количество наших серверов. Увеличение сервера изменит целевые серверы всех входящих запросов. Что, если бы мы хранили кеш, связанный с этим запросом, на целевом сервере? Теперь, когда этот запрос больше не направляется на предыдущий сервер, возможно, весь наш кеш может попасть в корзину. Считать !
Вниманию читателя! Не переставай учиться сейчас. Получите все важные концепции системного дизайна с отраслевыми экспертами. Присоединяйтесь к курсу системного дизайна, чтобы посещать живые занятия.