Системный дизайн Netflix - Полная архитектура
Сможете ли вы создать Netflix за 45 минут?
Какие??? Ты серьезно ?? (Я могу смотреть его всю ночь, но…). Невозможно объяснить даже один компонент Netflix, и вы просите меня разработать его всего за 45 минут в короткие сроки ??
Да, это то, что от вас ожидается на собеседовании по проектированию систем, если вы хотите получить работу своей мечты в крупных технологических гигантах. Проектирование Netflix - довольно частый вопрос в ходе собеседований при проектировании системы. Многие кандидаты боятся этого раунда больше, чем раунда кодирования, потому что они не понимают, какие темы и компромиссы им следует охватить в течение этого ограниченного периода времени. Во-первых, помните, что раунд разработки системы является чрезвычайно открытым и не существует такого понятия, как стандартный ответ. Даже по одному и тому же вопросу у вас будет совершенно другое обсуждение с разными интервьюерами.

В этом блоге мы обсудим, как создать веб-сайт, такой как Dropbox или Google Drive, но прежде чем мы продолжим, мы хотим, чтобы вы прочитали статью «Как взломать дизайн системы во время интервью?». Вы будете иметь представление о том, как выглядит этот раунд, что вы должны будете делать в этом раунде и каких ошибок следует избегать перед интервьюером.
Системная архитектура Netflix высокого уровня
Все мы знакомы с услугами Netflix. Он обрабатывает большие категории фильмов и телевизионного контента, и пользователи платят ежемесячную арендную плату за доступ к этому контенту. У Netflix более 180 подписчиков в 200+ странах.
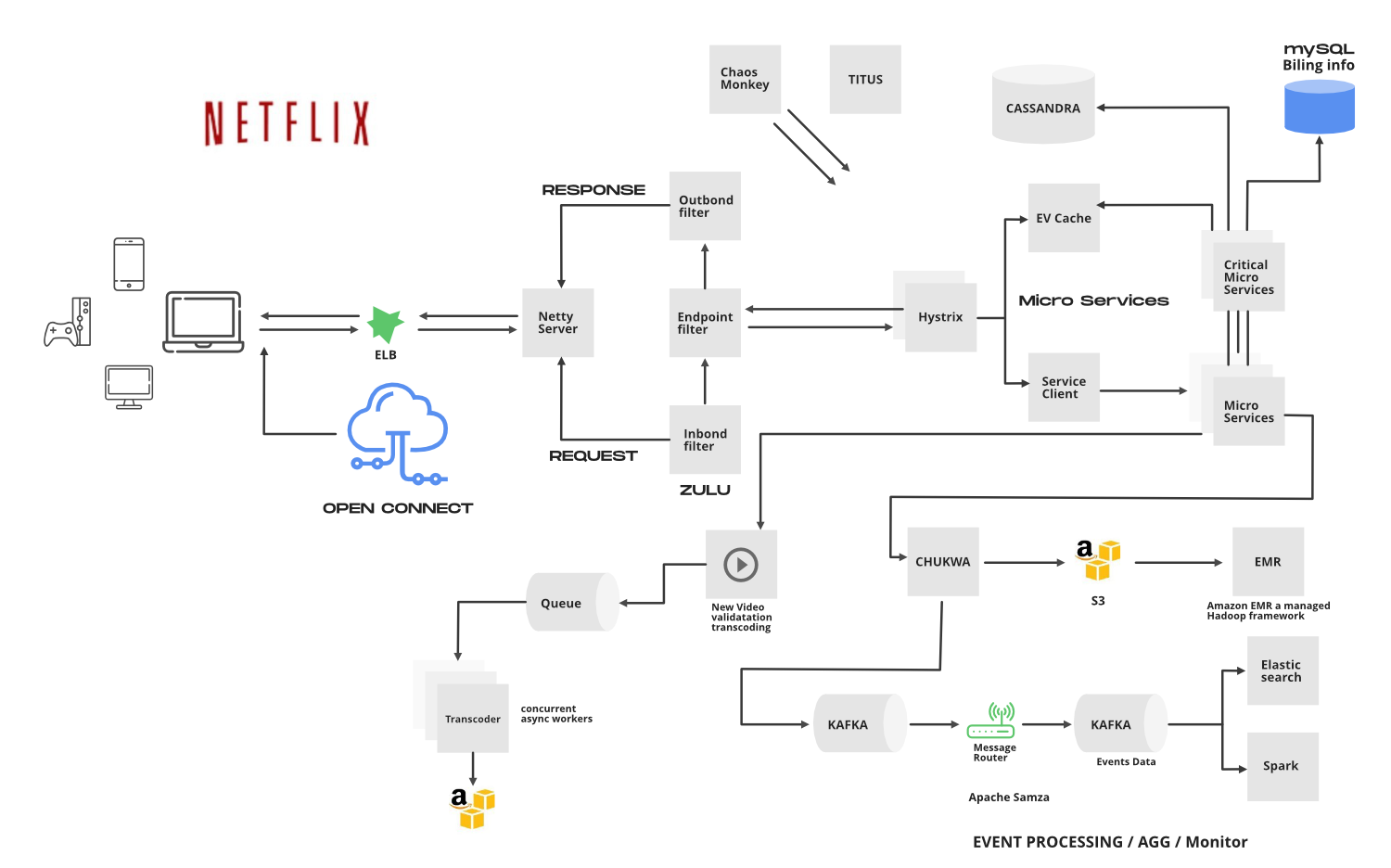
Netflix работает в двух облаках… AWS и Open Connect . Эти два облака работают вместе как основа Netflix, и оба несут большую ответственность за предоставление подписчикам лучшего видео.
Приложение состоит в основном из 3 компонентов…
- Клиент: устройство (пользовательский интерфейс), которое используется для просмотра и воспроизведения видео Netflix. Телевизор, Xbox, ноутбук или мобильный телефон и т. Д.
