Реализуйте свою собственную модель word2vec (skip-gram) на Python
Предварительное условие: Знакомство с word2vec
Обработка естественного языка (NLP) - это подраздел компьютерных наук и искусственного интеллекта, связанный с взаимодействием между компьютерами и человеческими (естественными) языками.
В методах НЛП мы сопоставляем слова и фразы (из словаря или корпуса) векторам чисел, чтобы упростить обработку. Эти типы методов языкового моделирования называются встраиванием слов .
В 2013 году Google анонсировал word2vec , группу связанных моделей, которые используются для встраивания слов.
Давайте реализуем нашу собственную модель скип-грамм (на Python), выведя уравнения обратного распространения ошибки нашей нейронной сети.
В архитектуре пропуска грамматики word2vec вводом является центральное слово, а предсказания - контекстные слова. Рассмотрим массив слов W, если W (i) является входом (центральное слово), то W (i-2), W (i-1), W (i + 1) и W (i + 2) являются контекстные слова, если размер скользящего окна равен 2.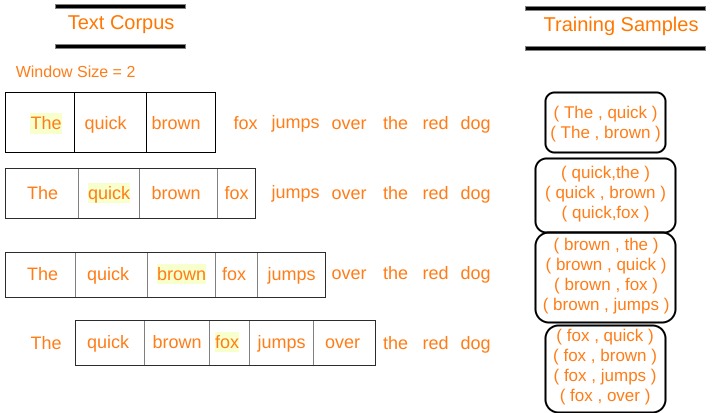
Определим несколько переменных: V Количество уникальных слов в нашем своде текста (V ocabulary) x Входной слой (одна горячая кодировка нашего входного слова). N Количество нейронов в скрытом слое нейронной сети W Веса между входным слоем и скрытым слоем W ' Веса между скрытым слоем и выходным слоем y Выходной слой softmax, имеющий вероятности каждого слова в нашем словаре.
Наша архитектура нейронной сети определена, теперь давайте сделаем математику, чтобы вывести уравнения, необходимые для градиентного спуска.
Прямое распространение:
Умножение одного горячего кодирования центрального слова (обозначенного x ) на первую матрицу весов W для получения матрицы h скрытого слоя (размера N x 1). 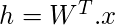
(Vx1) (NxV) (Vx1)
Теперь мы умножаем вектор скрытого слоя h на вторую весовую матрицу W ', чтобы получить новую матрицу u
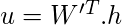
(Vx1) (VxN) (Nx1)
Обратите внимание, что мы должны применить softmax> к слою u, чтобы получить наш выходной слой y .
Пусть u j - j- й нейрон слоя u
Пусть w j будет j- м словом в нашем словаре, где j - любой индекс
Пусть V w j будет j- м столбцом матрицы W ' (столбец, соответствующий слову w j )
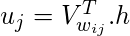
(1 × 1) (1xN) (Nx1)
у = softmax (u)
y j = softmax (u j )
y j обозначает вероятность того, что w j является контекстным словом
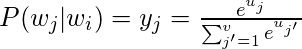
P (w j | w i ) - это вероятность того, что w j является контекстным словом, если w i является входным словом.
Таким образом, наша цель - максимизировать P (w j * | w i ) , где j * представляет индексы контекстных слов
Ясно, что мы хотим максимизировать 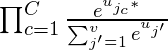
где j * c - словарные индексы контекстных слов. Контекстные слова варьируются от c = 1, 2, 3..C
Давайте возьмем отрицательную логарифмическую вероятность этой функции, чтобы получить нашу функцию потерь , которую мы хотим минимизировать. 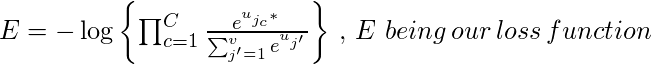
Пусть t будет фактическим выходным вектором наших обучающих данных для определенного центрального слова. Он будет содержать единицы в позициях контекстных слов и нули во всех остальных местах. t j * c - это единицы контекстных слов.
Мы можем умножать 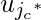 с участием
с участием 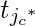
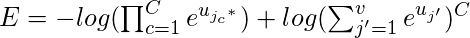
Решая это уравнение, мы получаем нашу функцию потерь как -
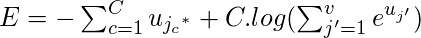
Обратное распространение:
Настраиваемые параметры находятся в матрицах W и W ', следовательно, мы должны найти частные производные нашей функции потерь по W и W', чтобы применить алгоритм градиентного спуска.
