Разделение большого файла на отдельные модули в C / C ++, Java и Python
Если вы когда-либо хотели написать большую программу или программное обеспечение, наиболее распространенная ошибка новичков - это сразу же вмешаться и попытаться записать весь необходимый код в одну программу, а затем попытаться отладить или расширить ее позже.
Такой подход обречен на провал и обычно требует переписывания с нуля.
Итак, чтобы справиться с этим сценарием, мы можем попытаться разделить проблему на несколько подзадач, а затем попытаться решить ее одну за другой.
Это не только упрощает нашу задачу, но и позволяет нам достичь абстракции от высокоуровневого программиста, а также способствует повторному использованию кода.
Если вы проверите любой проект с открытым исходным кодом на GitHub, GitLab или на любом другом подобном сайте, мы сможем увидеть, как большая программа «децентрализована» на множество подмодулей, где каждый отдельный модуль вносит свой вклад в конкретную критическую функцию программа, а также различные члены Сообщества с открытым исходным кодом собираются вместе, чтобы внести свой вклад или поддержать такой файл (ы) или репозиторий.
Теперь большой вопрос заключается в том, как «сломать» не теоретически, а ПРОГРАММАТИЧЕСКИ .
Мы увидим несколько различных типов таких разделений в популярных языках, таких как C / C ++, Python и Java.
Перейти к C / C ++
Перейти к Python
Перейти на Java
C / C ++
В иллюстративных целях
Предположим, у нас есть все основные вставки связанного списка внутри одной программы. Поскольку существует множество методов (функций), мы не можем загромождать программу, написав все определения методов над обязательной основной функцией. Но даже если бы мы это сделали, может возникнуть проблема с упорядочением методов, когда один метод должен быть перед другим и так далее.
Итак, чтобы решить эту проблему, мы можем объявить все прототипы в начале программы, за ними следует основной метод, а под ним мы можем определить их в любом конкретном порядке:
Программа:
FullLinkedList.c
// Full Linked List Insertions #include <stdio.h>#include <stdlib.h> //--------------------------------// Declarations - START://-------------------------------- struct Node;struct Node* create_node( data); intvoid b_insert( struct Node** head, int data);void n_insert( struct Node** head, int data, int pos);void e_insert( struct Node** head, int data);void display( struct Node* temp); //--------------------------------// Declarations - END://-------------------------------- int main(){ struct Node* head = NULL; int ch, data, pos; printf ( "Linked List:
" ); while (1) { printf ( "1.Insert at Beginning" ); printf ( "
2.Insert at Nth Position" ); printf ( "
3.Insert At Ending" ); printf ( "
4.Display" ); printf ( "
0.Exit" ); printf ( "
Enter your choice: " ); scanf ( "%d" , &ch); switch (ch) { case 1: printf ( "Enter the data: " ); scanf ( "%d" , &data); b_insert(&head, data); break ; case 2: printf ( "Enter the data: " ); scanf ( "%d" , &data); printf ( "Enter the Position: " ); scanf ( "%d" , &pos); n_insert(&head, data, pos); break ; case 3: printf ( "Enter the data: " ); scanf ( "%d" , &data); e_insert(&head, data); break ; case 4: display(head); break ; case 0: return 0; default : printf ( "Wrong Choice" ); } }} //--------------------------------// Definitions - START://-------------------------------- struct Node { data; int struct Node* next;}; struct Node* create_node( data) int{ struct Node* temp = ( struct Node*) malloc ( sizeof ( struct Node)); temp->data = data; temp->next = NULL; return temp;} void b_insert( struct Node** head, int data){ struct Node* new_node = create_node(data); new_node->next = *head; *head = new_node;} void n_insert( struct Node** head, int data, int pos){ if (*head == NULL) { b_insert(head, data); return ; } struct Node* new_node = create_node(data); struct Node* temp = *head; for ( int i = 0; i < pos - 2; ++i) temp = temp->next; new_node->next = temp->next; temp->next = new_node;} void e_insert( struct Node** head, int data){ if (*head == NULL) { b_insert(head, data); return ; } struct Node* temp = *head; while (temp->next != NULL) temp = temp->next; struct Node* new_node = create_node(data); temp->next = new_node;} void display( struct Node* temp){ printf ( "The elements are:
" ); while (temp != NULL) { printf ( "%d " , temp->data); temp = temp->next; } printf ( "
" );} //--------------------------------// Definitions - END//-------------------------------- |
Компиляция кода: мы можем скомпилировать указанную выше программу следующим образом:
gcc connectedlist.c -o связанный список
И это работает!
