Перекрестная проверка в машинном обучении
В машинном обучении мы не могли подогнать модель к обучающим данным и не можем сказать, что модель будет точно работать с реальными данными. Для этого мы должны убедиться, что наша модель получила правильные шаблоны из данных, и что она не поднимает слишком много шума. Для этого мы используем метод перекрестной проверки.
Перекрестная проверка
Перекрестная проверка - это метод, при котором мы обучаем нашу модель, используя подмножество набора данных, а затем оцениваем, используя дополнительное подмножество набора данных.
Перекрестная проверка включает три этапа:
- Зарезервируйте некоторую часть выборочного набора данных.
- Используя остальной набор данных, обучите модель.
- Протестируйте модель, используя резервную часть набора данных.
Методы перекрестной проверки
Проверка
В этом методе мы выполняем обучение на 50% заданного набора данных, а остальные 50% используются для целей тестирования. Основным недостатком этого метода является то, что мы выполняем обучение на 50% набора данных, возможно, что оставшиеся 50% данных содержат некоторую важную информацию, которую мы оставляем при обучении нашей модели, то есть более высокое смещение.
LOOCV (исключить перекрестную проверку)
В этом методе мы выполняем обучение для всего набора данных, но оставляем только одну точку данных из доступного набора данных, а затем выполняем итерацию для каждой точки данных. У него есть как достоинства, так и недостатки.
Преимущество использования этого метода заключается в том, что мы используем все точки данных, и, следовательно, это низкий уровень систематической ошибки.
Основным недостатком этого метода является то, что он приводит к большему разбросу модели тестирования, поскольку мы тестируем по одной точке данных. Если точка данных является выбросом, это может привести к большему разбросу. Еще один недостаток заключается в том, что на выполнение требуется много времени, поскольку он повторяет «количество точек данных» раз.
К-фолд перекрестная проверка
В этом методе мы разделяем набор данных на k подмножеств (известных как свертки), затем выполняем обучение на всех подмножествах, но оставляем одно (k-1) подмножество для оценки обученной модели. В этом методе мы выполняем итерацию k раз с различным подмножеством, зарезервированным каждый раз для целей тестирования.
Примечание: Всегда рекомендуется, чтобы значение k было 10 как меньшее значение. k требуется для проверки, а более высокое значение k приводит к методу LOOCV.
Пример
На диаграмме ниже показан пример обучающих подмножеств и подмножеств оценки, сгенерированных в k-кратной перекрестной проверке. Здесь у нас всего 25 экземпляров. В первой итерации мы используем первые 20 процентов данных для оценки, а оставшиеся 80 процентов для обучения ([1-5] тестирование и [5-25] обучение), а во второй итерации мы используем второе подмножество 20 процентов для оценка, а остальные три подмножества данных для обучения ([5-10] тестирование и [1-5 и 10-25] обучение) и т. д.
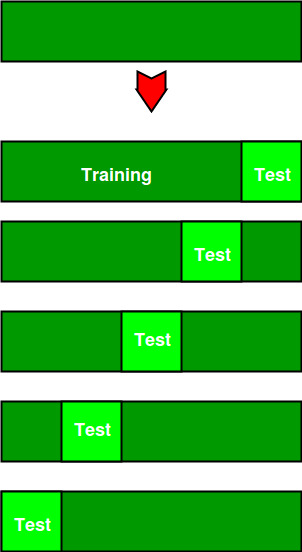
Всего экземпляров: 25 Значение k: 5 № Итерация Наблюдения за обучающей выборкой Наблюдения за тестовой установкой 1 [5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24] [0 1 2 3 4] 2 [0 1 2 3 4 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24] [5 6 7 8 9] 3 [0 1 2 3 4 5 6 7 8 9 15 16 17 18 19 20 21 22 23 24] [10 11 12 13 14] 4 [0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 20 21 22 23 24] [15 16 17 18 19] 5 [0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19] [20 21 22 23 24]
Сравнение разделения поездов / тестов с перекрестной проверкой
Преимущества сплита поезд / тест:
- Это выполняется в K раз быстрее, чем перекрестная проверка Leave One Out, потому что перекрестная проверка в K раз повторяет разделение поездов / тестов K раз.
- Проще изучить подробные результаты процесса тестирования.
Преимущества перекрестной проверки:
- Более точная оценка точности вне выборки.
- Более «эффективное» использование данных, поскольку каждое наблюдение используется как для обучения, так и для тестирования.
Код Python для k-кратной перекрестной проверки.
# This code may not be run on GFG IDE# as required packages are not found. # importing cross-validation from sklearn package.from sklearn import cross_validation # value of K is 10.data = cross_validation.KFold( len (train_set), n_folds = 10 , indices = False ) |
Ссылка: https://www.analyticsvidhya.com/blog/2015/11/improve-model-performance-cross-validation-in-python-r/