Мы должны найти 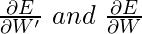
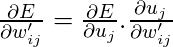
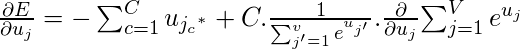
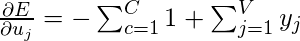
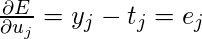
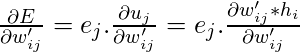
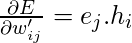
Сейчас, в поисках 
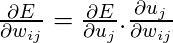
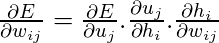
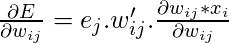
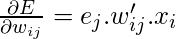
Ниже представлена реализация:
import numpy as npstring importfrom nltk.corpus import stopwords def softmax(x): """Compute softmax values for each sets of scores in x.""" e_x = np.exp(x - np. max (x)) return e_x / e_x. sum () class word2vec( object ): def __init__( self ): self .N = 10 self .X_train = [] self .y_train = [] self .window_size = 2 self .alpha = 0.001 self .words = [] self .word_index = {} def initialize( self ,V,data): self .V = V self .W = np.random.uniform( - 0.8 , 0.8 , ( self .V, self .N)) self .W1 = np.random.uniform( - 0.8 , 0.8 , ( self .N, self .V)) self .words = data for i in range ( len (data)): self .word_index[data[i]] = i def feed_forward( self ,X): self .h = np.dot( self .WT,X).reshape( self .N, 1 ) self .u = np.dot( self .W1.T, self .h) #print(self.u) self .y = softmax( self .u) return self .y def backpropagate( self ,x,t): e = self .y - np.asarray(t).reshape( self .V, 1 ) # e.shape is V x 1 dLdW1 = np.dot( self .h,eT) X = np.array(x).reshape( self .V, 1 ) dLdW = np.dot(X, np.dot( self .W1,e).T) self .W1 = self .W1 - self .alpha * dLdW1 self .W = self .W - self .alpha * dLdW def train( self ,epochs): for x in range ( 1 ,epochs): self .loss = 0 for j in range ( len ( self .X_train)): self .feed_forward( self .X_train[j]) self .backpropagate( self .X_train[j], self .y_train[j]) C = 0 for m in range ( self .V): if ( self .y_train[j][m]): self .loss + = - 1 * self .u[m][ 0 ] C + = 1 self .loss + = C * np.log(np. sum (np.exp( self .u))) print ( "epoch " ,x, " loss = " , self .loss) self .alpha * = 1 / ( ( 1 + self .alpha * x) ) def predict( self ,word,number_of_predictions): if word in self .words: index = self .word_index[word] X = [ 0 for i in range ( self .V)] X[index] = 1 prediction = self .feed_forward(X) output = {} for i in range ( self .V): output[prediction[i][ 0 ]] = i top_context_words = [] for k in sorted (output,reverse = True ): top_context_words.append( self .words[output[k]]) if ( len (top_context_words)> = number_of_predictions): break return top_context_words else : print ( "Word not found in dicitonary" ) |
def preprocessing(corpus): stop_words = set (stopwords.words( 'english' )) training_data = [] sentences = corpus.split( "." ) for i in range ( len (sentences)): sentences[i] = sentences[i].strip() sentence = sentences[i].split() x = [word.strip(string.punctuation) for word in sentence if word not in stop_words] x = [word.lower() for word in x] training_data.append(x) return training_data def prepare_data_for_training(sentences,w2v): data = {} for sentence in sentences: for word in sentence: if word not in data: data[word] = 1 else : data[word] + = 1 V = len (data) data = sorted ( list (data.keys())) vocab = {} for i in range ( len (data)): vocab[data[i]] = i #for i in range(len(words)): for sentence in sentences: for i in range ( len (sentence)): center_word = [ 0 for x in range (V)] center_word[vocab[sentence[i]]] = 1 context = [ 0 for x in range (V)] for j in range (i - w2v.window_size,i + w2v.window_size): if i! = j and j> = 0 and j< len (sentence): context[vocab[sentence[j]]] + = 1 w2v.X_train.append(center_word) w2v.y_train.append(context) w2v.initialize(V,data) return w2v.X_train,w2v.y_train |
corpus = ""corpus + = "The earth revolves around the sun. The moon revolves around the earth"epochs = 1000 training_data = preprocessing(corpus)w2v = word2vec() prepare_data_for_training(training_data,w2v)w2v.train(epochs) print (w2v.predict( "around" , 3 )) |
Выход: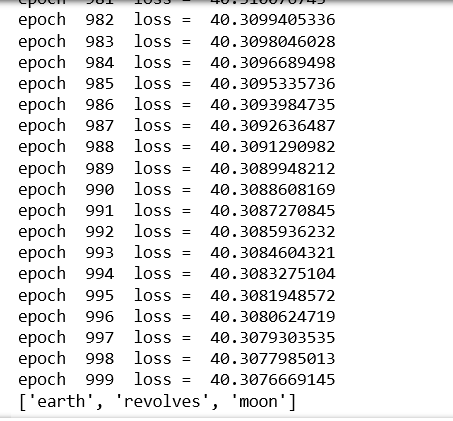
Внимание компьютерщик! Укрепите свои основы с помощью базового курса программирования Python и изучите основы.
Для начала подготовьтесь к собеседованию. Расширьте свои концепции структур данных с помощью курса Python DS. А чтобы начать свое путешествие по машинному обучению, присоединяйтесь к курсу Машинное обучение - базовый уровень.