Основные проблемы в приведенном выше коде:
Мы уже можем видеть основные проблемы с программой, с кодом совсем не просто работать, ни индивидуально, ни в группе.
Если кто-то захочет работать с вышеуказанной программой, то некоторые из многих проблем, с которыми сталкивается этот человек, следующие:
- Необходимо просмотреть полный исходный файл, чтобы улучшить или расширить некоторые функции.
- Невозможно легко повторно использовать программу в качестве основы для других проектов.
- Код очень загроможден и совсем не привлекателен, что затрудняет навигацию по коду.
В случае группового проекта или больших программ вышеупомянутый подход гарантированно увеличит общие затраты, энергию и количество отказов.
Правильный подход:
Мы видим, что эти строки начинаются в каждой программе C / C ++, которая начинается с «#include».
Это означает включение всех функций, объявленных в заголовке «библиотеки» (файлы .h) и определенных, возможно, в файлах library.c / cpp.
Эти строки обрабатываются препроцессором во время компиляции.
Мы можем вручную попробовать создать такую библиотеку для собственных целей.
Важно помнить:
- Файлы «.h» содержат только объявления прототипов (например, функции, структуры) и глобальные переменные.
- Файлы «.c / .cpp» содержат реальную реализацию (определения объявления в файлах заголовков)
- При компиляции всех исходных файлов вместе убедитесь, что нет нескольких определений одних и тех же функций, переменных и т. Д. Для одного и того же проекта. (ОЧЕНЬ ВАЖНО)
- Используйте статические функции, чтобы ограничиться файлом, в котором они объявлены.
- Используйте ключевое слово extern, чтобы использовать переменные, которые ссылаются на внешние файлы.
- При использовании C ++ будьте осторожны с пространствами имен, всегда используйте namespace_name :: function (), чтобы избежать коллизий.
Разделение программы на более мелкие коды:
Заглянув в приведенную выше программу, мы можем увидеть, как эту большую программу можно разделить на подходящие небольшие части, а затем легко работать с ними.
Вышеупомянутая программа имеет по существу 2 основные функции:
1) Создавать, вставлять и хранить данные в узлах.
2) Отобразите узлы
Таким образом, я могу разделить программу таким образом, чтобы:
1) Main File -> Driver program, Nice Wrapper of the Insertion Modules и где мы используем дополнительные файлы.
2) Вставить -> Настоящая реализация находится здесь.
Принимая во внимание упомянутые важные моменты, программа разделена на:
linkedlist.c -> Contains Driver Program
insert.c -> Contains Code for insertionlinkedlist.h -> Contains the necessary Node declarations
insert.h -> Contains the necessary Node Insertion Declarations
В каждом файле заголовка мы начинаем с:
#ifndef FILENAME_H #define FILENAME_H Заявления ... #endif
Причина, по которой мы пишем наши объявления между #ifndef, #define и #endif, заключается в том, чтобы предотвратить многократное объявление идентификаторов, таких как типы данных, переменные и т. Д., Когда один и тот же файл заголовка вызывается в новом файле, принадлежащем тому же проекту.
Для этой примерной программы:
insert.h -> Содержит объявление вставки узла, а также объявление самого узла.
Следует помнить одну очень важную вещь: компилятор может видеть объявления в файле заголовка, но если вы попытаетесь написать код INVOLVING, определение объявления, объявленного в другом месте, это приведет к ошибке, поскольку компилятор компилирует каждый файл .c индивидуально перед переходом к этапу связывания. .
connectedlist.h -> Вспомогательный файл, содержащий объявления Node и его Display, которые должны быть включены для файлов, которые их используют.
insert.c -> Включите объявление узла через #include «связанный список.h», который содержит объявление, а также все другие определения методов, объявленных в insert.h.
connectedlist.c -> Simple Wrapper, содержащий бесконечный цикл, предлагающий пользователю вставить целочисленные данные в требуемую позицию (позиции), а также метод, отображающий список.
И последнее, что следует иметь в виду, это то, что бездумное включение файлов друг в друга может привести к многократным переопределениям и ошибкам.
