Python | Внедрение системы рекомендаций фильмов
Рекомендательная система - это система, которая стремится предсказать или отфильтровать предпочтения в соответствии с выбором пользователя. Рекомендательные системы используются в различных областях, включая фильмы, музыку, новости, книги, исследовательские статьи, поисковые запросы, социальные теги и продукты в целом.
Рекомендательные системы создают список рекомендаций любым из двух способов:
- Совместная фильтрация: подходы к совместной фильтрации строят модель на основе прошлого поведения пользователя (т. Е. Товаров, купленных или найденных пользователем), а также аналогичных решений, принятых другими пользователями. Затем эта модель используется для прогнозирования элементов (или рейтингов элементов), которые могут заинтересовать пользователя.
- Фильтрация на основе содержимого: подходы к фильтрации на основе содержимого используют серию дискретных характеристик элемента, чтобы рекомендовать дополнительные элементы с аналогичными свойствами. Методы фильтрации на основе содержимого полностью основаны на описании элемента и профиле предпочтений пользователя. Он рекомендует элементы на основе прошлых предпочтений пользователя.
Давайте разработаем базовую систему рекомендаций с использованием Python и Pandas.
Давайте сосредоточимся на предоставлении базовой системы рекомендаций, предлагая элементы, наиболее похожие на конкретный элемент, в данном случае фильмы. Он просто сообщает, какие фильмы / предметы больше всего похожи на выбранный пользователем фильм.
Чтобы скачать файлы, перейдите по ссылкам - файл .tsv, Movie_Id_Titles.csv.
Импортируйте набор данных с разделителем « t», поскольку файл является файлом tsv (файл, разделенный табуляцией).
# import pandas libraryimport pandas as pd # Get the datacolumn_names = [ 'user_id' , 'item_id' , 'rating' , 'timestamp' ] df = pd.read_csv(path, sep = ' ' , names = column_names) # Check the head of the datadf.head() |
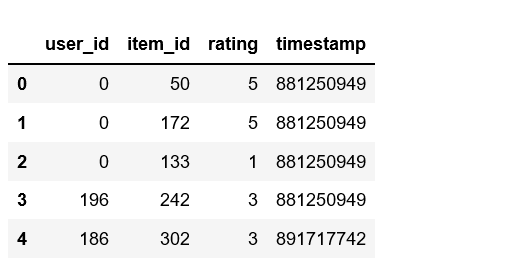
# Check out all the movies and their respective IDsmovie_titles = pd.read_csv( ' https://media.geeksforgeeks.org/wp-content/uploads/Movie_Id_Titles.csv ' )movie_titles.head() |
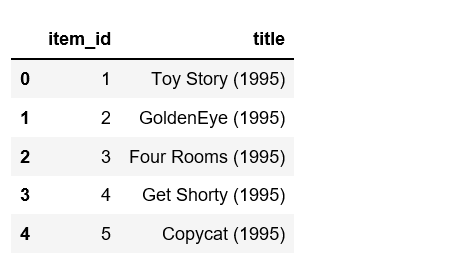
data = pd.merge(df, movie_titles, on = 'item_id' )data.head() |
# Calculate mean rating of all moviesdata.groupby( 'title' )[ 'rating' ].mean().sort_values(ascending = False ).head() |

# Calculate count rating of all moviesdata.groupby( 'title' )[ 'rating' ].count().sort_values(ascending = False ).head() |

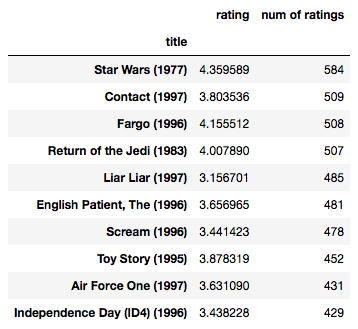
# creating dataframe with 'rating' count valuesratings = pd.DataFrame(data.groupby( 'title' )[ 'rating' ].mean()) ratings[ 'num of ratings' ] = pd.DataFrame(data.groupby( 'title' )[ 'rating' ].count()) ratings.head() |

