Планирование высокой доступности: попытка устранить время простоя
Будь то дисковые массивы или кластерные серверы, запланированная избыточность всегда является хорошей ставкой при планировании высокой доступности. В этой статье мы рассмотрим, что вам нужно знать, чтобы спланировать решение высокой доступности, которое будет поддерживать доступность сервисов для тех, кто в них нуждается… и зависит от них. Высокая доступность требует некоторой работы и усилий в начале. Уделение времени планированию и проектированию является ключом к максимизации возможности успешного развертывания. Такая же осторожность должна быть внесена в процесс проектирования. Проектирование высокой доступности часто бывает сложным и требует знания очень многих областей ИТ, чтобы сделать это правильно, или команда, используемая для планирования решения высокой доступности, окажется разнородной. Итак, давайте посмотрим, зачем вам нужна высокая доступность и что вы можете сделать для ее планирования. В этом разделе мы рассмотрим, как спланировать время простоя, как построить план, как управлять вашими услугами, оценить систему и протестировать ваш план. Помните, что высокая доступность гарантирует время безотказной работы, время безотказной работы может быть вашим бизнесом, поэтому вам следует учитывать затраты на внедрение высокодоступного решения, один сбой, который приводит к простою вашей серии, может быть всем, что нужно, чтобы заплатить за решение в первую очередь.
«Полное руководство по обеспечению высокой доступности см. в статье Кластеризация и балансировка нагрузки Windows Server 2003 на Amazon.com».
Планируйте время простоя
Вам необходимо достичь как можно более близкого к 100-процентному времени безотказной работы. Все мы знаем, что это не совсем реально, вещи ломаются. Поломки происходят из-за сбоев диска, отказа питания или ИБП, проблем с приложениями, приводящих к сбоям системы, или любых других аппаратных или программных сбоев. Вы можете составить список длиной в милю со всеми вещами, которые могут пойти не так с компьютерной системой! Итак, следующий лучший результат — 99,999% (5 девяток), что вполне приемлемо для современных технологий. В наши дни вы можете (при наличии достаточного количества наличных денег) встроить избыточность практически во что угодно. Примерами могут быть RAID (избыточный массив недорогих дисков) или пара кластеризованных серверов, как показано на рисунке 1.
Рисунок 1: Простой кластер из 2 узлов
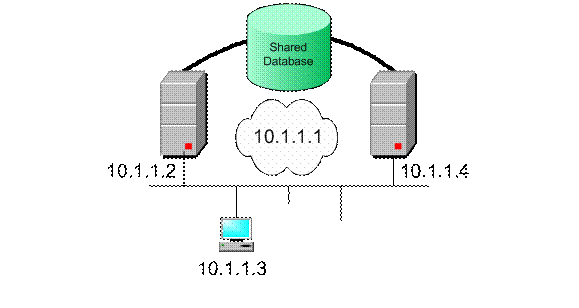
Кластерное решение может помочь вам свести к минимуму время простоя, потому что у вас есть решение, основанное на запланированном сбое! Клиент (10.1.1.3) хочет получить доступ к данным из базы данных на сервере, который отображается как 10.1.1.1. Это VIP (виртуальный IP), который создает прозрачное решение для клиента — доступ к одному серверу, когда на самом деле готовы оба сервера. Если один сервер выходит из строя, его место занимает другой. База данных может быть общей конфигурацией RAID, которая также отличается высокой доступностью. Подобные решения, если вы правильно спланируете их, могут помочь вам максимально увеличить время безотказной работы и помочь вам реже справляться с простоями.
SLA и пять девяток
Вы также можете определить в Соглашении об уровне обслуживания (SLA), что означает 99,999% для обеих сторон…. Обе стороны - это то, что вы запросили бы у поставщика услуг, и то, что вы должны были бы предоставить в качестве поставщика услуг. Иногда я считаю себя поставщиком услуг, если развертываю сервер… название «сервер» подразумевает его назначение. Клиент «будет» требовать, чтобы он обслуживал без остановок, пока на самом деле не выйдет из строя. Если вы пообещали кому-то 99,999% времени безотказной работы в течение одного года, это означает, что коэффициент простоя составляет от пяти до десяти минут. Поскольку это может показаться довольно трудным для выполнения, может иметь смысл стремиться к более разумному времени безотказной работы, более реалистичному по сравнению с запланированными отключениями и возможным тестированием аварийного восстановления, выполняемым вашим персоналом. Со временем вещи приходится заменять или дорабатывать, и 10 минут в год просто не помогут. Что-то более разумное для вашей ситуации может быть ближе к 99,9% времени безотказной работы, что означает от девяти до десяти часов простоя в год. Это более практично и возможно получить. Предоставляя или получая такую услугу, обе стороны должны протестировать запланированные отключения, чтобы убедиться, что графики доставки могут быть соблюдены.
