Почему Apache Kafka такой быстрый?
Apache Kafka - это хорошо известная платформа обработки потоковых данных с открытым исходным кодом, цель которой - предоставить отказоустойчивую платформу с высокой пропускной способностью, малой задержкой и отказоустойчивостью, которая способна обрабатывать ввод данных в реальном времени.
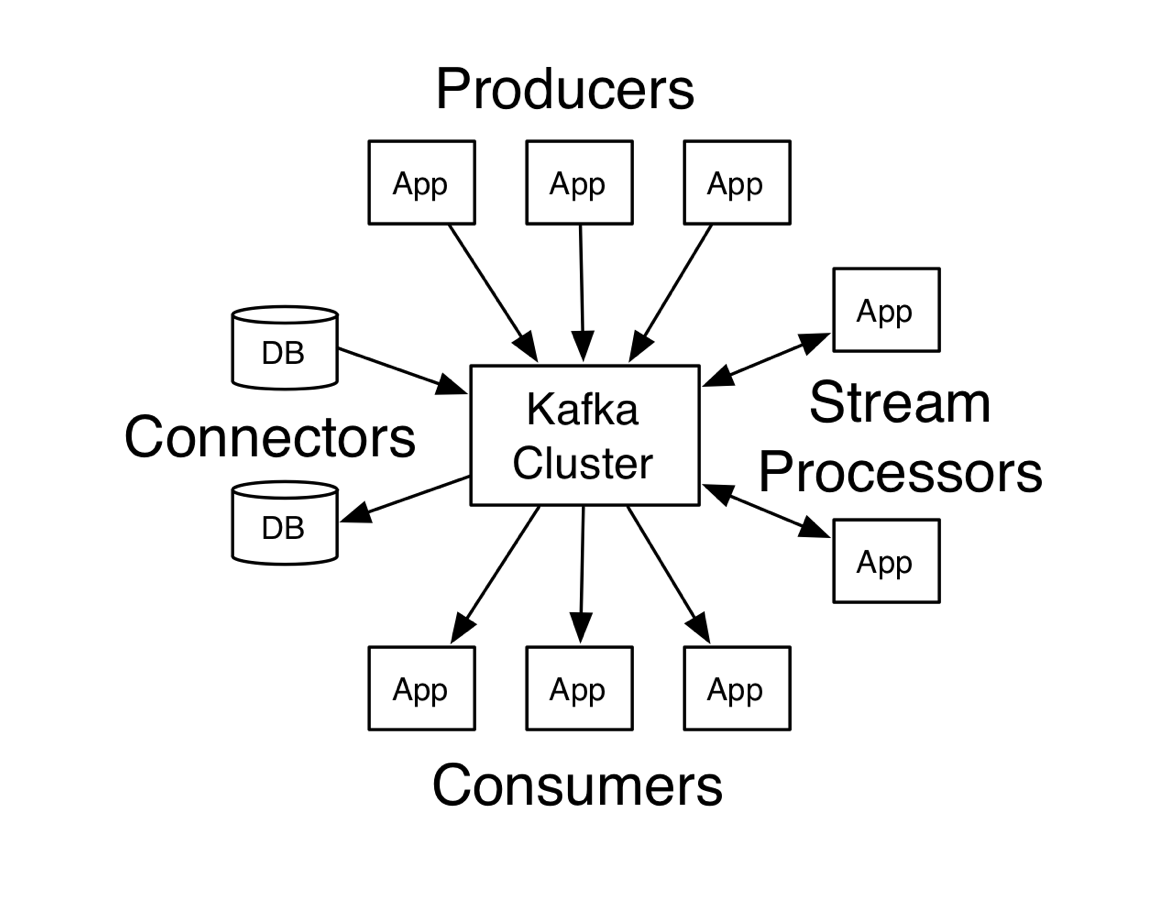
Так что же делает Apache Kafka предпочтительной платформой для обработки данных в реальном времени? Помимо всех других преимуществ, которые предоставляет Kafka, скорость является одним из самых важных. Давайте посмотрим, как Kafka устроен так быстро.
1. Ввод-вывод с малой задержкой: есть два возможных места, которые можно использовать для хранения и кэширования данных: оперативная память (RAM) и диск .
- Традиционный способ добиться низкой задержки при доставке сообщений - использовать оперативную память. Это предпочтительнее диска, потому что у дисков высокое время поиска, что делает их медленнее.
- Обратной стороной этого подхода является то, что использование ОЗУ может быть дорогостоящим, когда объем данных, проходящих через вашу систему, составляет от 10 до 500 ГБ в секунду или даже больше.
