PostgreSQL - Многоколоночные индексы
В PostgreSQL индексы с несколькими столбцами - это индексы, определенные для нескольких столбцов таблицы.
Вы можете создать индекс более чем для одного столбца таблицы. Этот индекс называется многоколоночным индексом, составным индексом, комбинированным индексом или составным индексом. Многоколоночный индекс может содержать не более 32 столбцов таблицы. Предел можно изменить, изменив файл pg_config_manual.h при сборке PostgreSQL. Кроме того, только типы индексов B-tree, GIST, GIN и BRIN поддерживают многоколоночные индексы.
Следующий синтаксис показывает, как создать многоколоночный индекс:
Синтаксис: CREATE INDEX имя_индекса ON имя_таблицы (a, b, c, ...);
При определении многоколоночного индекса следует поместить столбцы, которые часто используются в предложении WHERE, в начале списка столбцов, а столбцы, которые реже используются в условии после.
В приведенном выше синтаксисе оптимизатор PostgreSQL рассмотрит возможность использования индекса в следующих случаях:
WHERE a = v1 and b = v2 and c = v3;
или,
ГДЕ a = v1 и b = v2;
или,
ГДЕ a = v1;
Однако он не будет рассматривать использование индекса в следующих случаях:
ГДЕ c = v3;
или,
ГДЕ b = v2 и c = v3;
Пример:
Чтобы продемонстрировать многоколоночные индексы, мы создадим новую таблицу с именем people с тремя столбцами: id, имя и фамилия:
СОЗДАТЬ ТАБЛИЦЫ люди (
id INT СОЗДАЕТСЯ ПО УМОЛЧАНИЮ КАК ИДЕНТИЧНОСТЬ,
first_name VARCHAR (50) NOT NULL,
last_name VARCHAR (50) NOT NULL
);
Вы можете добавлять данные о людях через этот файл.
Следующее утверждение находит людей по фамилии Адамс :
SELECT
*
FROM
people
WHERE
last_name = "Adams";
Это приведет к следующему:
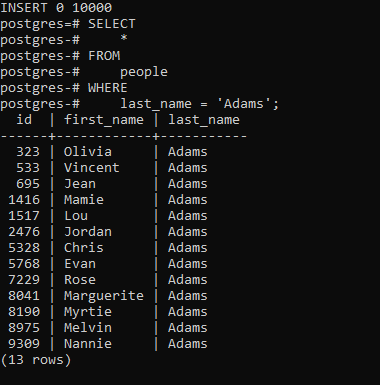
Как ясно показано в выходных данных, PostgreSQL выполнил последовательное сканирование таблицы people, чтобы найти соответствующие строки, поскольку для столбца last_name не был определен индекс.
Давайте определим индекс B-дерева для столбцов last_name и first_name. Предполагая, что поиск людей по фамилии осуществляется чаще, чем по имени, мы определяем индекс со следующим порядком столбцов:
СОЗДАТЬ ИНДЕКС idx_people_names НА люди (last_name, first_name);
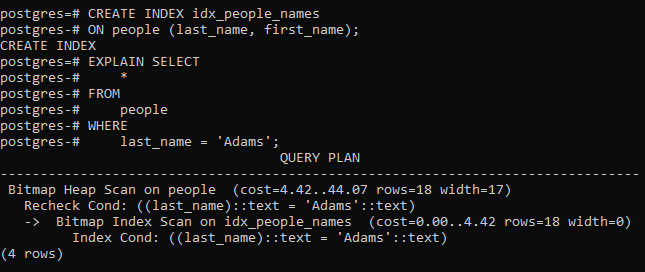
Теперь, если вы ищете людей по фамилии Адамс , оптимизатор PostgreSQL будет использовать индекс, как показано в выходных данных следующего оператора:
ОБЪЯСНИТЬ ВЫБРАТЬ
*
ИЗ
люди
КУДА
last_name = 'Адамс';
Это выведет следующее:
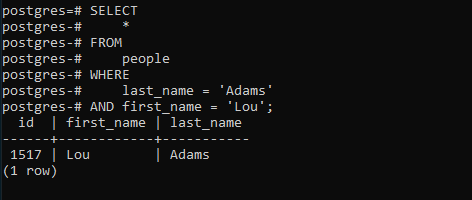
Следующее утверждение находит человека по фамилии Адамс, а имя - Лу:
ВЫБРАТЬ
*
ИЗ
люди
КУДА
last_name = 'Адамс'
И first_name = 'Лу';
Это приведет к следующему:
Оптимизатор PostgreSQL использовал индекс для этого оператора, потому что оба столбца в предложении WHERE все находятся в индексе:
ОБЪЯСНИТЬ ВЫБРАТЬ
*
ИЗ
люди
КУДА
last_name = 'Адамс'
И first_name = 'Лу';
Однако, если вы ищете людей, чье имя Лу , PostgreSQL выполнит последовательное сканирование таблицы вместо использования индекса, как показано в выводе следующего оператора:
ОБЪЯСНИТЬ ВЫБРАТЬ
*
ИЗ
люди
КУДА
first_name = 'Лу';
Выход:
