Прогноз количества транспортных средств на основе данных датчиков
Предпосылка: регрессия и классификация | Машинное обучение с учителем
Датчики, размещенные на перекрестках дорог, собирают данные об отсутствии транспортных средств на разных перекрестках и передают данные диспетчеру транспорта. Теперь наша задача - спрогнозировать общее количество транспортных средств на основе данных датчиков.
В этой статье объясняется, как работать с данными датчиков, указанными с меткой времени, и прогнозировать количество автомобилей в определенное время.
Описание набора данных:
Этот набор данных содержит 2 атрибута. Это Datetime и Vehicles. Где Транспортные средства - это метка класса.
Ссылка для загрузки этих данных - нажмите здесь
Метка класса имеет числовой тип. Так что метод регрессии хорошо подходит для этой задачи. Регрессия используется для отображения данных в предопределенную функцию. Это контролируемый алгоритм обучения, который используется для прогнозирования значения на основе исторических данных. Мы можем выполнить регрессию наших данных, если они числовые. Здесь метка класса. Атрибут «Транспортные средства» - это метка класса, которая является числовой, поэтому необходимо выполнить регрессию.
Регрессор случайного леса - это метод ансамбля, который принимает входные данные и строит деревья, а затем принимает среднее значение всех деревьев на строку / на кортеж.
Syntax: RandomForestRegressor(n_estimators=100, *, criterion=’mse’, max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=’auto’, max_leaf_nodes=None,min_impurity_decrease=0.0, min_impurity_split=None, bootstrap=True, oob_score=False, n_jobs=None,random_state=None, verbose=0, warm_start=False, ccp_alpha=0.0, max_samples=None)
Подход:
- Импортировать необходимые модули
- Загрузите набор данных
- Анализировать данные
- Преобразуйте атрибут DateTime в неделю, дни, часы, месяц и т. Д. (В формате отметки времени).
- Построить модель
- Обучите модель
- Проверить данные
- Предсказать результаты
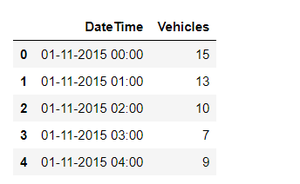
Шаг 1: Импорт модуля pandas для загрузки фрейма данных.
Python3
# importing the pandas module for# data frameimport pandas as pd # load the data set into train variable.train = pd.read_csv( 'vehicles.csv' ) # display top 5 values of data settrain.head() |
Выход:
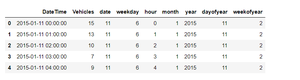
Шаг 2: Определите функции для получения месяца, дня, часов из метки времени (DateTime) и загрузите ее в разные столбцы.
Python3
# function to get all data fron time stamp # get datedef get_dom(dt): return dt.day # get week daydef get_weekday(dt): return dt.weekday() # get hourdef get_hour(dt): return dt.hour # get yeardef get_year(dt): return dt.year # get monthdef get_month(dt): return dt.month # get year daydef get_dayofyear(dt): return dt.dayofyear # get year weekdef get_weekofyear(dt): return dt.weekofyear train[ 'DateTime' ] = train[ 'DateTime' ]. map (pd.to_datetime)train[ 'date' ] = train[ 'DateTime' ]. map (get_dom)train[ 'weekday' ] = train[ 'DateTime' ]. map (get_weekday)train[ 'hour' ] = train[ 'DateTime' ]. map (get_hour)train[ 'month' ] = train[ 'DateTime' ]. map (get_month)train[ 'year' ] = train[ 'DateTime' ]. map (get_year)train[ 'dayofyear' ] = train[ 'DateTime' ]. map (get_dayofyear)train[ 'weekofyear' ] = train[ 'DateTime' ]. map (get_weekofyear) # displaytrain.head() |
Выход:
Шаг 3. Разделите метку класса и сохраните в целевой переменной.
Python3
# there is no use of DateTime module# so remove ittrain = train.drop([ 'DateTime' ], axis = 1 ) # seperating class label for training the datatrain1 = train.drop([ 'Vehicles' ], axis = 1 ) # class label is stored in targettarget = train[ 'Vehicles' ] print (train1.head())target.head() |
Выход:
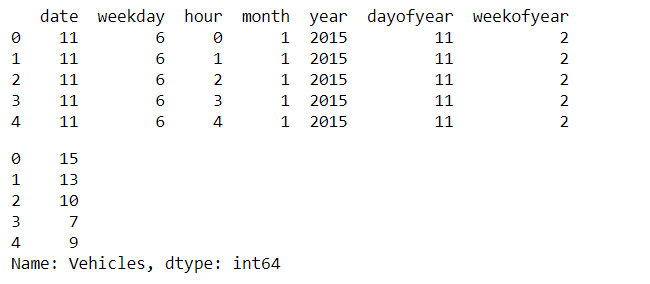
Шаг 4. Создайте и обучите данные с помощью алгоритмов машинного обучения и спрогнозируйте результаты после тестирования.
Python3
#importing Random forestfrom sklearn.ensemble import RandomForestRegressor #defining the RandomForestRegressorm1 = RandomForestRegressor() m1.fit(train1,target)#testingm1.predict([[ 11 , 6 , 0 , 1 , 2015 , 11 , 2 ]]) |
Выход:
массив ([9.88021429])