- OC (Open connect) или Netflix CDN: CDN - это сеть распределенных серверов в разных географических точках, а Open Connect - это собственная глобальная CDN Netflix (сеть доставки контента). Он обрабатывает все, что связано с потоковой передачей видео. Он распространяется в разных местах, и как только вы нажимаете кнопку воспроизведения, видеопоток из этого компонента отображается на вашем устройстве. Поэтому, если вы пытаетесь воспроизвести видео в Северной Америке, видео будет обслуживаться с ближайшего открытого соединения (или сервера), а не с исходного сервера (более быстрый ответ от ближайшего сервера).
- Бэкэнд (база данных) : эта часть обрабатывает все, что не связано с потоковой передачей видео (до того, как вы нажмете кнопку воспроизведения), например, загрузку нового контента, обработку видео, их распространение на серверах, расположенных в разных частях мира, и управление сетевым трафиком. За большинством процессов отвечает Amazon Web Services.
Интерфейс Netflix написан на ReactJS в основном по трем причинам: скорость запуска, производительность во время выполнения и модульность. Давайте обсудим компоненты и работу Netflix.
Как Netflix размещает фильм / видео?
Netflix получает высококачественные видео и контент от продюсерских компаний, поэтому перед тем, как передать видео пользователям, он выполняет некоторую предварительную обработку. Netflix поддерживает более 2200 устройств, и для каждого из них требуются разные разрешения и форматы. Чтобы видео можно было просматривать на разных устройствах, Netflix выполняет перекодирование или кодирование, которое включает в себя поиск ошибок и преобразование исходного видео в разные форматы и разрешения.
![]()
Netflix также оптимизирует файлы для разных скоростей сети. Качество видео хорошее, когда вы смотрите видео на высокой скорости сети. Netflix создает несколько реплик (примерно 1100–1200) для одного и того же фильма с разным разрешением. Эти реплики требуют большого количества перекодирования и предварительной обработки. Netflix разбивает исходное видео на разные более мелкие фрагменты и, используя параллельные рабочие процессы в AWS, преобразует эти фрагменты в разные форматы (например, mp4, 3gp и т. Д.) В разных разрешениях (например, 4k, 1080p и т. Д.).
После перекодирования, когда у нас есть несколько копий файлов для одного и того же фильма, эти файлы передаются на каждый сервер Open Connect, который находится в разных местах по всему миру.