Помня вышесказанное, следует тщательно разделить на подходящие подпрограммы.
connectedlist.h
// linkedlist.h #ifndef LINKED_LIST_H#define LINKED_LIST_H struct Node { data; int struct Node* next;}; void display( struct Node* temp); #endif |
insert.h
// insert.h #ifndef INSERT_H#define INSERT_H struct Node;struct Node* create_node( data); intvoid b_insert( struct Node** head, int data);void n_insert( struct Node** head, int data, int pos);void e_insert( struct Node** head, int data); #endif |
insert.c
// insert.c #include "linkedlist.h"// "" to tell the preprocessor to look// into the current directory and// standard library files later. #include <stdlib.h> struct Node* create_node( data) int{ struct Node* temp = ( struct Node*) malloc ( sizeof ( struct Node)); temp->data = data; temp->next = NULL; return temp;} void b_insert( struct Node** head, int data){ struct Node* new_node = create_node(data); new_node->next = *head; *head = new_node;} void n_insert( struct Node** head, int data, int pos){ if (*head == NULL) { b_insert(head, data); return ; } struct Node* new_node = create_node(data); struct Node* temp = *head; for ( int i = 0; i < pos - 2; ++i) temp = temp->next; new_node->next = temp->next; temp->next = new_node;} void e_insert( struct Node** head, int data){ if (*head == NULL) { b_insert(head, data); return ; } struct Node* temp = *head; while (temp->next != NULL) temp = temp->next; struct Node* new_node = create_node(data); temp->next = new_node;} |
connectedlist.c
// linkedlist.c// Driver Program #include "insert.h"#include "linkedlist.h"#include <stdio.h> void display( struct Node* temp){ printf ( "The elements are:
" ); while (temp != NULL) { printf ( "%d " , temp->data); temp = temp->next; } printf ( "
" );} int main(){ struct Node* head = NULL; int ch, data, pos; printf ( "Linked List:
" ); while (1) { printf ( "1.Insert at Beginning" ); printf ( "
2.Insert at Nth Position" ); printf ( "
3.Insert At Ending" ); printf ( "
4.Display" ); printf ( "
0.Exit" ); printf ( "
Enter your choice: " ); scanf ( "%d" , &ch); switch (ch) { case 1: printf ( "Enter the data: " ); scanf ( "%d" , &data); b_insert(&head, data); break ; case 2: printf ( "Enter the data: " ); scanf ( "%d" , &data); printf ( "Enter the Position: " ); scanf ( "%d" , &pos); n_insert(&head, data, pos); break ; case 3: printf ( "Enter the data: " ); scanf ( "%d" , &data); e_insert(&head, data); break ; case 4: display(head); break ; case 0: return 0; default : printf ( "Wrong Choice" ); } }} |
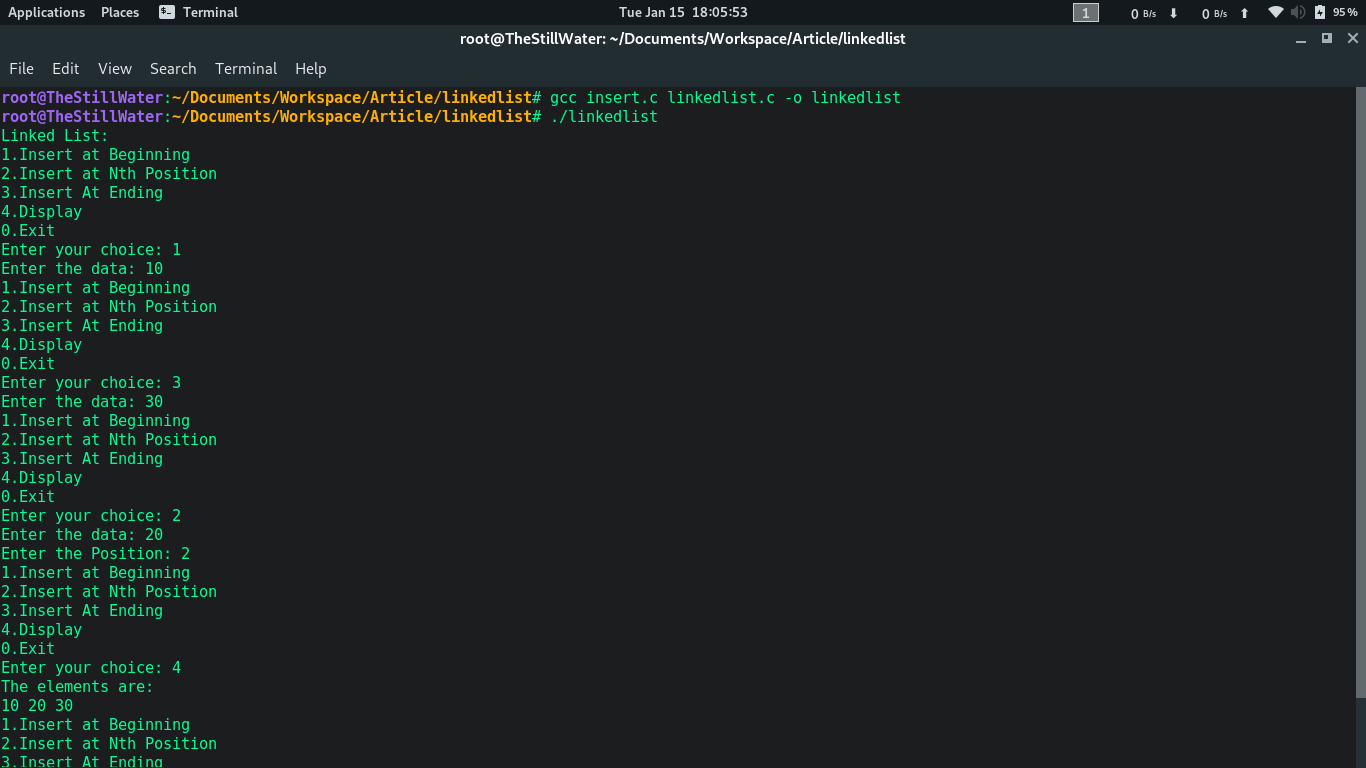
Наконец, мы сохраняем их все и компилируем следующим образом.
gcc insert.c linkedlist.c -o linkedlistВуаля, он успешно скомпилирован, давайте на всякий случай сделаем быструю проверку работоспособности:
Выход:
