Последовательный алгоритм покрытия
Предварительные требования: алгоритм изучения одного правила
Последовательное покрытие - это популярный алгоритм, основанный на классификации на основе правил, используемый для изучения дизъюнктивного набора правил. Основная идея здесь - изучить одно правило, удалить данные, которые оно охватывает, а затем повторить тот же процесс. В этом процессе, таким образом, он последовательно охватывает все связанные с ним правила на этапе обучения.
Используемый алгоритм:
Последовательное_крытие (целевой_атрибут, атрибуты, примеры, порог):
Learned_rules = {}
Правило = Выучить одно правило (целевой_атрибут, атрибуты, примеры)
пока Производительность (Правило, Примеры)> Порог:
Learned_rules = Learned_rules + Правило
Примеры = Примеры - {примеры, правильно классифицированные по Правилу}
Правило = Learn-One-Rule (Target_attribute, Attributes, examples)
Learned_rules = сортировать Learned_rules в соответствии с эффективностью по сравнению с примерами
вернуть Learned_rules
Алгоритм последовательного обучения в некоторой степени решает проблему низкого покрытия в алгоритме обучения одному правилу, охватывающему все правила последовательным образом.
Работаем по алгоритму:
Алгоритм включает набор «упорядоченных правил» или «список решений», которые необходимо принять.
Step 1 – create an empty decision list, ‘R’.
Step 2 – ‘Learn-One-Rule’ Algorithm
It extracts the best rule for a particular class ‘y’, where a rule is defined as: (Fig.2)
Общая форма правления
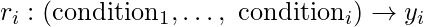
In the beginning,
Step 2.a – if all training examples ∈ class ‘y’, then it’s classified as positive example.
Step 2.b – else if all training examples ∉ class ‘y’, then it’s classified as negative example.Step 3 – The rule becomes ‘desirable’ when it covers a majority of the positive examples.
Step 4 – When this rule is obtained, delete all the training data associated with that rule.
(i.e. when the rule is applied to the dataset, it covers most of the training data, and has to be removed)Step 5 – The new rule is added to the bottom of decision list, ‘R’. (Fig.3)
Рис. 3: Список решений «R»
Ниже представлено визуальное представление, описывающее работу алгоритма.
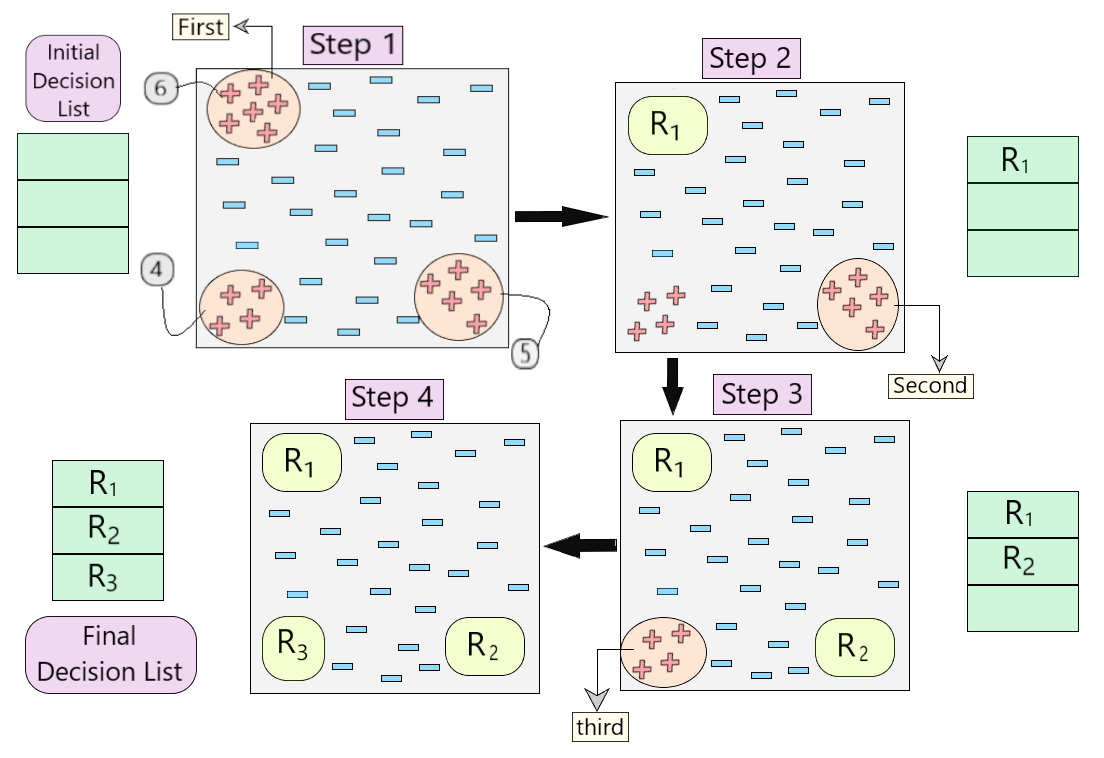
Рис 4: Визуальное представление работы алгоритма
- Давайте разберемся пошагово, как работает алгоритм на примере, показанном на рисунке 4.
- Сначала мы создали пустой список решений. На шаге 1 мы видим, что в наборе данных присутствуют три набора положительных примеров. Итак, по алгоритму мы рассматриваем тот, у которого максимально нет положительного примера. (6, как показано на шаге 1 на рис. 4)
- Как только мы рассмотрим эти 6 положительных примеров, мы получим наше первое правило R 1 , которое затем помещается в список решений, и эти положительные примеры удаляются из набора данных. (как показано на шаге 2 на рис. 4)
- Теперь возьмем следующее большинство положительных примеров (5, как показано на шаге 2 на рис. 4) и проделаем тот же процесс, пока не получим правило R 2 . (То же для R 3 )
- В конце концов, мы получаем окончательный список решений со всеми желательными правилами.
Последовательное обучение - это мощный алгоритм для создания классификаторов на основе правил в машинном обучении. Он использует алгоритм «Learn-One-Rule» в качестве основы для изучения последовательности дизъюнктивных правил. Если есть сомнения / вопросы относительно алгоритма, оставьте комментарий ниже.