Когда пользователь загружает приложение Netflix на свое устройство, сначала появляются экземпляры AWS, которые обрабатывают некоторые задачи, такие как вход в систему, рекомендации, поиск, история пользователей, домашняя страница, выставление счетов, поддержка клиентов и т. Д. После этого, когда пользователь нажимает кнопку воспроизведения на видео, Netflix анализирует скорость сети или стабильность соединения, а затем определяет лучший сервер Open Connect рядом с пользователем. В зависимости от устройства и размера экрана на устройство пользователя передается видео в нужном формате. При просмотре видео вы могли заметить, что видео выглядит пиксельным и через некоторое время возвращается к HD? это происходит из-за того, что приложение постоянно проверяет лучший сервер потокового открытого подключения и переключается между форматами (для лучшего просмотра), когда это необходимо.
Пользовательские данные, которые сохраняются в AWS, такие как поиск, просмотр, местоположение, устройство, отзывы и лайки, Netflix использует их для создания рекомендаций фильмов для пользователей, использующих модель машинного обучения или Hadoop.
Преимущества Open Connect:
- Менее дорогой
- Лучше качество
- Более масштабируемый
1. Эластичный балансировщик нагрузки
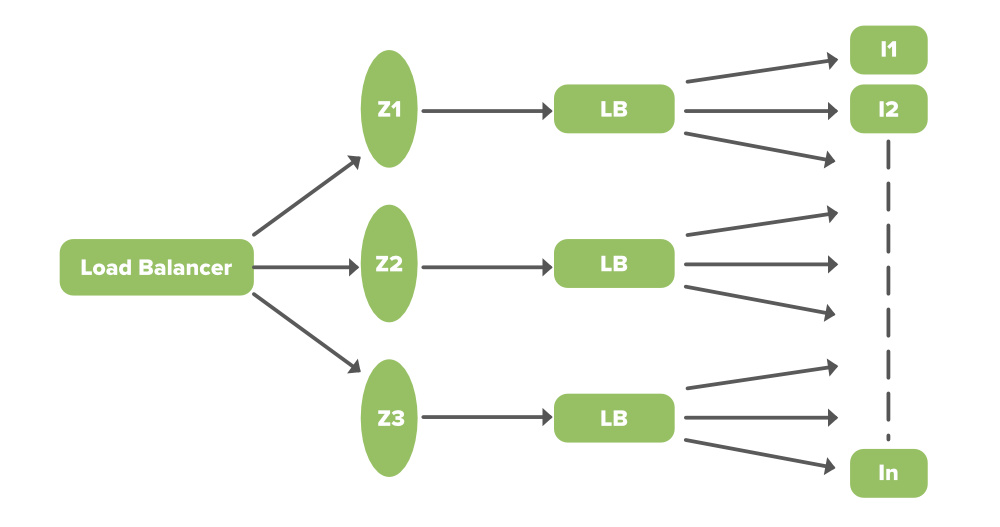
ELB в Netflix отвечает за маршрутизацию трафика к интерфейсным службам. ELB выполняет двухуровневую схему балансировки нагрузки, при которой нагрузка распределяется сначала по зонам, а затем по экземплярам (серверам).
- Первый уровень состоит из базовой балансировки циклического перебора на основе DNS. Когда запрос попадает на первую балансировку нагрузки (см. Рисунок), он балансируется по одной из зон (с использованием циклического перебора), для использования которой настроен ваш ELB.
- Второй уровень - это массив экземпляров балансировщика нагрузки, и он выполняет технику циклической балансировки для распределения запроса между экземплярами, которые находятся за ним в той же зоне.
2. ЗУУЛ
ZUUL - это сервис шлюза, который обеспечивает динамическую маршрутизацию, мониторинг, отказоустойчивость и безопасность. Он обеспечивает простую маршрутизацию на основе параметров запроса, URL-адреса, пути. Давайте разберемся, как работают разные его части…
- Сервер Netty берет на себя ответственность за работу с сетевым протоколом, веб-сервером, управлением соединениями и проксированием. Когда запрос попадет на сервер Netty, он передаст запрос входящему фильтру.
- Входящий фильтр отвечает за аутентификацию, маршрутизацию или оформление запроса. Затем он пересылает запрос фильтру конечной точки.