Вы можете вычислить эту формулу, взяв количество часов в дне (24) и умножив его на количество дней в году (365). Это равняется 8760 часам в году. Используйте следующее уравнение:
% времени безотказной работы в год = (8 760 — общее количество часов простоя в год) / 8 760
Если вы планируете восемь часов простоя в месяц для обслуживания и простоев
(всего 96 часов), то вы можете сказать, что процент времени безотказной работы в год равен 8760 минус 96, деленное на 8760. Вы можете видеть, что вы получите около 98,9% времени безотказной работы ваших систем. Это должен быть простой способ обеспечить точный учет времени простоя.
Помните, что при планировании высокой доступности необходимо точно учитывать время простоя. Время простоя может быть запланированным или, что еще хуже, неожиданным. К очень распространенным и часто упускаемым из виду источникам неожиданного простоя относятся следующие:
- Сбой или сбой диска
- Сбой питания или ИБП (или отсутствие резервного питания)
- Проблемы с приложениями, приводящие к сбоям системы
- Любая другая аппаратная или программная неисправность (ошибки/глюки)
Убедитесь, что вы планируете соответствующим образом и рассмотрите свои варианты запланированного времени простоя и то, что вы можете разумно предоставить, если вы являетесь поставщиком услуг, или что вы ожидаете от своего поставщика услуг.
Построение плана высокодоступных решений
Прежде чем мы углубимся в «официальный» план, давайте посмотрим, почему он вам нужен. Рассмотрим следующий сценарий: простой сбой сервера и во что это обойдется вам и вашей компании. Ниже приведен список того, что может произойти по порядку:
- Компания использует сервер для доступа к приложению, которое принимает заказы и выполняет транзакции. (это переводится как «как компания собирает деньги с клиентов»)
- Приложение, когда оно запущено, обслуживает не только сотрудников отдела продаж, но и еще три компании, осуществляющие B2B-транзакции. По оценкам, в течение одного часа максимально заработанные деньги превысили 2,5 миллиона долларов.
- Сервер выходит из строя, и у вас нет решения High Availability.
- Это означает, что аварийное переключение, избыточность или балансировка нагрузки вообще отсутствуют. Это просто терпит неудачу.
- Вам (системному инженеру) требуется 5 минут, чтобы вызвать пейджинг, но около 15 минут, чтобы добраться до места. Затем вы берете 40 минут, чтобы устранить неполадки и решить проблему. Один час - это очень консервативно.
- Сервер компании возвращается в оперативный режим, и соединения восстанавливаются. Система протестирована и признана физически и логически пригодной.
Все снова кажется функциональным. На этот раз проблема была проста — простой сбой приложения, из-за которого служба останавливалась, а после перезапуска все было в порядке.
Теперь проблема со всем этим сценарием заключается в следующем: хотя это была настоящая катастрофа, она была также и простой. Системный инженер оказался рядом и смог довольно быстро диагностировать проблему. Даже лучше, проблема была простым решением. Эта простая проблема по-прежнему приводила к отключению общего приложения компаний как минимум на один час, и, если бы это был пиковый период времени, можно было бы потерять более 2 миллионов долларов. Хотели бы вы иметь такое высокодоступное решение, а? Сколько денег потребуется вашей компании, чтобы потерять, прежде чем вы оплатите увольнение, сотрудников и их обед в течение года, проявив инициативу? Не заблуждайтесь — высокая доступность основана на проактивном мышлении. Вы «планируете» катастрофу, поэтому вам не придется «реагировать» на нее, как только она произойдет.
Еще одна проблема, которая может возникнуть, — это потеря доверия клиентов или поставщиков к вашей компании. Компании, с которыми вы связываетесь и ведете бизнес, а также ваши собственные клиенты могут начать терять веру в вашу способность обслуживать их, если ваш веб-сайт недоступен или поврежден, ваша база данных повреждена, ваше приложение ERP недоступно и удерживает их. от ведения бизнеса. Это также может стоить вам дохода и возможности приобретения новых клиентов в будущем. Люди «разговаривают», и необразованные люди могут воспринять этот небольшой сбой как серьезную проблему с людьми вашей компании, а не с технологиями.
Давайте еще раз посмотрим на этот сценарий, но уже с использованием высокодоступного решения:
- Компания использует сервер для доступа к приложению, которое принимает заказы и выполняет транзакции.
- Приложение, когда оно запущено, обслуживает не только сотрудников отдела продаж, но и еще три компании, осуществляющие B2B-транзакции. По оценкам, в течение одного часа максимально заработанные деньги превысили 2,5 миллиона долларов.
