Q-Learning на Python
Предварительные требования: обучение с подкреплением
Вкратце обучение с подкреплением - это парадигма процесса обучения, в которой обучающийся агент со временем учится оптимально вести себя в определенной среде, постоянно взаимодействуя с ней. В процессе обучения агент испытывает различные ситуации в среде, в которой он находится. Они называются состояниями . Агент, находясь в этом состоянии, может выбирать из набора допустимых действий, которые могут принести различные награды (или штрафы). Обучающий агент со временем учится максимизировать эти награды, чтобы вести себя оптимально в любом заданном состоянии.
Q-Learning - это базовая форма обучения с подкреплением, которая использует Q-значения (также называемые значениями действия) для итеративного улучшения поведения обучающего агента.
- Q-значения или Action-Values: Q-значения определены для состояний и действий.
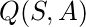 оценка того, насколько хорошо предпринимать действия
оценка того, насколько хорошо предпринимать действия 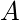 в государстве
в государстве 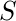 . Эта оценка будет итеративно вычисляться с использованием правила TD-Update, которое мы увидим в следующих разделах.
. Эта оценка будет итеративно вычисляться с использованием правила TD-Update, которое мы увидим в следующих разделах. - Награды и эпизоды: агент в течение своей жизни начинает с начального состояния, совершает ряд переходов из текущего состояния в следующее состояние в зависимости от своего выбора действия, а также среды, в которой агент взаимодействует. На каждом этапе перехода, агент из состояния выполняет действие, наблюдает за наградой из окружающей среды, а затем переходит в другое состояние. Если в какой-то момент агент попадает в одно из конечных состояний, это означает, что дальнейший переход невозможен. Говорят, что это завершение эпизода.
- Временная разница или TD-обновление:
Правило Temporal Difference или TD-Update может быть представлено следующим образом:
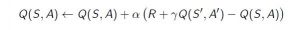
Это правило обновления для оценки значения Q применяется на каждом временном шаге взаимодействия агентов с окружающей средой. Используемые термины поясняются ниже. :
- : Текущее состояние агента.
- : Текущее действие Выбрано в соответствии с некоторой политикой.
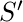 : Следующее состояние, в котором заканчивается агент.
: Следующее состояние, в котором заканчивается агент. 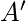 : Следующее лучшее действие, которое нужно выбрать с использованием текущей оценки Q-значения, т.е. выбрать действие с максимальным Q-значением в следующем состоянии.
: Следующее лучшее действие, которое нужно выбрать с использованием текущей оценки Q-значения, т.е. выбрать действие с максимальным Q-значением в следующем состоянии. 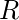 : Текущая награда, наблюдаемая из окружающей среды в ответ на текущее действие.
: Текущая награда, наблюдаемая из окружающей среды в ответ на текущее действие. 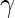 (> 0 и <= 1): коэффициент дисконтирования для будущих вознаграждений. Будущие награды менее ценны, чем текущие, поэтому их нужно сбрасывать со счетов. Поскольку Q-значение является оценкой ожидаемого вознаграждения от государства, здесь также применяется правило дисконтирования.
(> 0 и <= 1): коэффициент дисконтирования для будущих вознаграждений. Будущие награды менее ценны, чем текущие, поэтому их нужно сбрасывать со счетов. Поскольку Q-значение является оценкой ожидаемого вознаграждения от государства, здесь также применяется правило дисконтирования. 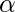 : Длина шага, используемая для обновления оценки Q (S, A).
: Длина шага, используемая для обновления оценки Q (S, A).
- Выбор действия с помощью
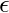 -жадная политика: -greedy policy - очень простая политика выбора действий с использованием текущих оценок Q-значения. Это выглядит следующим образом:
-жадная политика: -greedy policy - очень простая политика выбора действий с использованием текущих оценок Q-значения. Это выглядит следующим образом:- С вероятностью
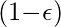 выберите действие, которое имеет наивысшее значение Q.
выберите действие, которое имеет наивысшее значение Q. - С вероятностью
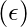 выбрать любое действие наугад.
выбрать любое действие наугад.
Теперь, когда мы располагаем всей необходимой теорией, давайте рассмотрим пример. Мы будем использовать тренажерный зал OpenAI для обучения нашей модели Q-Learning.
Команда установить
gym-pip install тренажерный зал
Перед тем, как начать с примера, вам понадобится вспомогательный код, чтобы визуализировать работу алгоритмов. Будет два вспомогательных файла, которые необходимо загрузить в рабочий каталог. Здесь можно найти файлы.