- Фильтр конечных точек используется для возврата статического ответа или для пересылки запроса в серверную службу (или источник, как мы его называем). Получив ответ от серверной службы, он отправляет запрос фильтру исходящей почты.
- Исходящий фильтр используется для архивирования содержимого, расчета показателей или добавления / удаления пользовательских заголовков. После этого ответ отправляется обратно на сервер Netty, а затем его получает клиент.
Преимущества:
- Вы можете создать несколько правил и сегментировать трафик , распределяя разные части трафика по разным серверам.
- Разработчики также могут проводить нагрузочное тестирование недавно развернутых кластеров на некоторых машинах. Они могут направлять некоторый существующий трафик на эти кластеры и проверять, какую нагрузку может выдержать конкретный сервер.
- Вы также можете протестировать новые услуги . Когда вы обновляете службу и хотите проверить, как она ведет себя с запросами API в реальном времени, в этом случае вы можете развернуть конкретную службу на одном сервере и перенаправить некоторую часть трафика на новую службу, чтобы проверить обслуживание в режиме реального времени.
- Мы также можем отфильтровать неверный запрос , установив собственные правила в фильтре конечной точки или брандмауэре.
3. Гистрикс
В сложной распределенной системе сервер может полагаться на ответ другого сервера. Зависимости между этими серверами могут создавать задержки, и вся система может перестать работать, если один из серверов неизбежно выйдет из строя в какой-то момент. Чтобы решить эту проблему, мы можем изолировать хост-приложение от этих внешних сбоев. Библиотека Hystrix предназначена для этой работы. Это помогает вам контролировать взаимодействие между этими распределенными сервисами, добавляя логику устойчивости к задержкам и отказоустойчивости. Hystrix делает это, изолируя точки доступа между службами, удаленной системой и сторонними библиотеками. Библиотека помогает в ..
- Остановите каскадные отказы в сложной распределенной системе.
- контроль задержки и сбоев из-за зависимостей, доступ к которым осуществляется (обычно по сети) через сторонние клиентские библиотеки.
- Быстро терпите неудачу и быстро восстанавливайтесь.
- Откат и постепенное ухудшение, когда это возможно.
- Обеспечьте мониторинг, оповещение и оперативный контроль в режиме, близком к реальному времени
- Кэширование запросов с учетом параллелизма. Автоматическое пакетирование через сворачивание запроса
4. Микросервисная архитектура Netflix
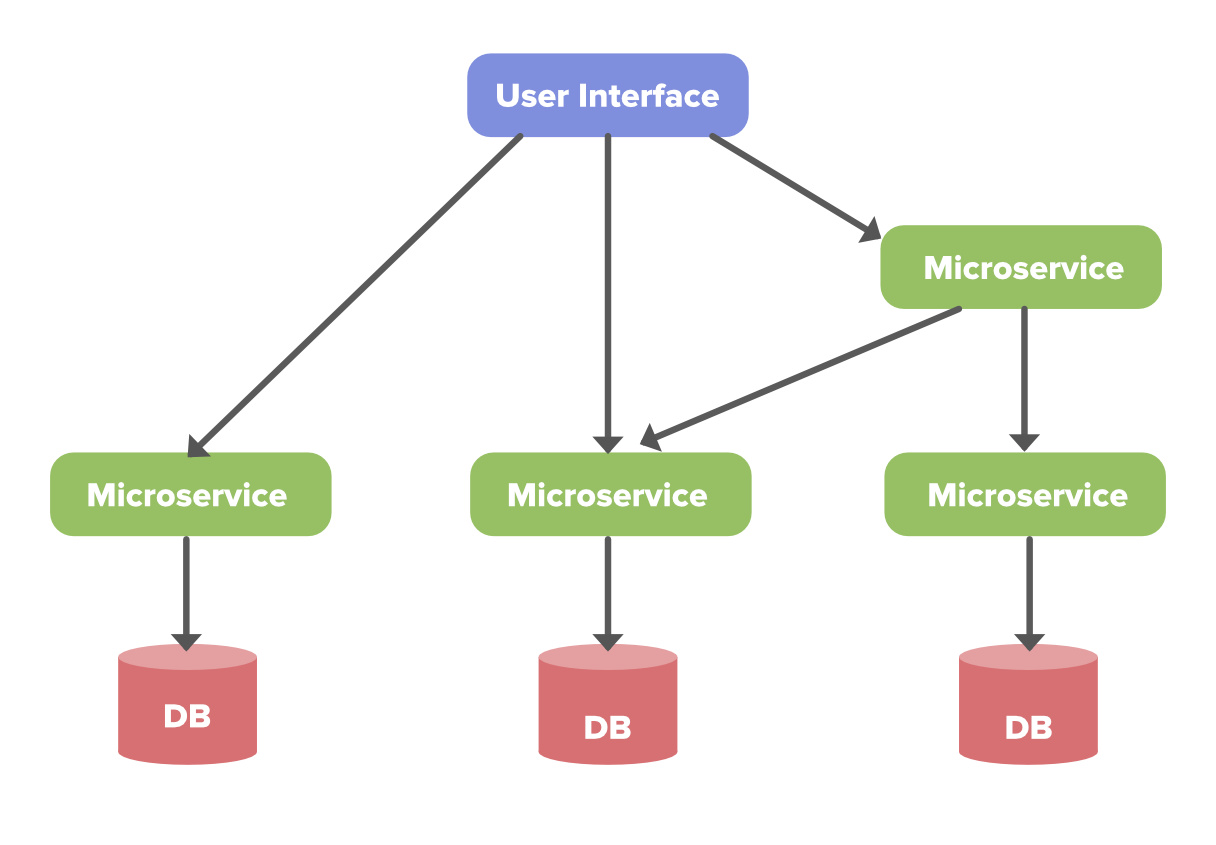