- Сервер выходит из строя, но у вас есть высокодоступное решение. (Обратите внимание, на данном этапе не имеет значения, какое решение. Важно то, что вы добавили избыточность в службу.)
- Сервер и приложение избыточны, поэтому, когда происходит сбой, избыточность защищает приложение от сбоя.
- Клиенты не затронуты. Бизнес возобновляется в обычном режиме. Ничего не теряется и время простоя не накапливается.
- Один час, который вы сэкономили для своего бизнеса во время простоя, оплатил все внедренное вами высокодоступное решение.
Имея план, планирование упреждающего проектирования и использования избыточных и отказоустойчивых сервисов… может помочь вам предотвратить большинство аварий.
Управление вашими услугами
В этом разделе вы увидите все факторы, которые следует учитывать при разработке высокодоступного решения. К таким факторам относятся все основные области управления в вашей организации или отделе, созданные для помощи в планировании и обслуживании большинства ИТ-услуг, таких как высокая доступность. Эта одна область — управление неисправностями. Управление неисправностями — это одна из пяти категорий управления сетью, определенных ISO (Международной организацией по стандартизации). Управление сбоями гарантирует, что все сбои будут обнаружены, и запустит процесс записи, мониторинга и поддержки таких сбоев для корреляции. Управление сбоями включает в себя обнаружение сбоев, изоляцию и исправление ненормальной работы, а также включает функции для ведения и изучения журналов ошибок, принятия уведомлений об обнаружении ошибок и принятия соответствующих мер, отслеживания и идентификации сбоев, выполнения последовательностей диагностических тестов и исправления сбоев. Теперь, когда вы понимаете управление неисправностями, вы должны также понять и, по крайней мере, рассмотреть другие области модели управления сетью ISO. Модель управления сетью ISO содержит:
- Управление производительностью
- Управление конфигурацией
- Управление бухгалтерским учетом
- Управление неисправностями
- Управление безопасностью
Ниже приведен список основных служб, которые следует помнить и учитывать при планировании обеспечения высокой доступности.
- Управление изменениями имеет решающее значение для постоянного успеха решения на этапе производства. Этот тип управления используется для отслеживания и регистрации изменений в системе.
- Управление проблемами обращается к процессу для справочных служб и мониторинга сервера.
- Управление безопасностью призвано предотвратить несанкционированное проникновение в систему.
- Управление производительностью касается общей производительности службы, доступности и надежности.
Кроме того, не в модели ISO, но следует учитывать управление услугами. Управление услугами — это управление истинными компонентами высокодоступных решений: людьми, существующими процессами и технологиями, необходимыми для создания решения. Сохранение этого баланса для получения действительно жизнеспособного решения очень важно. Управление услугами включает этапы проектирования и развертывания. Управление услугами имеет решающее значение для разработки вашего высокодоступного решения. Вы должны удовлетворить требования вашего клиента в отношении времени безотказной работы. Если обещаешь, лучше сделай.
Идеи высокодоступной оценки системы
Ниже приведен список вопросов, которые следует учитывать на этапе планирования постпродакшна. Убедитесь, что вы охватили все свои базы этим списком:
- Теперь, когда вы настроили свое решение, задокументируйте его! Отсутствие документации наверняка обернется для вас катастрофой. Документировать не сложно, это просто утомительно, но вся эта работа окупится в конце концов, когда она вам понадобится. Документация спасает жизнь в случае бедствия.
- Обучите свой персонал. Убедитесь, что у ваших сотрудников есть доступ к тестовой лаборатории, книгам для чтения и курсам повышения квалификации. Посетите бесплатные семинары, чтобы узнать больше о High Availability. Если вы можете игнорировать коммерческие предложения, они весьма информативны.
- Проверьте свой персонал с помощью учений по реагированию на инциденты и сценариев стихийных бедствий. Письменные процедуры важны, но живые учения еще лучше, чтобы увидеть, как ваши сотрудники реагируют. Помните, что если у вас произошел сбой в системе, она может переключиться на другую систему, но вы должны быстро решить проблему на первой системе, в которой произошел сбой. У вас может быть такая же проблема на других узлах в вашем кластере, и если это так, у вас мало времени. Настройте сценарий и протестируйте его.
- Оцените текущий бизнес-климат, чтобы всегда знать, что ожидается от ваших систем. Планируйте будущую емкость, особенно по мере добавления новых приложений, а также по мере увеличения оборудования и трафика.