Импорт визуализации:
import matplotlib.pyplot as pltimport seaborn as sns sns.set_style( 'white' )% matplotlib inline |
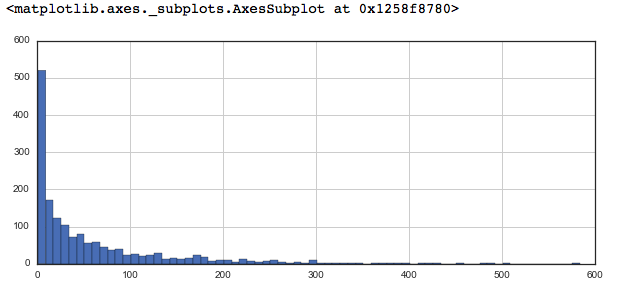
# plot graph of 'num of ratings column'plt.figure(figsize = ( 10 , 4 )) ratings[ 'num of ratings' ].hist(bins = 70 ) |
# plot graph of 'ratings' columnplt.figure(figsize = ( 10 , 4 )) ratings[ 'rating' ].hist(bins = 70 ) |
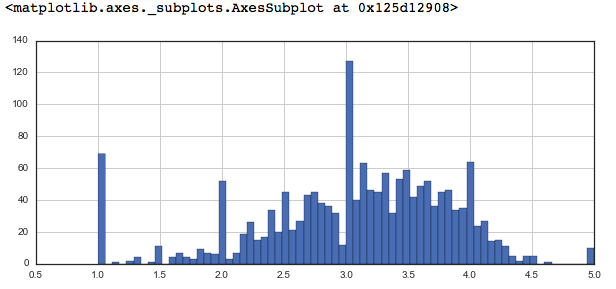
# Sorting values according to# the 'num of rating column'moviemat = data.pivot_table(index = 'user_id' , columns = 'title' , values = 'rating' ) moviemat.head() ratings.sort_values( 'num of ratings' , ascending = False ).head( 10 ) |
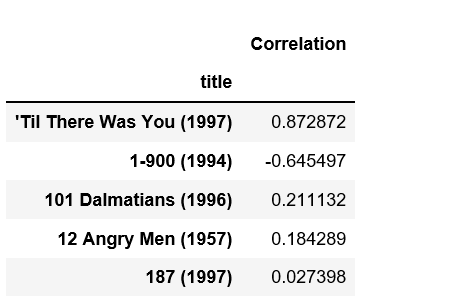
# analysing correlation with similar moviesstarwars_user_ratings = moviemat[ 'Star Wars (1977)' ]liarliar_user_ratings = moviemat[ 'Liar Liar (1997)' ] starwars_user_ratings.head() |

# analysing correlation with similar moviessimilar_to_starwars = moviemat.corrwith(starwars_user_ratings)similar_to_liarliar = moviemat.corrwith(liarliar_user_ratings) corr_starwars = pd.DataFrame(similar_to_starwars, columns = [ 'Correlation' ])corr_starwars.dropna(inplace = True ) corr_starwars.head() |
# Similar movies like starwarscorr_starwars.sort_values( 'Correlation' , ascending = False ).head( 10 )corr_starwars = corr_starwars.join(ratings[ 'num of ratings' ]) corr_starwars.head() corr_starwars[corr_starwars[ 'num of ratings' ]> 100 ].sort_values( 'Correlation' , ascending = False ).head() |
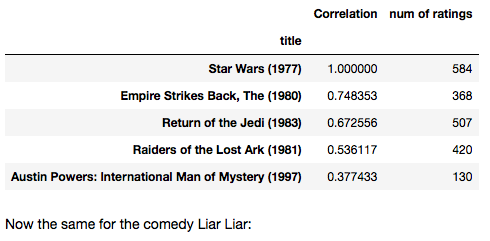
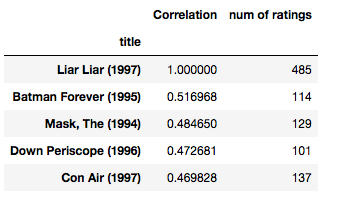
# Similar movies as of liarliarcorr_liarliar = pd.DataFrame(similar_to_liarliar, columns = [ 'Correlation' ])corr_liarliar.dropna(inplace = True ) corr_liarliar = corr_liarliar.join(ratings[ 'num of ratings' ])corr_liarliar[corr_liarliar[ 'num of ratings' ]> 100 ].sort_values( 'Correlation' , ascending = False ).head() |
Внимание компьютерщик! Укрепите свои основы с помощью базового курса программирования Python и изучите основы.
Для начала подготовьтесь к собеседованию. Расширьте свои концепции структур данных с помощью курса Python DS. А чтобы начать свое путешествие по машинному обучению, присоединяйтесь к курсу Машинное обучение - базовый уровень.