Архитектурный стиль Netflix построен как набор услуг. Это известно как архитектура микросервисов, и на ней работают все API-интерфейсы, необходимые для приложений и веб-приложений. Когда запрос поступает в конечную точку, он вызывает другие микросервисы для получения необходимых данных, и эти микросервисы также могут запрашивать данные для разных микросервисов. После этого полный ответ на запрос API отправляется обратно в конечную точку.
В микросервисной архитектуре службы должны быть независимыми друг от друга, например, служба хранения видео будет отделена от службы, ответственной за перекодирование видео. А теперь давайте разберемся, как сделать его надежным…
Как сделать микросервисную архитектуру надежной?
- Используйте Hysterix (уже объяснено)
- Отдельные критические микросервисы: мы можем выделить некоторые критически важные сервисы (или конечные точки, или API-интерфейсы) и сделать их менее зависимыми или независимыми от других сервисов. Вы также можете сделать некоторые критически важные службы зависимыми только от других надежных служб. Выбирая критически важные микросервисы, вы можете включить все основные функции, такие как поиск видео, переход к видео, нажатие и воспроизведение видео и т. Д. Таким образом вы можете сделать конечные точки высокодоступными и даже в худшем случае по крайней мере пользователь сможет делать основные вещи.
- Относитесь к серверам как к не имеющим состояния: это может показаться вам смешным, но чтобы понять эту концепцию, представьте свои серверы как стадо коров, и вам важно, сколько галлонов молока вы получаете каждый день. Если однажды вы заметите, что корова дает меньше молока, вам просто нужно заменить эту корову (производящую меньше молока) другой коровой. Вам не нужно зависеть от конкретной коровы, чтобы получить необходимое количество молока.
Мы можем связать приведенный выше пример с нашим приложением. Идея состоит в том, чтобы спроектировать службу таким образом, чтобы, если одна из конечных точек выдает ошибку или если она не обслуживает запрос своевременно, вы могли переключиться на другой сервер и выполнить свою работу. Вместо того, чтобы полагаться на конкретный сервер и сохранять состояние на этом сервере, вы можете направить запрос другому экземпляру службы и автоматически запустить новый узел для его замены. Если сервер перестанет работать, он будет заменен другим.
5. Кэш EV
В большинстве приложений часто используется некоторый объем данных. Для более быстрого ответа эти данные могут быть кэшированы на таком большом количестве конечных точек и могут быть извлечены из кеша вместо исходного сервера. Это снижает нагрузку с исходного сервера, но проблема в том, что если узел выходит из строя, весь кеш выходит из строя, и это может сказаться на производительности приложения. Чтобы решить эту проблему, Netflix создал собственный слой кэширования, который называется EV cache. Кэш EV основан на Memcached и фактически является оболочкой для Memcached.