- Пересмотрите свои общие бизнес-цели и задачи. Убедитесь, что то, что вы собираетесь делать с вашим решением высокой доступности, предоставляется. Если вы хотите более быстрый доступ к системам, действительно ли это быстрее? Когда у вас возникает проблема, происходит ли аварийное переключение без проблем? Пострадают ли клиенты? Вы же не хотите внедрить решение высокой доступности и снизить производительность. Это не будет выглядеть хорошо для вас!
- Проведите анализ потока данных в соединениях, которые использует высокая доступность. Вы будете удивлены тем, что поврежденные сетевые карты, неправильные драйверы, избыточные протоколы, узкие места, несоответствие скоростей портов и дуплексный режим, и это лишь некоторые из проблем в системе. Я добился существенных изменений в сетях, просто проведя анализ потока данных в проводной сети, и благодаря этому анализу получил большие различия в скорости. Хорошим примером может быть, если у вас были старые сетевые карты на основе ISA, которые работали только со скоростью 10 Мбит/с. Если вы подключили свою систему к порту, который использует 100 Мбит/с, то вы будете работать только со скоростью 10, потому что это так быстро, как может работать сетевая карта. Что произойдет, если порт коммутатора будет настроен на 100 Мбит/с, а не на автоматическое согласование? Это создало бы проблему, поскольку сетевая карта не могла бы обмениваться данными по сети из-за несоответствия скоростей. Подобные проблемы распространены в сетях и вполне могут быть причиной плохого потока данных в вашей сети или его отсутствия.
- Контролируйте службы, которые вы считаете важными для работы, и следите за тем, чтобы они всегда работали. Никогда не думайте, что система будет работать безупречно, пока не будут внесены изменения... иногда системы задыхаются сами по себе либо из-за зависшего потока, либо из-за процесса. Вы можете использовать инструменты мониторинга сети, такие как GFI Network Server Monitor, для мониторинга таких служб.
- Оцените общую стоимость владения (TCO) и посмотрите, стоило ли оно того. Другими словами, в начале этой книги вы узнали, как решения высокой доступности могут сэкономить деньги для вашего бизнеса.
Итак, учитывая, что вы внедрили высокодоступные решения, сэкономили ли они деньги вашего бизнеса? Проведите окончательный анализ затрат, чтобы убедиться, что вы приняли правильное решение. Лучший способ определить совокупную стоимость владения — это воспользоваться онлайн-калькулятором совокупной стоимости владения, который покажет вам совокупную стоимость владения на основе вашей собственной уникальной бизнес-модели. Поскольку, по большей части, все бизнес-модели будут разными, лучший способ определить совокупную стоимость владения — запустить калькулятор и рассчитать совокупную стоимость владения на основе ваших личных ответов на вопросы калькулятора. В конце этой статьи есть ссылки на калькулятор TCO. Это должно дать вам хороший старт для расширенного планирования высокой доступности, и это дает вам много вещей для проверки и размышления, особенно когда вы закончите свою реализацию.
Тестирование системы высокой доступности
Теперь, когда у вас есть основы планирования и проектирования, давайте обсудим процесс тестирования ваших систем высокой доступности. Вы должны убедиться, что тест выполняется в течение достаточно долгого времени, чтобы вы могли получить надежную выборку того, как система работает нормально без нагрузки (или активности) и как она работает с активностью. Затем запустите тест достаточно долго, чтобы получить надежный базовый уровень, чтобы вы знали, как ваши системы работают в обычном режиме на ежедневной основе. Используйте это для сравнения во время активности.
Резюме
В этой статье были рассмотрены основы высокой доступности, высокодоступных систем, зачем они вам могут понадобиться и как они могут помочь вам свести к минимуму (или, вполне возможно, устранить) большую часть времени простоя системы, с которым вы можете столкнуться или можете столкнуться в будущем. Помните, что планирование высокой доступности — это всего лишь планирование и упреждающая работа, но при правильном его внедрении вы действительно можете помочь свести к минимуму сбои и проблемы, чтобы поддерживать бизнес в рабочем состоянии, как и должно быть. Дополнительные сведения о планировании высокодоступных систем и сетей см. в статье «Кластеризация и балансировка нагрузки Windows 2000 и Windows Server 2003» Роберта Дж. Шимонски. Вы также можете задавать автору вопросы по этой статье на форуме «Общие обсуждения» этого веб-сайта.
Справочник и ссылки
Международная организация по стандартизации
http://www.iso.org
Монитор сетевого сервера GFI
http://www.gfi.com/nsm/
Калькуляторы совокупной стоимости владения
http://www.microsoft.com/business/reducecosts/efficiency/consolidate/tco.mspx http://www.oracle.com/ip/std_infrastructure/cc/index.html?tcocalculator.html