Python | Создавайте тестовые наборы данных для машинного обучения
Когда мы думаем о машинном обучении, первое, что приходит в голову, - это набор данных. Хотя существует множество наборов данных, которые вы можете найти на таких веб-сайтах, как Kaggle, иногда бывает полезно извлечь данные самостоятельно и создать свой собственный набор данных. Создание собственного набора данных дает вам больший контроль над данными и позволяет обучать вашу модель машинного обучения.
В этой статье мы сгенерируем случайные наборы данных с помощью библиотеки Numpy в Python.
Необходимые библиотеки:
-> Numpy: pip3 установить numpy -> Панды: pip3 установить панды -> Matplotlib: pip3 установить matplotlib
Нормальное распределение:
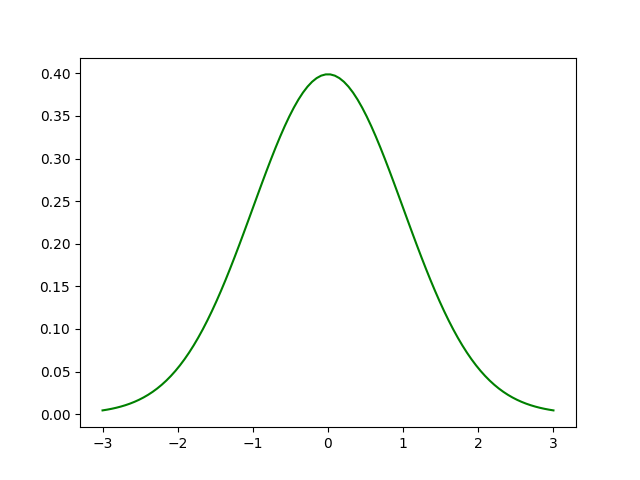
В теории вероятностей нормальное или гауссовское распределение - это очень распространенное непрерывное распределение вероятностей, которое симметрично относительно среднего, показывая, что данные, близкие к среднему, встречаются чаще, чем данные, далекие от среднего. Нормальные распределения используются в статистике и часто используются для представления случайных величин с действительными значениями.
Нормальное распределение - наиболее распространенный тип распределения в статистическом анализе. Стандартное нормальное распределение имеет два параметра: среднее значение и стандартное отклонение. Среднее значение - это центральная тенденция распределения. Стандартное отклонение - это мера изменчивости. Он определяет ширину нормального распределения. Стандартное отклонение определяет, насколько далеко от среднего значения имеют тенденцию падать. Он представляет собой типичное расстояние между наблюдениями и средним значением. он соответствует многим природным явлениям. Например, рост, артериальное давление, ошибка измерения и показатели IQ соответствуют нормальному распределению.
График нормального распределения:
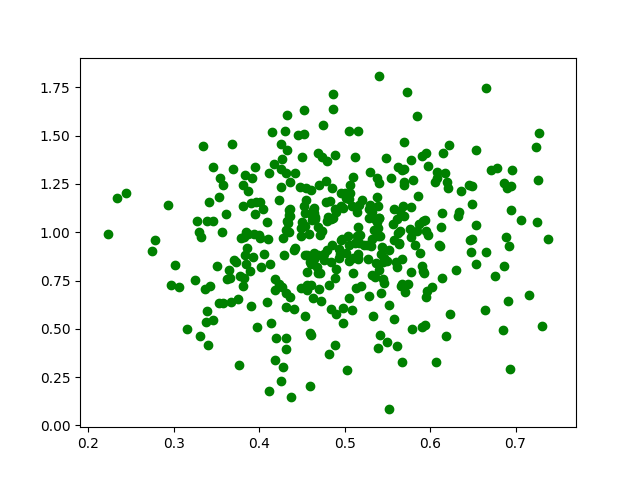
Пример:
PYTHON3
# importing librariesimport pandas as pdimport numpy as npimport matplotlib.pyplot as plt# initialize the parameters for the normal# distribution, namely mean and std.# deviation# defining the meanmu = 0.5# defining the standard deviationsigma = 0.1# The random module uses the seed value as a base# to generate a random number. If seed value is not# present, it takes the system's current time.np.random.seed( 0 )# define the x co-ordinatesX = np.random.normal(mu, sigma, ( 395 , 1 ))# define the y co-ordinatesY = np.random.normal(mu * 2 , sigma * 3 , ( 395 , 1 ))# plot a graphplt.scatter(X, Y, color = 'g' )plt.show() |
Выход :
Давайте посмотрим на лучший пример.
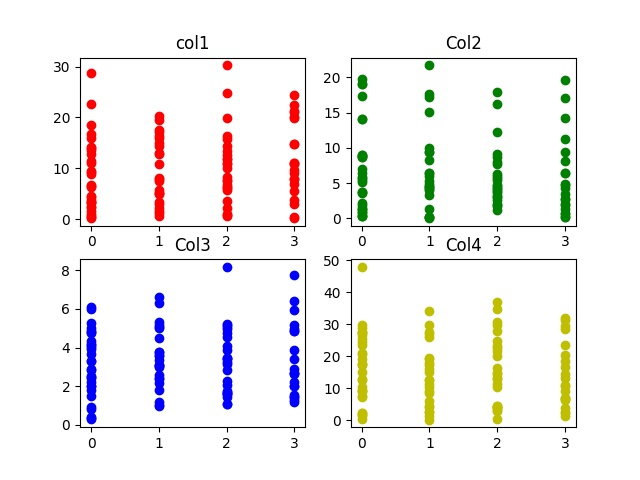
Мы сгенерируем набор данных с 4 столбцами. Каждый столбец в наборе данных представляет функцию. Пятый столбец набора данных - это метка вывода. Он варьируется от 0 до 3. Этот набор данных можно использовать для обучения классификатора, такого как классификатор логистической регрессии, классификатор нейронной сети, опорные векторные машины и т. Д.
PYTHON3
# importing librariesimport numpy as npimport pandas as pdimport mathrandom importimport matplotlib.pyplot as plt# defining the columns using normal distribution# column 1point1 = abs (np.random.normal( 1 , 12 , 100 ))# column 2point2 = abs (np.random.normal( 2 , 8 , 100 ))# column 3point3 = abs (np.random.normal( 3 , 2 , 100 ))# column 4point4 = abs (np.random.normal( 10 , 15 , 100 ))# x contains the features of our dataset# the points are concatenated horizontally# using numpy to form a feature vector.x = np.c_[point1, point2, point3, point4]# the output labels vary from 0-3y = [ int (np.random.randint( 0 , 4 )) for i in range ( 100 )]# defining a pandas data frame to save# the data for later usedata = pd.DataFrame()# defining the columns of the datasetdata[ 'col1' ] = point1data[ 'col2' ] = point2data[ 'col3' ] = point3data[ 'col4' ] = point4 # plotting the various features (x)# against the labels (y).plt.subplot( 2 , 2 , 1 )plt.title( 'col1' )plt.scatter(y, point1, color = 'r' , label = 'col1' ) plt.subplot( 2 , 2 , 2 )plt.title( 'Col2' )plt.scatter(y, point2, color = 'g' , label = 'col2' ) plt.subplot( 2 , 2 , 3 )plt.title( 'Col3' )plt.scatter(y, point3, color = 'b' , label = 'col3' ) plt.subplot( 2 , 2 , 4 )plt.title( 'Col4' )plt.scatter(y, point4, color = 'y' , label = 'col4' ) # saving the graphplt.savefig( 'data_visualization.jpg' )# displaying the graphplt.show() |
Выход :