Кластер Memcached с 3 узлами в 2 зонах доступности с клиентом в каждой зоне
Netflix развернул множество кластеров в нескольких экземплярах AWS EC2, и эти кластеры имеют так много узлов Memcached, а также клиентов кеширования. Данные распределяются по кластеру в одной зоне, и несколько копий кеша хранятся в сегментированных узлах. Каждый раз, когда запись происходит с клиентом, все узлы во всех кластерах обновляются, но когда чтение происходит с кешем, оно отправляется только в ближайший кластер (не весь кластер и узлы) и его узлы. В случае, если узел недоступен, выполните чтение из другого доступного узла. Такой подход увеличивает производительность, доступность и надежность.
6. База данных
Netflix использует две разные базы данных: MySQL (RDBMS) и Cassandra (NoSQL) для разных целей.
EC2 Развернутый MySQL
Netflix сохраняет такие данные, как платежная информация, информация о пользователях и транзакциях, в MySQL, поскольку для этого требуется соответствие ACID. Netflix имеет настройку master-master для MySQL и развертывается на больших инстансах Amazon EC2 с использованием InnoDB.
Настройка следует « протоколу синхронной репликации », где, если запись происходит на первичный главный узел, она также будет реплицирована на другой главный узел. Подтверждение будет отправлено только в том случае, если была подтверждена запись как основного, так и удаленного главных узлов. Это обеспечивает высокую доступность данных.
Netflix настроил реплику чтения для каждого узла (как локального, так и межрегионального). Это обеспечивает высокую доступность и масштабируемость.

Все запросы чтения перенаправляются на реплики чтения, и только запросы записи перенаправляются на главные узлы. В случае отказа первичного главного сервера MySQL вторичный главный узел возьмет на себя первичную роль, а запись route53 (конфигурация DNS) для базы данных будет изменена на этот новый первичный узел. Это также перенаправит запросы записи на этот новый основной главный узел.
Кассандра
Cassandra - это база данных NoSQL, которая может обрабатывать большие объемы данных, а также обрабатывать тяжелые операции записи и чтения. Когда Netflix начал привлекать больше пользователей, данные истории просмотров для каждого участника также начали увеличиваться. Это увеличивает общее количество данных истории просмотров, и Netflix становится сложно обрабатывать такой огромный объем данных. Netflix масштабировал хранилище данных истории просмотров, имея в виду две основные цели ...
- Меньший размер хранилища.
- Стабильная производительность чтения / записи по мере увеличения количества просмотров на каждого члена (соотношение записи и чтения данных истории просмотра составляет около 9: 1 в Cassandra).
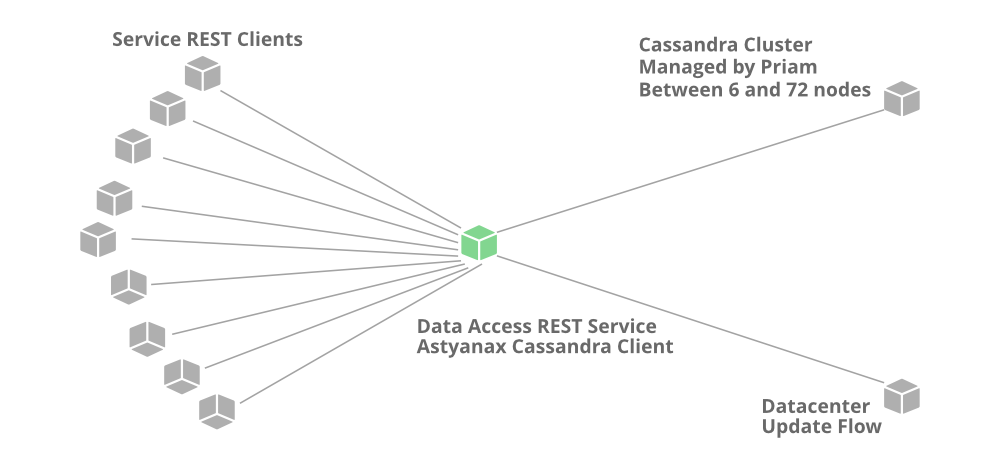
Полная денормализованная модель данных
- Более 50 кластеров Кассандры
- Более 500 узлов
- Ежедневное резервное копирование более 30 ТБ
- Самый большой кластер 72 узла.