Таким образом, Kafka полагается на файловую систему для хранения и кэширования сообщений. Хотя он использует подход диска, а не подход RAM, ему все же удается достичь низкой задержки! Вы можете задаться вопросом, как это возможно, учитывая большое время поиска. Давай выясним.
2. Кафка избегает времени поиска : Да! Kafka умело избегает времени поиска, используя концепцию, называемую последовательным вводом-выводом .
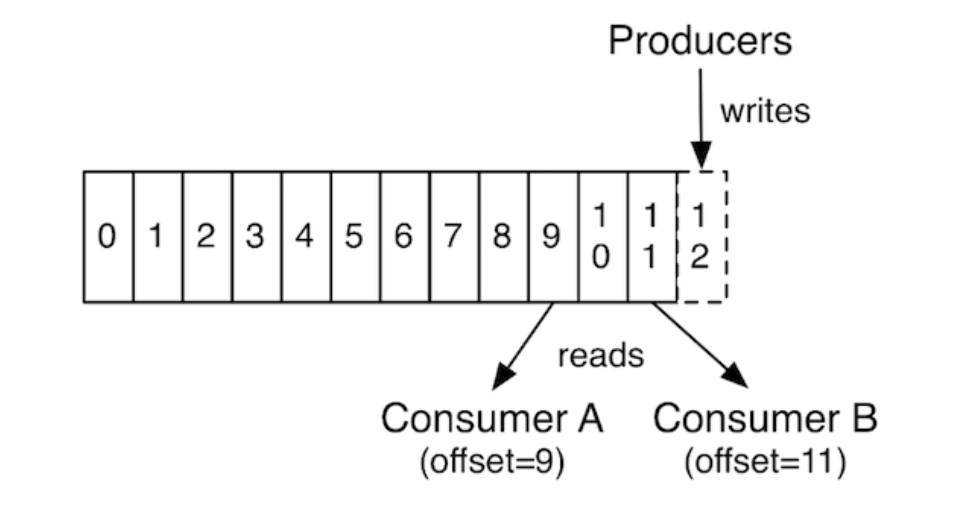
- Он использует структуру данных под названием «журнал», которая представляет собой последовательность записей, упорядоченных по времени, только для добавления. Журнал в основном представляет собой очередь, и он может быть добавлен в конце производителем, а подписчики могут обрабатывать сообщения самостоятельно, поддерживая указатели.
- Первая опубликованная запись получает смещение 0, вторая - 1 и так далее.
- Данные потребляются потребителями путем доступа к позиции, указанной смещением. Потребители периодически сохраняют свою позицию в журнале.
- Это также делает Kafka отказоустойчивой системой, поскольку сохраненные смещения могут использоваться другими потребителями для чтения новых записей в случае сбоя текущего экземпляра потребителя. Этот подход устраняет необходимость поиска на диске, поскольку данные присутствуют последовательно, как показано ниже:
3. Принцип нулевого копирования: наиболее распространенный способ отправки данных по сети требует множественных переключений контекста между режимом ядра и режимом пользователя, что приводит к потреблению полосы пропускания памяти и циклов ЦП. Принцип нулевого копирования направлен на уменьшение этого, требуя от ядра переместить данные непосредственно в ответный сокет, а не перемещать их через приложение. Скорость Kafka значительно повышается за счет реализации принципа нулевого копирования.
4. Оптимальная структура данных: дерево или очередь: дерево кажется предпочтительной структурой данных, когда дело доходит до хранения данных. Большинство современных баз данных используют некоторую форму древовидной структуры данных. Например. MongoDB использует BTree.
- Kafka, с другой стороны, является не базой данных, а системой обмена сообщениями, и, следовательно, он выполняет больше операций чтения / записи по сравнению с базой данных.
- Использование для этого дерева может привести к случайному вводу-выводу, что в конечном итоге приведет к поиску диска, что катастрофически с точки зрения производительности.
Таким образом, он использует очередь, поскольку все данные добавляются в конце, а чтение очень простое за счет использования указателей. Эти операции O (1), тем самым подтверждая эффективность структуры данных очереди для Kafka.
5. Горизонтальное масштабирование: Kafka может иметь несколько разделов для одной темы, которые могут быть распределены по тысячам машин. Это позволяет поддерживать высокую пропускную способность и обеспечивать низкую задержку.
6. Сжатие и пакетирование данных: Kafka группирует данные в блоки, что помогает уменьшить количество сетевых вызовов и преобразовать большую часть случайных операций записи в последовательные. Сжатие пакета данных более эффективно, чем сжатие отдельных сообщений.
Следовательно, Kafka сжимает пакет сообщений и отправляет их на сервер, где они записываются в сжатом виде. Они распаковываются при использовании подписчиком. Протоколы сжатия GZIP и Snappy поддерживаются Kafka.