Это остается в основном таким же для C ++, за исключением обычных изменений языковых функций / реализаций.
Python
Здесь это не так уж и сложно. Обычно первое, что нужно сделать, - это создать виртуальную среду . Это необходимо для предотвращения взлома множества скриптов из-за различных зависимостей версий и тому подобного. Например, вы можете использовать версию 1.0 какого-либо модуля для одного проекта, но в этой последней версии устарела функция, доступная в 0.9, и вы предпочитаете использовать старую версию для этого нового проекта или просто хотите обновить библиотеки, не нарушая старые и существующие проекты. Решение представляет собой изолированную среду для каждого отдельного проекта / сценария (ов).
Как установить Virtual Env:
Используйте pip или pip3 для установки virtualenv, если он еще не установлен:
pip install virtualenvНастройка изолированной среды для каждого проекта / скрипта:
Затем перейдите в какой-либо каталог для хранения ваших проектов, а затем:
virtualenv app_Name # (Or)
virtualenv -p /path/to/py3(or)2.7 app_name # For specific interpreter dependency
source app_name/bin/activate # Start Working
deactivate # To Quit
Теперь вы можете использовать pip для установки всех желаемых модулей, и они действуют как автономные для этого изолированного проекта, и вам не нужно беспокоиться о сбое общесистемного скрипта. например: с активированным виртуальным env и источником,
pip install pip install pandas == 0.22.0
Важно создать явный пустой файл с именем:
__init__.pyЭто делается для того, чтобы рассматривать каталог как содержащий пакет (ы) и получать доступ к подмодулям внутри каталога. Если вы не создадите такой файл, Python не будет явно искать подмодули внутри каталога проекта, и любая попытка получить к ним доступ приведет к ошибке.
Импорт ранее сохраненных модулей в новые файлы:
Теперь вы можете начать импорт ранее сохраненных модулей в новые файлы одним из способов:
import module
from module import submodule # (or) from module.submodule import subsubmodule1, subsubmodule2
from module import * # (or) from module.submodule import *
Первая строка позволяет вам получить доступ к ссылкам через module.feature () или module.variable.
Вторая строка позволяет напрямую обращаться к указанному конкретному модулю. например: функция ()
Третья строка позволяет получить прямой доступ ко всем ссылкам. например: feature1 (), feature2 () и т. д.
Пример одного загроможденного файла:
Point.py
# point.py class Point: def __init__( self ): self .x = int ( input ( "Enter the x-coordinate: " )) self .y = int ( input ( "Enter the y-coordinate: " )) distance ( def self , other): return (( self .x - other.x) * * 2 + ( self .y - other.y) * * 2 ) * * 0.5 if __name__ = = "__main__" : print ( "Point 1" ) p1 = Point () print ( "
Point 2" ) p2 = Point () РЕКОМЕНДУЕМЫЕ СТАТЬИ |