- 1 кластер более 250K операций записи / с
Изначально история просмотров хранилась в Кассандре в одну строку. Когда количество пользователей на Netflix начало увеличиваться, размеры строк, а также общий размер данных увеличились. Это привело к увеличению объема хранилища, увеличению эксплуатационных расходов и снижению производительности приложения. Решением этой проблемы было сжатие старых строк…
Netflix разделил данные на две части…
- Журнал просмотра в реальном времени (LiveVH): этот раздел включает небольшое количество последних просмотров исторических данных пользователей с частыми обновлениями. Данные часто используются для заданий ETL и хранятся в несжатом виде.
- Сжатая история просмотров (CompressedVH): в этот раздел отнесено большое количество старых записей о просмотрах с редкими обновлениями. Данные хранятся в одном столбце для каждого ключа строки, также в сжатом виде, чтобы уменьшить занимаемое хранилище.
7. Обработка данных в Netflix с использованием Kafka и Apache Chukwa
Когда вы нажимаете на видео, Netflix начинает обрабатывать данные в различных терминах, и это занимает меньше наносекунды. Давайте обсудим, как работает конвейер развития на Netflix.
Netflix использует Kafka и Apache Chukwe для приема данных, которые создаются в другой части системы. Netflix предоставляет почти 500 БД событий, которые потребляют 1,3 ПБ в день, и 8 миллионов событий, которые потребляют 24 Гбайт / секунду в пиковое время. Эти события включают такую информацию, как…
- Журналы ошибок
- Действия пользовательского интерфейса
- События производительности
- Действия по просмотру видео
- Устранение неисправностей и диагностика событий.
Apache Chukwe - это система сбора данных с открытым исходным кодом для сбора журналов или событий из распределенной системы. Он построен на основе HDFS и фреймворка Map-reduce. Он обладает функциями масштабируемости и надежности Hadoop. Кроме того, он включает в себя множество мощных и гибких инструментов для отображения, отслеживания и анализа результатов. Chukwe собирает события из разных частей системы, а из Chukwe вы можете проводить мониторинг, анализ или использовать панель инструментов для просмотра событий. Chukwe записывает событие в формате последовательности файлов Hadoop (S3). После этого команда Big Data обрабатывает эти файлы S3 Hadoop и записывает Hive в формате данных Parquet. Этот процесс называется пакетной обработкой, которая в основном сканирует все данные с ежечасной или ежедневной частотой.
Чтобы загружать онлайн-события в EMR / S3, Chukwa также предоставляет трафик в Kafka (главные ворота для обработки данных в реальном времени). Kafka отвечает за перемещение данных с внешнего интерфейса Kafka в различные приемники: S3, Elasticsearch и вторичный Kafka. Маршрутизация этих сообщений выполняется с использованием инфраструктуры Apache Samja . Отправляемый Chukwe трафик может быть полным или отфильтрованным потоком, поэтому иногда вам, возможно, придется применить дополнительную фильтрацию к потокам Kafka. По этой причине мы считаем, что маршрутизатор переключает одну тему Kafka на другую тему Kafka.
8. Эластичный поиск
В последние годы мы наблюдаем значительный рост использования Elasticsearch в Netflix. Netflix работает примерно со 150 кластерами эластичного поиска и 3 500 хостами с экземплярами.
Netflix использует эластичный поиск для визуализации данных, поддержки клиентов и обнаружения некоторых ошибок в системе. Например, если клиент не может воспроизвести видео, руководитель службы поддержки решит эту проблему с помощью эластичного поиска. Команда воспроизведения переходит к эластичному поиску и ищет пользователя, чтобы узнать, почему видео не воспроизводится на устройстве пользователя. Они узнают всю информацию и события, происходящие для этого конкретного пользователя. Они узнают, что вызвало ошибку в видеопотоке. Администратор также использует эластичный поиск для отслеживания некоторой информации. Он также используется для отслеживания использования ресурсов и обнаружения проблем с регистрацией или входом в систему.