Шаг №1: Импортируйте необходимые библиотеки.
importgymimportitertoolsimportmatplotlibimportmatplotlib.styleimportnumpy as npimportpandas as pdimportsysfromcollectionsimportdefaultdictfromwindy_gridworldimportWindyGridworldEnvimportplottingmatplotlib.style.use('ggplot')
Шаг № 2: Создайте среду в спортзале.env=WindyGridworldEnv()
Шаг № 3: Сделайте -жирная политика. defcreateEpsilonGreedyPolicy(Q, epsilon, num_actions):"""Creates an epsilon-greedy policy basedon a given Q-function and epsilon.Returns a function that takes the stateas an input and returns the probabilitiesfor each action in the form of a numpy arrayof length of the action space(set of possible actions)."""defpolicyFunction(state):Action_probabilities=np.ones(num_actions,dtype=float)*epsilon/num_actionsbest_action=np.argmax(Q[state])Action_probabilities[best_action]+=(1.0-epsilon)returnAction_probabilitiespolicyFunctionreturn
Шаг №4: Постройте модель Q-Learning.defqLearning(env, num_episodes, discount_factor=1.0,alpha=0.6, epsilon=0.1):"""Q-Learning algorithm: Off-policy TD control.Finds the optimal greedy policy while improvingfollowing an epsilon-greedy policy"""# Action value function# A nested dictionary that maps# state -> (action -> action-value).Q=defaultdict(lambda: np.zeros(env.action_space.n))# Keeps track of useful statisticsstats=plotting.EpisodeStats(episode_lengths=np.zeros(num_episodes),episode_rewards=np.zeros(num_episodes))# Create an epsilon greedy policy function# appropriately for environment action spacepolicy=createEpsilonGreedyPolicy(Q, epsilon, env.action_space.n)# For every episodeforith_episodeinrange(num_episodes):# Reset the environment and pick the