9. Apache Spark для рекомендаций фильмов
Netflix использует Apache Spark и машинное обучение для рекомендации фильмов. Давайте разберемся, как это работает, на примере. Когда вы загружаете первую страницу, вы видите несколько строк с фильмами разных типов. Netflix персонализирует эти данные и решает, какие строки или фильмы должны отображаться конкретному пользователю. Эти данные основаны на исторических данных и предпочтениях пользователя. Кроме того, для этого конкретного пользователя Netflix выполняет сортировку фильмов и вычисляет рейтинг релевантности (для рекомендации) этих фильмов, доступных на их платформе.
В Netflix Apache Spark используется для рекомендаций и персонализации контента. Большинство конвейеров машинного обучения работают на этих больших искровых кластерах. Эти конвейеры затем используются, среди прочего, для выбора строк, сортировки, ранжирования по релевантности заголовков и персонализации изображений.
Персонализация произведений искусства
Когда вы открываете главную страницу Netflix, вы могли заметить изображения для каждого видео… эти изображения называются изображениями заголовков (миниатюрами). Netflix требует максимального количества кликов для видео от пользователей, и эти клики зависят от изображений заголовков. Netflix должен выбрать правильное привлекательное изображение заголовка для конкретного видео. Для этого Netflix создает несколько произведений искусства для определенного фильма и случайным образом отображает эти изображения для пользователей. Для одного и того же фильма изображения могут быть разными для разных пользователей. На основе ваших предпочтений и истории просмотров Netflix предсказывает, какие фильмы вам нравятся больше всего или какие актеры вам нравятся больше всего в фильме. В соответствии с предпочтениями пользователей изображения будут отображаться им.
Например, предположим, что вы видите 9 различных изображений для вашего любимого фильма «Охота за доброй волей» в три ряда (если вам нравятся комедии, то будут показаны изображения Робина Уильямса для этого фильма. Если вам нравятся романтические фильмы, Netflix покажет вам изображение Мэтта. Дэймон и Минни Драйвер). Теперь Netflix подсчитывает количество кликов, полученных определенным изображением. Если щелчки для центрального изображения фильма были 1 500 раз, а для других изображений было меньше щелчков, Netflix навсегда сделает центральное изображение заголовком для фильма «Добрая воля охота». Это называется управляемым данными, и Netflix выполняет анализ данных с помощью этого подхода. Чтобы принять правильное решение, данные рассчитываются на основе количества просмотров, связанных с каждой картинкой.
Система видео рекомендаций
Если пользователь хочет найти какой-либо контент или видео на Netflix, система рекомендаций Netflix помогает пользователям найти свои любимые фильмы или видео. Чтобы создать эту систему рекомендаций, Netflix должен прогнозировать интерес пользователей и собирать различные типы данных от пользователей, такие как…
- Взаимодействие пользователя с сервисом (просмотр истории и оценка пользователем других заголовков)
- Другие участники со схожими вкусами и предпочтениями.
- Информация метаданных из ранее просмотренных видео для пользователя, такая как названия, жанр, категории, актеры, год выпуска и т. Д.
- Устройство пользователя, в какое время пользователь более активен и как долго он активен.
Netflix использует два разных алгоритма для построения системы рекомендаций ...
1. Совместная фильтрация . Идея этой фильтрации заключается в том, что если у двух пользователей схожая история рейтингов, они будут вести себя одинаково в будущем. Например, представьте, что есть два человека. Одному человеку фильм понравился, и он дал ему хорошую оценку. Теперь есть большая вероятность, что у другого человека также будет похожий образец, и он / она будет делать то же самое, что и первый человек.
2. Контентная фильтрация . Идея состоит в том, чтобы отфильтровать те видео, которые похожи на видео, которые ранее нравились пользователю. Контентная фильтрация сильно зависит от информации о продуктах, такой как название фильма, год выпуска, актеры, жанр. Поэтому для реализации этой фильтрации важно знать информацию, описывающую каждый элемент, и какой-то профиль пользователя, описывающий, что нравится пользователю, также желателен.
Вниманию читателя! Не переставай учиться сейчас. Получите все важные концепции системного дизайна с отраслевыми экспертами. Присоединяйтесь к курсу проектирования систем, чтобы посещать живые занятия.