first actionstate=env.reset()fortinitertools.count():# get probabilities of all actions from current stateaction_probabilities=policy(state)# choose action according to# the probability distributionaction=np.random.choice(np.arange(len(action_probabilities)),p=action_probabilities)# take action and get reward, transit to next statenext_state, reward, done, _=env.step(action)# Update statisticsstats.episode_rewards[ith_episode]+=rewardstats.episode_lengths[ith_episode]=t# TD Updatebest_next_action=np.argmax(Q[next_state])td_target=reward+discount_factor*Q[next_state][best_next_action]td_delta=td_target-Q[state][action]Q[state][action]+=alpha*td_delta# done is True if episode terminatedifdone:breakstate=next_statereturnQ, stats
Шаг № 5: Обучите модель.Q, stats=qLearning(env,1000)
Шаг № 6: Постройте важную статистику.plotting.plot_episode_stats(stats)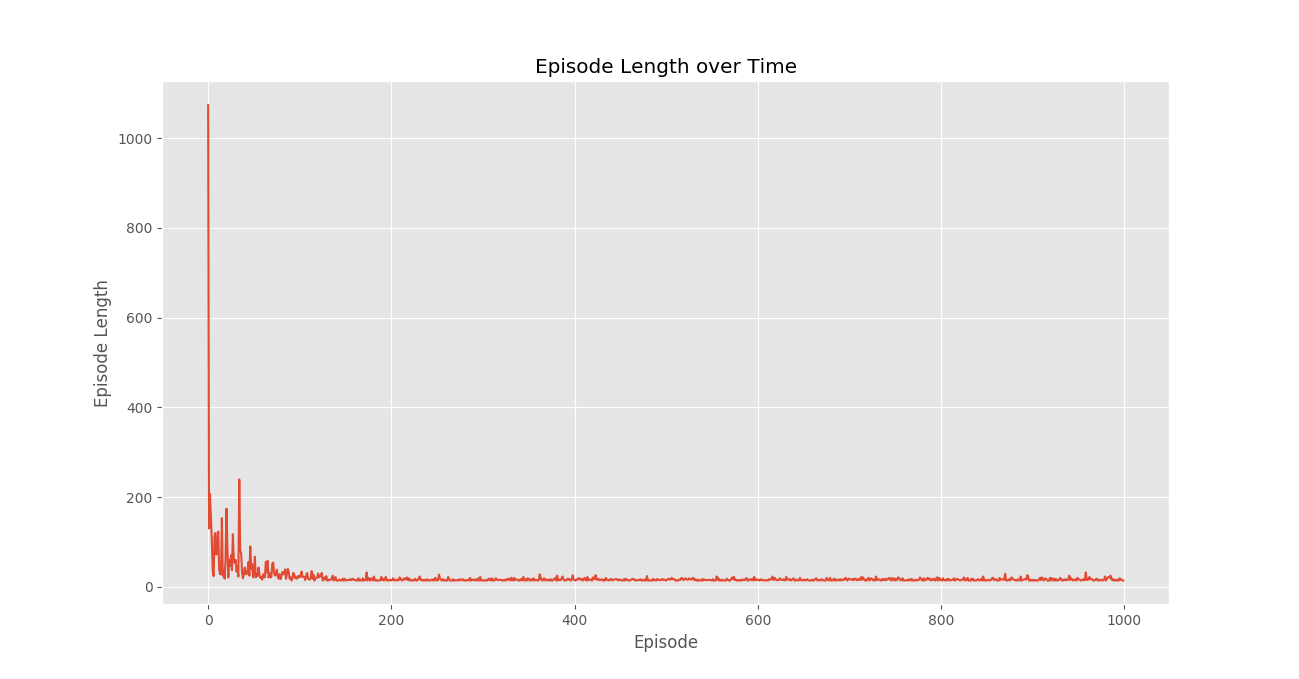
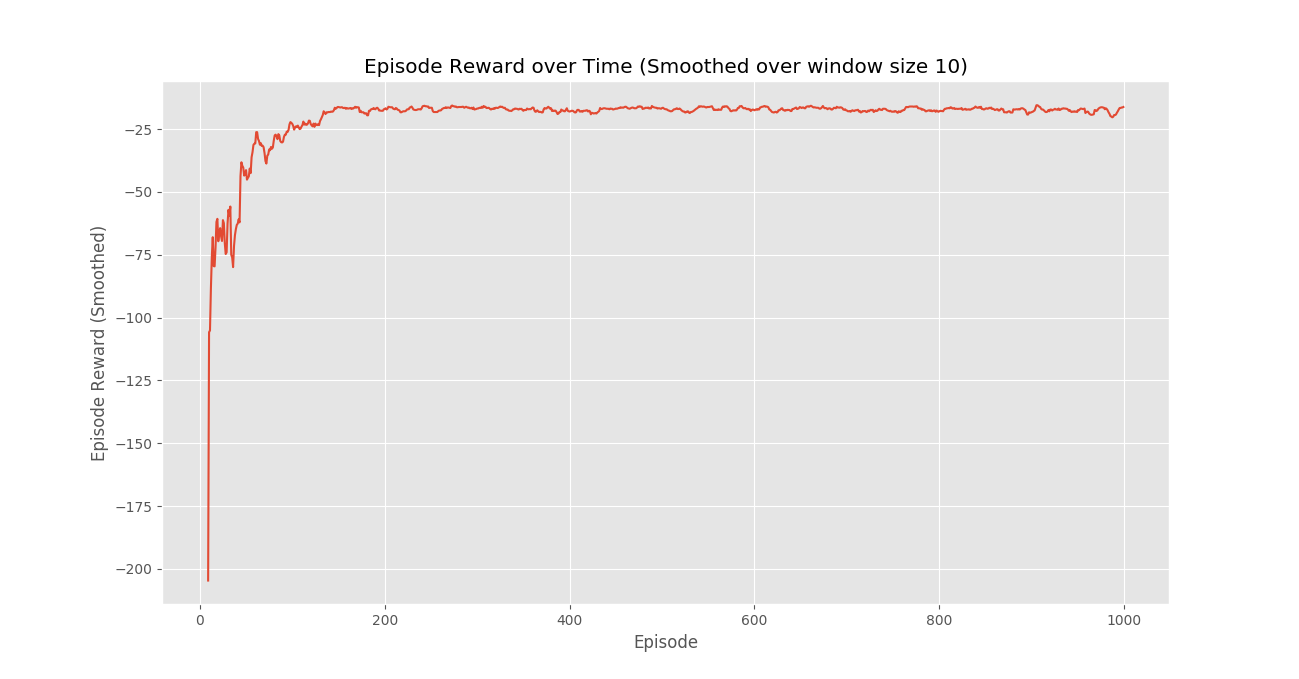
Заключение:
Мы видим, что на графике «Награда за эпизод с течением времени», что награды за эпизод постепенно увеличиваются со временем и, в конечном итоге, выравниваются до высокого значения награды за эпизод, что указывает на то, что агент научился максимизировать свою общую награду, полученную в эпизоде, ведя себя оптимальным образом в каждом эпизоде. государственный.Внимание компьютерщик! Укрепите свои основы с помощью базового курса программирования Python и изучите основы.
Для начала подготовьтесь к собеседованию. Расширьте свои концепции структур данных с помощью курса Python DS. А чтобы начать свое путешествие по машинному обучению, присоединяйтесь к курсу Машинное обучение - базовый уровень.
- С вероятностью